作者: 张小鸡 Python爱好者社区专栏作者
知乎ID:https://www.zhihu.com/people/mr.ji
个人公众号:鸡仔说
这个时候,我感觉到后脊梁骨一阵发凉,果不其然。正在喝水的我,差点没被噎死。发来如下题目,就是说,如果我俩越默契,答案就越相似,题目是这样的:
请给以下唇色评分(5分制),评出你对每一个的喜好程度?

额?你给大直男,发这种测试,真的好吗?我这些是啥色都认不全,哪里知道选多少分哦?只能凭感觉蒙吧~
我以为把答案丢给他,然后她比对我的答案,看下我大概哪些题每答对就好了。好吧。我太小看女生心思了。她把这些测试都发了一份给她的闺蜜们,得出了10个人的得分,然后让我选择其中哪一个是她。大兄弟们,也就是说,如果选了她的一位闺蜜,那就危险了。
正好最近看了推荐系统的章节,发现这个和推荐系统的相似度计算很相似,首先咱们理一下数据的情况,咱们选项按照分数级来分1~5表示喜好程度。每一个人呢,我们就用字典的key形式给她做编号,比如第一个闺蜜(或女票)就是per_1。唇色就用编号lip_1,那么第一个人的数据类似于这样的
{ # 第一个人
"per_1": {
# 第10个唇色 : 3分,下同
"lip_10": 3,
"lip_9": 1,
"lip_8": 5,
"lip_1": 2,
"lip_3": 2,
"lip_2": 3,
"lip_5": 4,
"lip_4": 1,
"lip_7": 1,
"lip_6": 1
}}
这里核心就是,只要我们每一题和女票回答的尽可能相近就能够把最后相近度控制在最小。这里我们采用欧几里得公式来求解,别看这个名字挺唬人的,其实原理很简单。就是两点之间的距离计算。
给定两个点 P=(x, y) 和 Q=(z, t),定义距离
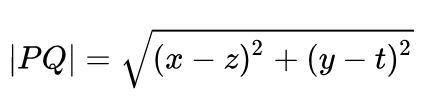

这样看公式不容易理解,没问题,看我的灵魂画图功底。如下,其实咱们就是要求这个d的距离,并且使它最小。
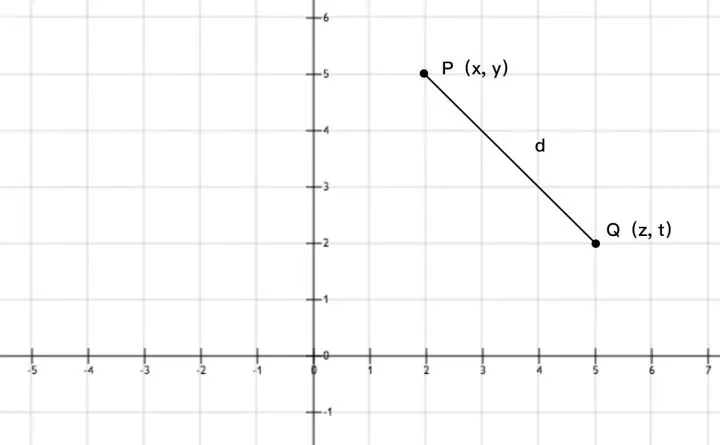
总共有10个唇色偏爱程度,我们只需要根据公式进行加和,最终使得距离值最小即可。
Don't bb, show me the code
def xzz_sim_distance(perfs, person1, person2):
''' 小祖宗相似度计算 :return 一个0~1之间的值,越大表示两人相似度越高 '''
# 判断如果两人存在共同爱好,跳出来计算两人之间的差值总和
# 判断如果两人不存在相同爱好,则返回0
for per_person1_like in perfs[person1]:
if per_person1_like in perfs[person2]:
break
else:
return 0
# 计算每一组差值的平方和
sum_squares_sim = sum([pow(perfs[person2][per_saw] - perfs[person1][per_saw], 2) for per_saw in perfs[person1] if per_saw in perfs[person2]])
# 避免因为两者完全相等时,分母为0;取导数时,则保证,数值越大,表明两者越相关,方便记忆。
return 1/(1 + sqrt(sum_squares_sim))
ok,咱们把自己对每一个唇色的喜好程度进行打分,将自己的打分结果与闺蜜们的数据一起打包,形成最终的数据perfs。然后调用 小祖宗相似度计算函数(xzz_sim_distance)看下结果如何。
for per_p in Lips_data:
# 不与自己进行比较
if per_p == 'per_0':
continue
print xzz_sim_distance(Lips_data, 'per_0', per_p), per_p
输出如下:
0.141187848064 per_10
0.179128784748 per_9
0.2 per_8
0.1336766024 per_5
0.2 per_4
0.205213096158 per_7
0.135078105936 per_6
0.139578756837 per_1
0.309016994375 per_3
0.150221104822 per_2
我们可以很容易的看出来,最大值是第三个人。虽然感觉得分还是很低,但是觉得自己推理是没毛病的,颤抖着的手把答案发了过去。
(╯‵□′)╯︵┻━┻ 还没完没了了。但是没办法,谁让她是小祖宗呢?我先审一下题,这次是她们公司的创意库,采集的作品,让我看下各种广告视频,并根据这些个创意进行喜好程度打分。这其实原理和之前一样嘛,也是计算相似度。
限于篇幅,其它案例就不放了,这次我本来想,我打完分继续按照之前的模式走一遍。后来又发现不对,因为我这个人吧,比较糙,打分一般比较宽松,我一看卧槽,拍这么好,一般一股脑就给高分,但是我俩的大体喜好是一样的。这个时候用欧几里得相似度计算就存在较大误差,所以这里介绍另外一套算法,皮尔逊相关系数,能够修正我这种比较糙的人。对于皮尔逊相关系数不太理解的,可以看下如下资料
如何理解皮尔逊相关系数(Pearson Correlation Coefficient)?
https://www.zhihu.com/question/19734616/answer/174098489
皮尔逊相关系数,如下是公式:
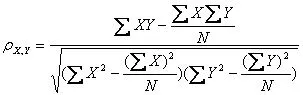
show me the code
def xzz_sim_person(perfs, p1, p2):
''' 小祖宗皮尔逊相关系数计算 :return 一个0~1之间的值,越大表示两人相似度越高 '''
# 构建共同数据集
common = {}
for per_p1 in perfs[p1]:
if per_p1 in perfs[p2]:
common[per_p1] = 1
# 得到数据集总数量
n = len(common)
# 没有共同兴趣爱好
if n == 0:
return 0
# 对所有偏好求和
sum1 = sum([perfs[p1][per_common] for per_common in common])
sum2 = sum([perfs[p2][per_common] for per_common in common])
# 求平方和
sq_sum1 = sum([pow(perfs[p1][per_common], 2) for per_common in common])
sq_sum2 = sum([pow(perfs[p2][per_common], 2) for per_common in common])
# 求乘积和
mul_sum = sum([perfs[p1][per_common] * perfs[p2][per_common] for per_common in common])
num = mul_sum - sum1*sum2/n
den = sqrt((sq_sum1 - pow(sum1, 2)/n)*(sq_sum2 - pow(sum2, 2)/n))
if den == 0:
return 0
r = num/den
return r
每写一个相似度匹配算法,咱们就得排序一下结果,看看谁分值较高,挺麻烦的,那就写一个通用的小祖宗最n临近人算法(名字瞎取的)方便复用:
def xzz_top_matches(prefs, person, n=5, similarity=xzz_sim_person):
''' 小祖宗最n临近人算法 寻找与自己最相近的n个人,并给出相似度评分 '''
scores = [(similarity(prefs, person, per_person), per_person) for per_person in prefs if per_person != person]
scores.sort()
scores.reverse()
return scores[0:n]
咱们来调用一下看看结果如何:
print xzz_top_matches(Videos_data, 'per_0', n=5, similarity=xzz_sim_person)
输出如下
[(0.520765483515341, 'per_32'),
(0.4597024642476977, 'per_29'),
(0.34642796561282824, 'per_21'),
(0.3054957597202306, 'per_33'),
(0.2796316410812393, 'per_10')]
激动地酱不出话,从50个人当中找出评分,一个个比对,我找出来,估计也到后年腊月了吧?颤抖着手把猜测结果发了过去。
好了,又来了,这次倒不是测试,是这样,她在网上找了一堆化妆品品牌的评测,每个牌子都有堆网友的综合评分,她自己对10种牌子有一个自己喜好,并做了评分,但想知道哪个人跟她的喜好相似,因此就可以根据相似人的喜好去买买买。
但是这里面有两个问题有bug
1. 不是每个人都对10个牌子有评价;
2. 有些人有个人好恶,就是说某些品牌可能总体评价不好,但某个人就是钟爱她,这就会造成推荐偏差。
这又要怎么解决呢?easy,咱们可以通过加权计算
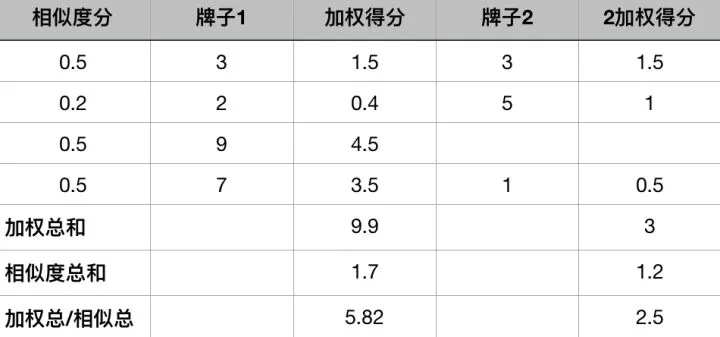
我们先计算每个人的相似度,然后看她们对于每一个牌子的评分,与我们的相似度相乘,得到加权后的得分,再和相似度总和相除,便可以得到最后的得分。这就可以避免诸如牌子2有一项没有被该用户评分的情况。
上代码:
def xzz_get_recommendations(perfs, person, similarity=xzz_sim_person):
""" 小祖宗物品推荐算法 基于相似度评分,进行加权计算,进行推荐建议 """
sim_rew_sum = {}
sim_sum = {}
for per_person in perfs:
# 不与自己比较
if per_person == person:
continue
similar = similarity(perfs, person, per_person)
# 忽略总分小于0的情况
if similar <= 0:
continue
for per_item in perfs[per_person]:
# 只对自己没了解过的牌子进行评价
if per_item not in perfs[person] or perfs[person][per_item] == 0:
# 相似度*评价值之和
sim_rew_sum.setdefault(per_item, 0)
sim_rew_sum[per_item] += perfs[per_person][per_item] * similar
# 相似度之和
sim_sum.setdefault(per_item, 0)
sim_sum[per_item] += similar
ranks = [(sim_rew_sum[item]/sim_sum[item], item) for item in sim_rew_sum]
ranks.sort()
ranks.reverse()
return ranks
这里再将品牌数据传到其中即可,再将数据集传入其中即可,结果可喜可贺。可是今晚依然没有约会~至此,我的假女朋友也可以退下了。

anyway,做一个简单总结:
相似度计算可以通过欧几里得或者皮尔逊相关系数等算法。得分越高越匹配
皮尔逊相关系数能够修正某一个人出分普遍比另一个人高的情况
推荐物品时,为了消除个人特殊癖好,或者未打分的情况,可通过加权计算进行修正
特别说明:
本节相关知识点参考书籍《集体智慧编程》
故事纯属虚构,如有雷同,你抄我的
相关代码
请访问我的GitHub, 欢迎star或follow
地址戳阅读原文
Python的爱好者社区历史文章大合集:
Python的爱好者社区历史文章列表
 福利:文末扫码关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“ 课程 ”即可获取:
小编的转行入职数据科学(数据分析挖掘/机器学习方向)【最新免费】
小编的Python的入门免费视频课程!
小编的Python的快速上手matplotlib可视化库!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告扩展制作免费学习视频。
玩转大数据分析!Spark2.X + Python精华实战课程免费学习视频。

