1、分布式环境搭建
采用4台安装Linux环境的机器来构建一个小规模的分布式集群。
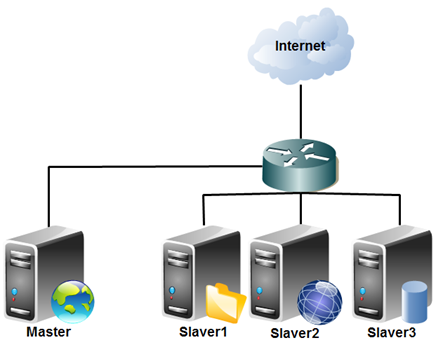
图1 集群的架构
其中有一台机器是Master节点,即名称节点,另外三台是Slaver节点,即数据节点。这四台机器彼此间通过路由器相连,从而实验相互通信以及数据传输。它们都可以通过路由器访问Internet,实验网页文档的采集。
2、集群机器详细信息
2.1 Master服务器

2.2 Slave1服务器

2.3 Slave2服务器

2.4 Slave3服务器

备注:
添加新用户命令:useradd;修改新用户密码:passwd 用户名
退出当前用户:exit; 登录root用户:su –
3、集群机器实际布局
下面是几张Hadoop集群实际机器的部署情况,可以从图中看到那时的我们怎么实际配置Hadoop集群的。
3.1 Hadoop工作集群
该Hadoop集群机器是学习和研究之用,上面运行着已经搭建好的的Hadoop平台以及运行着一些实际程序。

图3.1-1 Hadoop工作集群部署图(1)

图3.1-2 Hadoop工作集群部署图(2)
上面从两个角度来分别观察Hadoop集群部署,作为Hadoop集群的Master节点,用的是机器较为不错的新Dell,而三台Slave机器则是实验室淘汰的旧Lenovo,用一个小路由器他们组成了一个局域网。

图3.1-3 路由器特写
3.2 Hadoop实验集群
为了方便新成员练习Hadoop技术,又防止在实际Hadoop集群上破坏已运行的程序,故另外弄了两台旧Lenovo电脑组成:一个"主——TMaster";一个"辅——TSlave"。

图3.2-1 Hadoop实验集群部署
上面就是实验室Hadoop集群的样子,虽然很简陋,但足够学习用了。
4 文档下载
