如果我们有一个kafka-topic写了不同的数据,我们需要根据这个输入数据进行不同的处理逻辑,但是最终结果需要合并在一个流里面,那么这个时候即可用这么一波操作。
1、使用split方法进行数据分流,把分流信息存到新建的OutputSelector对象里面
2、调用split stream的select方法把 split stream 转成 data stream
3、调用data stream的union方法进行流合并,你可以输入多个data stream
按照这几个步骤基本就完成了流的拆分和合并,每个单独的流你可以自定义自己的operator
package flink;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
/**
* @author luyufeng
* @date 2019-01-23 11:04
* @description ……
*/
public class SplitUnionCount {
public static void main(String[] args) throws Exception {
final ParameterTool params = ParameterTool.fromArgs(args);
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream text;
//判断输入文件,否则直接获取words类的内容
if(params.has("input")){
text = env.readTextFile(params.get("input"));
}else {
text = env.fromElements(WordsData.WORDS);
}
SplitStream<Tuple2<String,Integer>> split = text.flatMap(new FlatMapFunction<String,Tuple2<String,Integer>>() {
@Override
public void flatMap(String s, Collector<Tuple2<String,Integer>> collector) throws Exception {
//按照单词进行分割
String [] words = s.split("\\W+");
for(String word:words){
collector.collect(new Tuple2<>(word,1));
}
}
}).split(new OutputSelector<Tuple2<String,Integer>>() {
@Override
public Iterable<String> select(Tuple2<String, Integer> values) {
//使用arraylist存储分流信息
List<String> output = new ArrayList<>();
//按照第一列单词是否包含the进行分组
if(values.f0.equals("the")){
output.add("a");
}else {
output.add("b");
}
return output;
}
});
//把分组a的split流转成data stream流
DataStream<Tuple2<String, Integer>> stream1= split.select("a").keyBy(0).sum(1);
//把分组b的split流转成data stream流
DataStream<Tuple2<String, Integer>> stream2 = split.select("b").keyBy(0).sum(1);
//union合并a、b两个数据流
DataStream<Tuple2<String, Integer>> stream = stream1.union(stream2).keyBy(0).sum(1);
if(params.has("output")){
stream.writeAsText(params.get("output"));
}else {
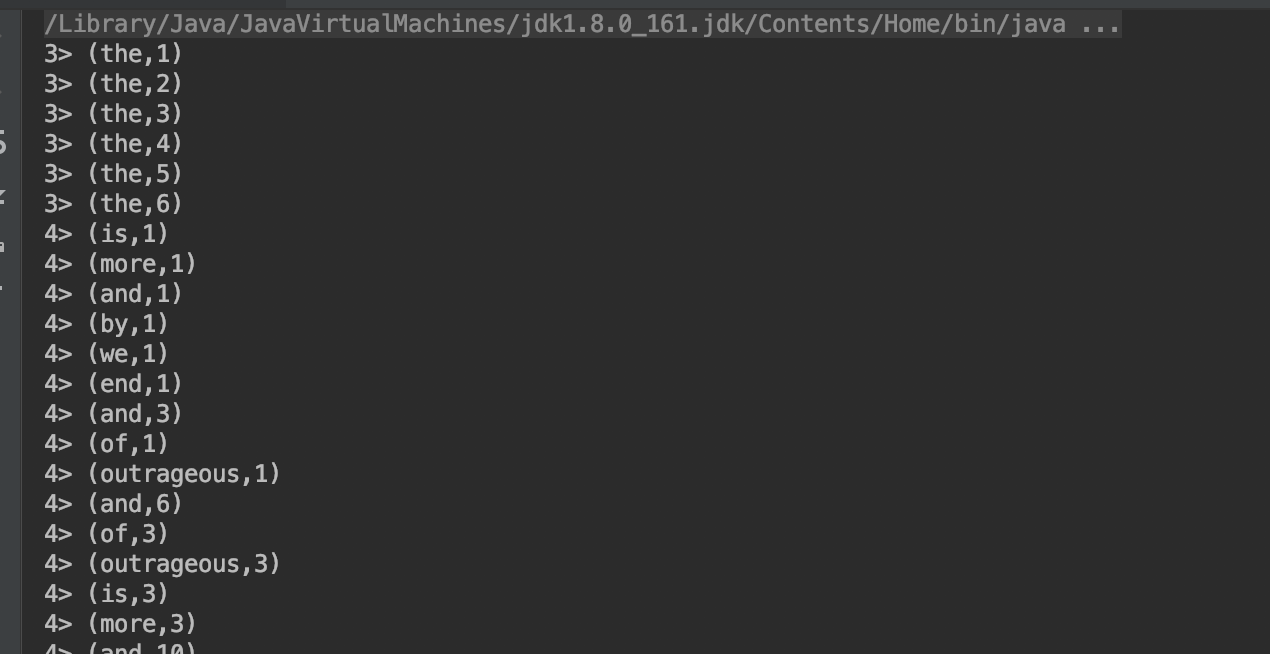
//输出包含the的统计
stream1.print();
//输出合并流之后的所有统计
stream.print();
}
env.execute("split union stream");
}
}
执行上面的代码,优先输出分流后stream1的数据,然后继续输出合并之后的stream数据