1 ETL开发原则
ETL的开发目前使用IBM的Datastage Designer工具,在开发人员的客户机上这客户端工具进行开发,不允许使用远程登录到服务器的方法进行开发,ETL的开发原则涉及很多方面,本文档根据DataStage的对象的分类,从大到小分Project、Job、Stage等几块来描述:
1.1 ETL使用的数据库账号系统权限要求
ETL涉及源系统和目标系统,当采用并行JOB开发时,会对数据库账号的系统权限有一定的要求,根据Datastage文档要求,对Oracle账号至少需要以下系统权限:
– DBA_EXTENTS
– DBA_DATA_FILES
– DBA_TAB_PARTITONS
– DBA_TAB_SUBPARTITONS
– DBA_OBJECTS
– ALL_PART_INDEXES
– ALL_PART_TABLES
– ALL_INDEXES
– SYS.GV_$INSTANCE (Only if Oracle Parallel Server is used)
1.2 Project建立原则及必备内容
Project是存放DataStage中Job、Routine等对象的地方,一个应用可能拥有多个Project。原则上来讲,一个Project与一个目标系统对应,这样便于统一管理加载该目标的所有Job,但考虑到服务器性能及Job的总数等特殊情况,在某些情况下针对一个目标系统加载的job也可以拆分成多个Project。
为了便于统一管理,每个Project中必需具备以下内容:
1.2.1 DayOpen & DayOff
每个Project中都应该有一套DayOpen job和一套DayOff job,常见的是IShDayOpen调用了IMaDayOpen,IShDayOff调用了IMaDayOff job。DayOpen的运行标志了一天Job的开始,主要的任务是做一些初始化的操作,比如:创建当天的rundate目录、生成.ok文件、修改.cfg中的参数等等。DayOff的运行则代表了一天Job的结束,主要的任务事做一些清理工作,比如:删除已经不需要的rundate目录、删除.ok文件、清除ETL Log数据库中的标记位记录等。
1.2.2 Check & Mail功能
每个Project中还需要具备一个job用于检查当天job的运行状况,并发送mail给维护人员。
1.2.3 ETL Log
和Check功能类似,ETL Log也有一套job用于检查当天job的运行状况,不过统计的更为细致,会针对每个Job Sequence统计出成功、出错、警告的数量,并且将检查结果写入指定的数据库中。
1.3 Job开发原则
Sh、Gc、Ge属于包含代码的job,而没有具体的stage在job中,这类job主要是读取、传递参数给Se、Ex、Tr、Ld等job,各个应用可以根据实际需要添加些辅助的代码,不做强行的规定。开发原则主要针对包含有具体stage的Se、Ex、Tr、Ld等job。
1.3.1 Se Job
Se job是job sequence,用于调度Gc、Ge job,开发Se job需要注意以下几点:
(1) Se中需加入对DayOpenrundate.ok的依赖,以确保当某天的DayOpen Job停止时,所有后续Job都不会运行。
(2) 使用Job Activity Stage调用job时,Execution action选项应该选成“Reset if required, then run”,而不是缺省的“Run”。
(3) 使用Job Activity Stage时,Triggers中的Expression Type选项可以根据需要选择,没有特殊处理需要时应选成OK。
1.3.2 Ex Job
Ex job从源系统中抽取数据,一个Ex Job与源系统中对象一一对应,可以是数据库中的表、SAP中的表或BAPI、平面文件、XML文件等。
开发Ex job需要注意以下几点:
(1) 对数据量大的数据对象,尽量使用增量抽取来替代全量抽取。
(2) 生成的EXF文件尽量保持源系统的原貌,在有必要的情况下也可以对源系统的几张表进行关联。
(3) 一般来说一个EX Job只生成一个EXF文件,在某些情况下可以生成一个Hash文件以供后面多个Tr Job调用。
(4) 对于没有任何逻辑的抽取类JOB,不需要使用Transfomer Stage.
(5) 建议使用transformer Stage,并添加拒绝文件,用于将脏数据过滤出来。
1.3.3 Tr Job
Tr job实现了ETL过程中绝大部份逻辑,是最复杂的一类Job,由于逻辑复杂,实现方式可能是多种多样的,但还是有一些基本的原则是可以遵循的,开发Tr job需要注意以下几点:
(1) 一个Tr job可以处理多个EXF文件,但原则上只生成一个PLF文件。
(2) Tr job中常常需要用到lookup功能。当被lookup数据量较小时采用Hash文件lookup方式;当被lookup数据量较大,但主数据比较小时,则使用数据库lookup方式。
(3) 当使用Aggregator Stage时,需要在前面增加一个Sort Stage,先根据汇总的键值先进行排序,避免由于数据量太大而造成的报错。
(4) 并行JOB中,tr JOB中STAGE的数量尽可能小于20,超过20个STAGE,考虑分解成两个JOB依次调用。命名上可在JOB名后加序号加以区分。
1.3.4 Ld Job
Ld job负责把PLF文件加载到目标系统(由于大部份的目标系统是数据库,所以开发原则主要针对加载数据库),虽然逻辑上比较简单,但还是有些需要注意的地方:
(1) 每个Ld job都需要有REJ文件来处理异常数据的情况。
(2) 在数据库的Stage中可以对目标表进行创建删除的操作,但ETL过程中应该尽量避免对数据库模型的修改,所以应该禁用那些选项。
(3) 对大数据量的表尽量使用Truncate方式来替代Delete方式,以提高性能。
1.4 Stage使用原则
在DataStage的Job中会使用到各种各样的Stage,在本文档中针对一些常用的Stage制定出一些使用原则以使Job更易读,也可以避免一些不必要的错误。
1.4.1 Sequential File Stage
Sequential File Stage的功能是从平面文件中读写数据,EXF和PLF文件都是以Sequential File形式存在的,是最重要的Stage之一,使用Sequential File Stage时应遵守以下几项原则:
(1) 对于一个Sequential File Stage,可以有多个输出Link,但只能有一个输入Link;
(2) 一个Sequential File Stage上的所有输入输出的File name应该相同;
(3) 生成EXF、PLF等文件时,如没有特殊情况,则Format属性中选项应该如下:
(4) 由于ETL Server是安装在UNIX上的,所以如无特殊要求,则生成Sequential文件时应选择UNIX格式。
1.4.2 Hashed File Stage
Hashed File Stage主要用于实现lookup功能,使用Hashed File Stage时应遵守以下几项原则:
(1) Inputs和Outputs属性页中的File name必须一致。
(2) Inputs和Outputs的Columns也必须一致,特别注意主键一定要选择成lookup所需的键
(3) 如无特殊情况,Inputs中的选项应该如下:
1.4.3 Aggregator Stage
对Server JOB,Aggregator用于进行数据的汇总,类似于数据库中的Group功能,使用较为简单,但要注意的是在Aggregator Stage前需要加上一个Sort Stage来对汇总的键值进行排序,并在Aggregator Stage的Input中进行说明,如下图:
2 ETL命名规范
命名规范根据ETL过程中所处理的对象种类可以分为以下几种,DataStage中的对象、文件、其他系统中对象(ABAP、store procedure等)。
2.1 DataStage对象命名规范
2.1.1 Job的命名规范
Job命名采用以下格式
ETLType_JobType_[ObjectType]_SystemName_ObjectName[sequence]
说明:
ETLType用于标识ETL过程的分类,其取值为:
ETLType 说明
I 日常数据加载程序(Incremental)
N 初始加载程序(Initial)
H 历史加载程序(History)
JobType用于标识Job的类型,其取值为:
JobType 说明
Ex 抽取程序(Extract)
Tr 转换程序(Transform)
Ld 加载程序(Load)
Ma 维护程序(Maintance)
Gc 结果为EXF的JobGroup,一个Gc Job调用Ex Job对应生成一个EXF文件
Ge 结果为数据库表的JobGroup,一个Ge Job调用Tr及Ld Job对应完成转换加载一个数据库表
Sh 用于定义Schedule的Control Job,Sh Job不允许Abort
Se 用于定义作业执行顺序的作业,通过Se Job设置Gc及Ge Job的运行依赖关系
ObjectType用于标识一些特殊的抽取对象类型,而像数据库中的表之类普通对象则不需特别说明,目前可能的取值如下:
ObjectType 说明
BAPI SAP中的BAPI程序
SP 数据库中的store procedure
FTP 调用FTP的命令
systemname为源或目标系统类型,其取值为(由于不同应用的系统类型不同,所以以下仅为示例)
Systemname 说明
AUTO SAP R/3源系统
APO SAP APO源系统
ODS ODS目标系统
EDW 数据仓库系统
DM 数据集市系统
HW 手工数据
2.1.2 Rountine的命名规范
Rountine的命名采用以下格式RTfunctionname。
说明:functionname为Routine的功能描述
2.1.3 Server Job Stage的命名规范
Stage 命名 DataStage Stages 说明
抽取 EX_source_tablename Abap_Ext_for_R3
BAPI_PACK_for_R3
Oraoci9i sourcetablename为抽取的源表名
转换 TR_(exf/plf)name_n Transformer (exf/plf)为转换的目标文件名,其中小数点以”_”代替. n表示一位的序号.
排序 SR_filename_n Sort Filename为要排序的源文件名,n表示一位的序号,其中小数点以”_”代替
合并 MG_targetfilename Merge Targetfilename为合并的目标文件名,其中小数点以”_”代替
加载 LD_target_tablename Oraoci9i Targettablename为要加载的目标表名
文本文件 SQ_filename Sequencial file Filename为要产生的文本文件名,其中小数点以”_”代替
Hash文件 HS_filename Hash Filename为hash文件的文件名,其中小数点以”_”代替
文件合并 CP_filename Link Collector Filename为合并后文件名,其中小数点以”_”代替
行列变换 PV_source_tablename Pivot Sourcetablename为要变换的源表名
文件夹 FD_foldername Folder foldername为目录名
2.1.4 Server Job Stage的命名规范
Stage 命名 DataStage Stages 说明
顺序序列 SEnn Sequencer nn为两位数字,从01开始
作业 JB_jobname JobActivity Jobname为job的名称
文件等待 WF_filename WaitingForFile filename为文件的名称
DOS命令 CMD_description ExecuteCommand description为命令说明
2.2 文件命名规范
ETL过程中所处理的文件可以分为数据文件、临时文件和其他文件
2.2.1 数据文件的命名规范
数据文件为存放业务数据的文件,其格式如下:
SystemName_ObjectName[sequence].ExtName
说明:SystemName为源系统类型,其取值为
Systemname 说明
AUTO SAP R/3源系统
APO SAP APO源系统
ODS ODS目标系统
EDW 数据仓库系统
DM 数据集市系统
HW 手工数据
ObjectName为源系统或目标系统中的对象名称,可以是表或文件等
ExtName为中间文件的类型,其取值为
Extname 说明
EXF EXF文件
PLF PLF文件
2.2.2 临时文件的命名规范
格式:sourcefile.[Filetype][sequence]
说明:sourcefile为源文件,产生本文件的源文件
filetype为临时文件的类型,只有与中间文件的类型不同时使用,其取值为:
Filetype 说明
HSF Hash文件
TMP Temp文件
2.2.3 BAPI参数文件的命名规范
格式:method.PARA
说明:method为BAPI程序的method
3 JOB之间的依赖
JOB间的依赖关系通过使用在每个Schema添加一张状态表来实现:
表名:TL_ETL_TABLE_STATUS
表结构如下:
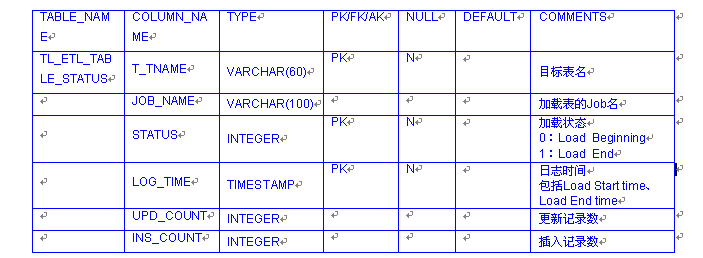
每张表的加载对应唯一一个JOB,这张表记录表加载过程,并保留历史,每一次成功的加载过程,对应表中状态为0和1的两条记录。
Ld JOB运行前插入状态为0的记录,加载完成插入状态为1的记录。
这张表可以反映如下信息:
JOB运行过程
加载耗时
加载状态
重处理情况
更新和插入数据量
4 JOB注释
JOB注释分为JOB级别注释和Stage级别注释两种
JOB级别注释使用Description Annotation Stage,使用Short Description描述JOB的功用,要求每个JOB都必须填写。Control JOB除要求JOB级别的注释外,还要求在代码中添加必要的注释。JOB级别的注释可以很方便地在director中查看到。
Stage级别的注释使用Annotation Stage描述有复杂处理逻辑的Stage的功能,对于没有任何特殊处理逻辑的STAGE可以不用添加注释,Stage级别的注释可以在打开JOB后不需要打开每一个STAGE的属性就可以大致了解Stage实现的功能。
由于JOB通过Version Control上传,JOB的版本信息、日期、以及Comments会自动填写到JOB级别的Full Description里,因此要求开发人员在上传JOB时如实填写JOB上传目的及上传人的信息。
5 JOB开发应遵循的原则
1. JOB的处理和重处理应尽可能减少对源系统的重复抽取
2. JOB的可能出错信息应维护在一张详细的列表中
3. 对使用并行JOB开发,需自定义环境变量如下:
APT_IMPEXP_ALLOW_ZERO_LENGTH_FIXED_NULL,将其设为String型,Value=1
4. 用Transform Stage进行处理。由于Transform Stage不能对Null值进行运算,所以需先用IsNull函数判断字段是否为空,然后对非Null值进行运算,对Null值直接赋值。若不进行非空判断,Transform将reject掉含Null值的记录。
5. 用Aggregator Stage进行集合运算。此时,不需要判断NULL值,可直接进行运算。Aggregator Stage运算时,NULL值的存在不会影响到结果集。如:在做Sum时,NULL值被认为是0;在取minimum value时,NULL值被忽略,取到的最小值为非NULL值中的最小值。
6 文档下载
