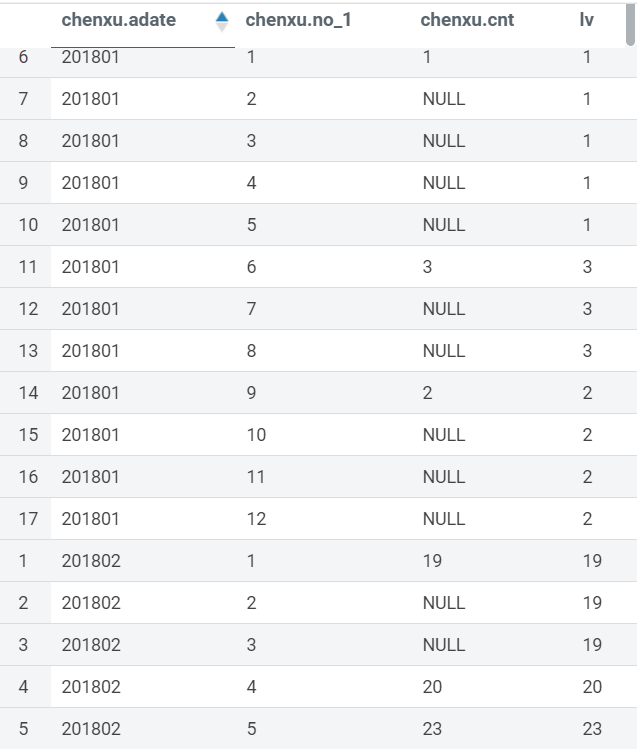
需求
获取同一月内上一条不为空的数据(按照序号排序),如下图
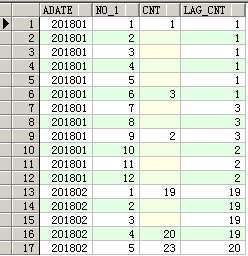
样例数据
with chenxu(adate,no_1,cnt) as
(
select 201801,1,1 from dual union all
select 201801,2,null from dual union all
select 201801,3,null from dual union all
select 201801,4,null from dual union all
select 201801,5,null from dual union all
select 201801,6,3 from dual union all
select 201801,7,null from dual union all
select 201801,8,null from dual union all
select 201801,9,2 from dual union all
select 201801,10,null from dual union all
select 201801,11,null from dual union all
select 201801,12,null from dual union all
select 201802,1,19 from dual union all
select 201802,2,null from dual union all
select 201802,3,null from dual union all
select 201802,4,20 from dual union all
select 201802,5,23 from dual
)
select * from chenxu
方案一
如果在Oracle 11gR2版本下可以直接使用lag over函数中的ignore nulls
with chenxu(adate,no_1,cnt) as
(
select 201801,1,1 from dual union all
select 201801,2,null from dual union all
select 201801,3,null from dual union all
select 201801,4,null from dual union all
select 201801,5,null from dual union all
select 201801,6,3 from dual union all
select 201801,7,null from dual union all
select 201801,8,null from dual union all
select 201801,9,2 from dual union all
select 201801,10,null from dual union all
select 201801,11,null from dual union all
select 201801,12,null from dual union all
select 201802,1,19 from dual union all
select 201802,2,null from dual union all
select 201802,3,null from dual union all
select 201802,4,20 from dual union all
select 201802,5,23 from dual
)
select t.*,nvl(lag(cnt ignore nulls) over(partition by adate order by no_1),cnt) lag_cnt
from chenxu t
但是像PG、GP、Hive等数据库,他们的分析函数里并没有集成进来ignore nulls的功能,则可以多套两层来解决
方案二
不等值关联,再分组筛选得出(会发散)
with chenxu(adate,no_1,cnt) as
(
select 201801,1,1 from dual union all
select 201801,2,null from dual union all
select 201801,3,null from dual union all
select 201801,4,null from dual union all
select 201801,5,null from dual union all
select 201801,6,3 from dual union all
select 201801,7,null from dual union all
select 201801,8,null from dual union all
select 201801,9,2 from dual union all
select 201801,10,null from dual union all
select 201801,11,null from dual union all
select 201801,12,null from dual union all
select 201802,1,19 from dual union all
select 201802,2,null from dual union all
select 201802,3,null from dual union all
select 201802,4,20 from dual union all
select 201802,5,23 from dual
)
,tmp as (
select t.*,case when t.cnt is null then t2.cnt else t.cnt end as lag_cnt, t2.no_1 t2_no
from chenxu t,
(select * from chenxu where cnt is not null) t2
where t.adate = t2.adate
and t.no_1 >= t2.no_1
)
select adate,no_1,cnt,nvl(lag(lag_cnt) over(partition by adate order by no_1) ,cnt)
from (
select adate,no_1,cnt,lag_cnt from (
select t.*,row_number() over(partition by adate,no_1,cnt order by t2_no desc) rn from tmp t
)
where rn = 1
);
方案三
标定范围,关联得出结果(不会发散)
with chenxu(adate,no_1,cnt) as
(
select 201801,1,1 from dual union all
select 201801,2,null from dual union all
select 201801,3,null from dual union all
select 201801,4,null from dual union all
select 201801,5,null from dual union all
select 201801,6,3 from dual union all
select 201801,7,null from dual union all
select 201801,8,null from dual union all
select 201801,9,2 from dual union all
select 201801,10,null from dual union all
select 201801,11,null from dual union all
select 201801,12,null from dual union all
select 201802,1,19 from dual union all
select 201802,2,null from dual union all
select 201802,3,null from dual union all
select 201802,4,20 from dual union all
select 201802,5,23 from dual
)
,tmp as (
select a.adate,a.cnt ,no_1,
lead(a.no_1) over(partition by adate order by no_1) ld_no,max_no,lead_no
from (select t.*,max(no_1) over(partition by adate order by 1) as max_no,--获取当组最大,为当组最后一条空处理做准备
lead(no_1) over(partition by adate order by no_1) as lead_no --获取当组下一个
from chenxu t) a
where a.cnt is not null --过滤空行
)
select t.*,a.cnt as lag_ignore_null
from chenxu t
left join tmp a on a.adate = t.adate
and t.no_1 >= a.lead_no
and t.no_1 <= nvl(a.ld_no,a.max_no)
order by t.adate,t.no_1
;
方案四
若是在Hive中,可使用last_value+true实现
根据测试发现last_value和first_value不一样,last_value的默认窗口范围为 range between unbounded preceding and current row (上无边界 到 当前行)
LAST_VALUE
- This takes at most two parameters. The first parameter is the column for which you want the last value, the second (optional) parameter must be a boolean which is
false by default. If set to true it skips null values.
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
根据官网提示可得
with chenxu as
(
select 201801 adate,1 no_1,1 cnt union all
select 201801,2,null union all
select 201801,3,null union all
select 201801,4,null union all
select 201801,5,null union all
select 201801,6,3 union all
select 201801,7,null union all
select 201801,8,null union all
select 201801,9,2 union all
select 201801,10,null union all
select 201801,11,null union all
select 201801,12,null union all
select 201802,1,19 union all
select 201802,2,null union all
select 201802,3,null union all
select 201802,4,20 union all
select 201802,5,23
)
select *,
last_value(Cnt,true) over(partition by adate order by no_1) as lv
from chenxu
最后再套一层lag即可完成展现