学了一些时间的机器学习,准备回顾下以前的机器学习,呢么首先从梯度下降算法看起。
梯度下降算法(上学的时候老师戏称为“下山法”),迎合那句话,人往高处走,水往地处流。目的是找到凸函数的最小点。
怎么做的呢。曲线和曲面都有切线,我们每步按照负梯度方向行走。好了,我们举个例子。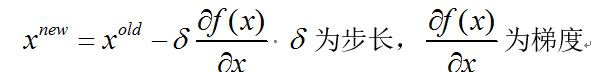 梯度下降的公式
梯度下降的公式
下面举个例子演示一下。


上面投机取巧了一些,我们把步长定为1,我们发现梯度下降算法来回震荡,但是我们的牛顿法很快就找到最低点了。但是牛顿法的弊端是,当我们求逆矩阵时,时间复杂度远远大于我们的梯度下降法。
代码实现一下(这里步长就令为0.1)
import matplotlib.pyplot as plt
import numpy as np
import time
time_start=time.time()
a=np.linspace(-1,3,1000)
b=a**2-2*a+3
plt.plot(a,b,'r')
####梯度下降算法
####首先看下我们的梯度值 梯度为2a-2 ,初始点为0,步长为0.1
###那么,我们的看下下降 a=a-0.1(2a-2)=0-0.1(0-2)=0.2 这个时候函数值是b=0.04-0.4+3=2.64 比开始的点下降了,原来是3,我们可以作图显示。
####现在就来构想我们的判别条件,如果我们每2次的函数值的查小于某个阈值,我们认为变化的不多,那么我们认为迭代停止
def hanshuzhi(x):
return x**2-2*x+3
def partial_x(x):
#计算x的偏导数
return 2*x-2
x_=[]
y_=[]
def main():
x=0
i=0
learning_rate = 0.1
print('初始', hanshuzhi(x))
x_.append(x)
y_.append(hanshuzhi(x))
while i < 100:
#步长0.001下降100步
x = x - learning_rate * partial_x(x)
print("梯度更新的值",x)
print('min',hanshuzhi(x))
x_.append(x)
y_.append(hanshuzhi(x))
i = i+1
main()
plt.plot(x_,y_,'b>')
plt.show()
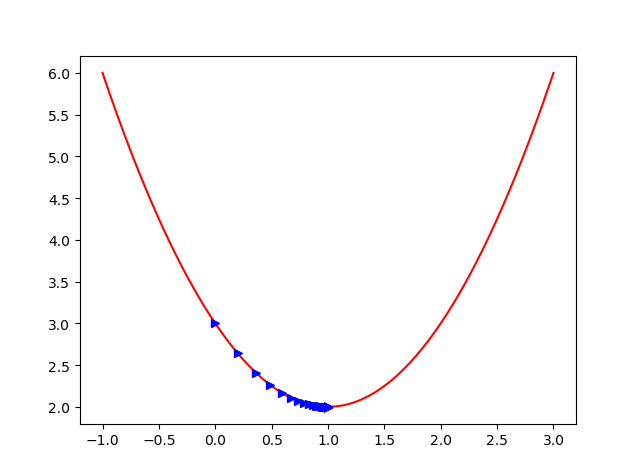
我们可以看到我们下降的结果,这个程序写的有点糟糕,我们可能不需要那么多的步数就能找到我们的最小值。所以优化了下:
import matplotlib.pyplot as plt
import numpy as np
import time
time_start=time.time()
a=np.linspace(-1,3,1000)
b=a**2-2*a+3
plt.plot(a,b,'r')
def hanshuzhi(x):
return x**2-2*x+3
def partial_x(x):
#计算x的偏导数
return 2*x-2
x_=[]
y_=[]
def bgd_rosenbrock():
x=0
i=0
learning_rate = 0.1
print('初始', hanshuzhi(x))
x_.append(x)
y_.append(hanshuzhi(x))
while(1):
t1=hanshuzhi(x)
x = x - learning_rate * partial_x(x)
print("梯度更新的值",x)
t2=hanshuzhi(x)
x_.append(x)
y_.append(t2)
print('min',t2)
if(t1-t2<0.00001):
break
bgd_rosenbrock()
time_end=time.time()
print('time cost',time_end-time_start,'s')
plt.plot(x_,y_,'b>')
plt.show()
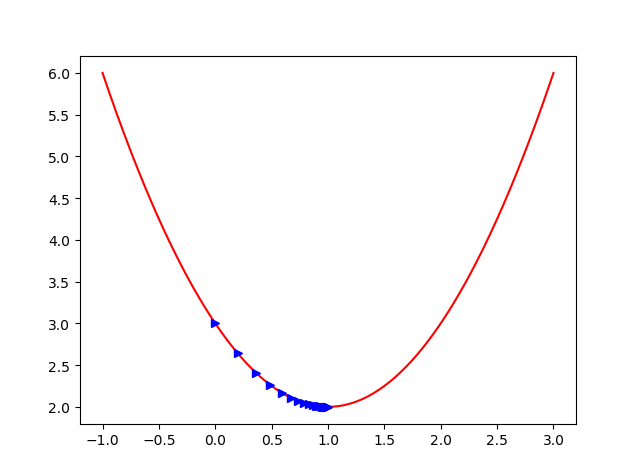
那如果是牛顿法实现呢
import matplotlib.pyplot as plt
import numpy as np
import time
time_start=time.time()
a=np.linspace(-1,3,1000)
b=a**2-2*a+3
plt.plot(a,b,'r')
def hanshuzhi(x):
return x**2-2*x+3
def niudun_x(x):
#计算x的偏导数
return x-1
x_=[]
y_=[]
def bgd_rosenbrock():
x=0
i=0
learning_rate =0.1
print('初始', hanshuzhi(x))
x_.append(x)
y_.append(hanshuzhi(x))
while(1):
t1=hanshuzhi(x)
x = x - learning_rate * niudun_x(x)
print("梯度更新的值",x)
t2=hanshuzhi(x)
x_.append(x)
y_.append(t2)
print('min',t2)
if(t1-t2<0.001):
break
bgd_rosenbrock()
time_end=time.time()
print('time cost',time_end-time_start,'s')
plt.plot(x_,y_,'b>')
plt.show()
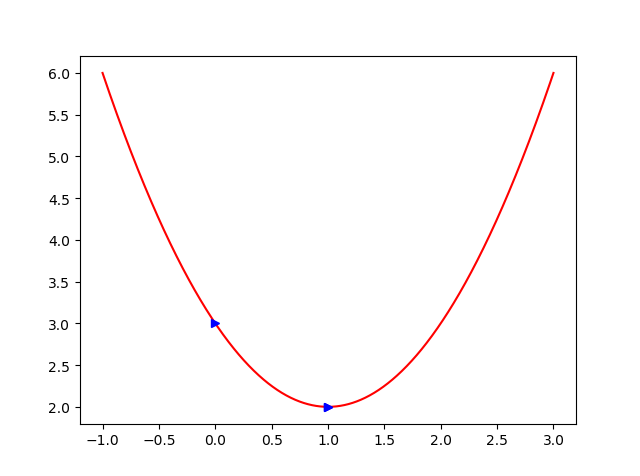
我们发现收敛的更好一些,但是当我们数据很多时候的,求逆矩阵,这个问题就是很不好的的问题。下次我们就回顾一些其他的常见的机器学习算法。
