INFA的优化其实分为很多因素,包括网络、数据库、硬件配置、程序逻辑等等,但是我们能把控的有限,网络以及硬件都是不可改变了,有些硬件环境是没办法解决的,所以我们只能从个人操作上对程序进行优化。
现在将个人学习到的,以及在操作上领会到一些经验分享给大家。
首先我们知道无论是数据库的读取还是INFA的数据转换都有一个最大的极限,我们要优化就要了解他们的属性,以及熟悉他们的操作,才能合理的去优化。
首先说的就是我们读取的效率,这里“读取”包含了很多种,不仅仅限于读数据库,这里就涉及到了我们对于组件的使用熟练度,举个例子:
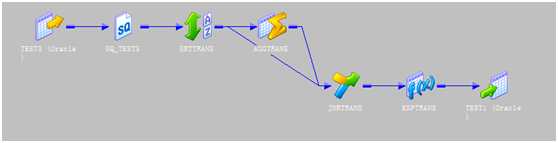
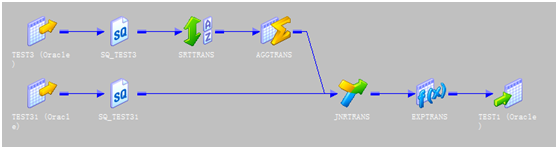
同样是两个程序,转换的结果是一样的,第一个ETL程序使用了自连接的转换,而按照正常开发步骤的话,第二个程序要读取两个相同的数据源表,这样在效率上就会降低,这也就是我前面说的,我们要提高读取效率,和转换效率。
另外像我们大家都熟知的,在进行计算、分组等操作时,需要提前进行数据的过滤操作,减少计算的数量,以提高我们ETL程序的效率,这也是在转换过程中时需要注意的。
其中还包含使用聚合组件之前首先使用排序组件,还有就是我们JOINER操作需要注意的,我们Master数据量尽量要少,也就是说尽量使用小表做Master。终于归纳总结就是我们需要熟练使用每个组件,了解每个组件的工作原理以及属性。这样我们在开发ETL程序时,才会合理使用每个组件,不去进行多余的操作。
