虽然没看到具体的方法案例,但值得思考和借鉴
话务员排班问题是呼叫中心中每天都会用到的问题,如何根据每个时间段的话务量来对话务员进行排班,既能够保证每个时间段的接通率达到最大,又能够协调好话务人员的休息和工作时间,保证每个话务人员的总工时大致相等。因此,话务员排班问题需要考虑许多的约束条件,在没有这个算法之前,该本地网是采用手工排班的方式来对话务员进行排班的,该本地网共有四个班制:班制1、班制2、班制3、班制4四个班制。并且每个班制下面又有若干个班次。每个班次的上班时间不同。并且每个班制内部是可以调整的,即一名话务员只能在本班制内的班次之间调岗,而不能调到其他的班制中。如何对话务员进行排班呢?
利用遗传算法对话务员进行排班的关键步骤如下:
1、编码机制。可以对每个人进行编码。如果总人数为60人的话,一条染色体的长度即为60*n。其中n为二进制编码长度。这里可以采用两种编码方式:二进制编码和全排列编码。其中二进制编码是采用二进制的方式进行编码,将二进制转化为十进制的数字即为该话务员所属的班次代号。如班制1有6个班次,其班次可以用1-6的数字来表示。全排列编码则直接利用班次代码进行标示。由于四个班制中班次的数量不同,如班制2有6个班次;早晚班有5个班次;班制3有3个班次;班制4有4个班次。每个班制中都有20名话务员,则编码的总长度为80。但行政班的20名话务员的班次代码是从1-6的整数。而早晚班中的20个人只能取1-5之间的整数。
2.交叉运算。交叉只能是在班制之间进行交叉。规则同基本遗传算法。
3.变异运算。变异运算采用取模并在结果+1的方式。如某个行政班的话务员的编码为3.对其进行变异则按照3对6(该班制下的班次总数)去摸并且+1,变异后则为4.
4.适应值的选择。适应值可以采用实际话务量的曲线与排班后所能处理的话务量两条曲线的拟合情况。可以采用欧式距离和拟合优度指标来度量。
经过这样的设计就能够得到最优的排班规则了。嘿嘿。排出来的对比图如下:
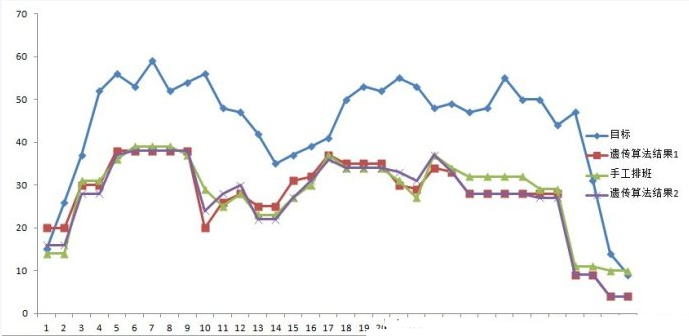
可以看到曲线的拟合情况比较好。
