笔者最近利用决策树对贷前风控的策略进行调整和优化,因为目前的任务是降低资损,所以对好用户的误杀高一点是可以容忍的,但是任然想在降低误杀的前提下提升识别坏用户的水平,今儿得空,将有关的东西整理一下。
整理的流程是:决策树简介--->数据整理---->决策树建模---->查看规则效果---->搭建规则----->规则上线
为什么要先将决策树放最前讲呢?因为笔者认为不同的模型算法对数据方面的要求是不一样的,所以最好是在了解了算法对数据的要求的前提下再去清洗整理数据会更有效果一些
1.决策树
决策树之所以能成为常用的建模工具,从使用经历来看,有以下几点吧:
A.生成的结果易于解释,在实际工作中容易部署,尤其是对于金融风控来讲,在什么变量的什么阈值下的用户该被拒绝或通过,这个很依赖if-then这种判断
B.能有效处理各类数据,例如稀疏的,偏态的,连续的,类别的,缺失值,很少需要对变量的值进行什么标准化啊,类别转数值啊
C.可以对变量重要性进行评估,有时候可以当做特征选择的手段来使用
但是也有一些缺陷,而这些缺陷决定了我们的数据处理过程:
A.当预测变量彼此高度相关时,那么选择哪个变量作为切分点有很大几率是随机的,会导致彼此相关的变量间一些微小的变动会导致随机选择不同的变量作为切分点,结果可能会得到一组完全不同的划分,即模型的方差很大,出来的规则策略不稳定,且会选择比实际需要更多的变量,虽然集成方法能够解决这个问题,但是
集成方法的解释性不好,目前笔者的水平还没发现可以用在金融风控策略方面的,如果有大佬知道还请答答疑。针对这块,可以对预测变量查看两两相关性,相关性大的选择数据质量较好的,且业务上更有解释性的变量
B.便宜没好货虽然不是绝对的,但是基本上是这样的,而决策树因为有良好的解释性且易于计算会使得单棵决策树较其他模型而言一般具有次优的预测能力。原因在于树模型会将数据划分为若干矩形的区域,如果预测变量和结果变量之间的关系并不能由矩形来刻画,那么树的预测能力就不是最优的
C.决策树还具有选择偏差:具有很多不同取值的预测变量通常比取值较离散的变量更容易出现在模型中,且缺失值越多,变量选择会更有有偏。针对这个问题,笔者想到的办法是尽可能的减少变量的缺失值,并用变量的WOE值来代替原始数值,或者尽可能选择值较为集中的变量
通过对决策树的优缺点进行进行梳理,得到我们的数据处理过程
2.数据处理
2.1查看数据分布
对于风控策略来讲,假定坏用户永远是少数,那么好的数据分布应该是比较集中的,异常值是较少的,所以在处理数据之前可以看看各个白能量的数据分布
library(readxl)
library(data.table)
Sys.setlocale(category = "LC_ALL", locale = "zh_cn.utf-8") #mac系统对于中文在R中的支持
origin_data <- read_excel('数据.xlsx',sheet = 'Sheet1')
study_data <- data.table(origin_data)
sd <- study_data[,.SD,.SDcols=-c(1,3,4,5)] #将没有业务含义的数据剔除
我们可以构建一个自定义函数,对于数值型数据用直方图来和密度图来展示,类别型数据用条形图来展示
plots(sd,save = TRUE) #save代表将图保存到本地
这里只挑选两个结果图来
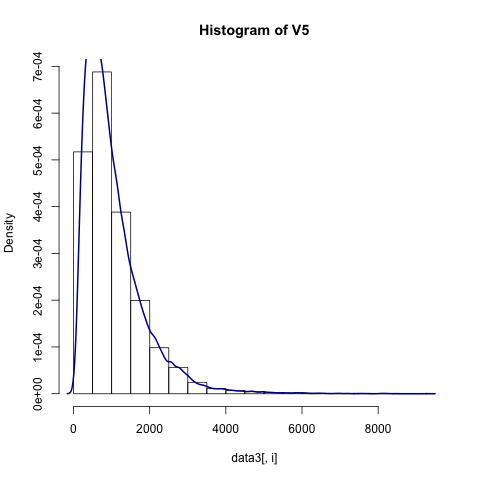
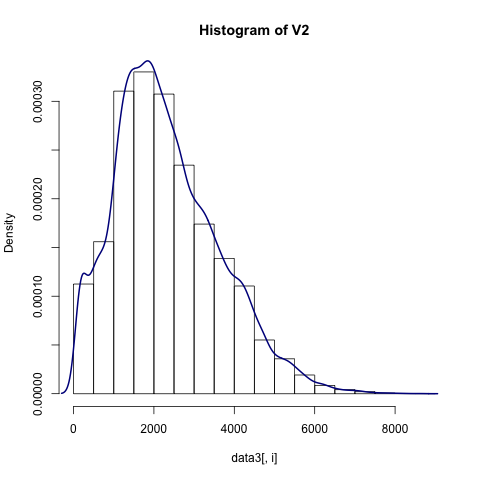
2.2 查看缺失值并进行缺失值填补
在前面我们讲到,缺失值如果比较多的话,决策树就越会进行有偏选择变量,所以要尽可能保证没有缺失值,但是在实际业务中缺失值在所难免,比如购买的第三方数据并没有这个用户的相关数据,那就有缺失值了,所以缺失值处理要根据业务来定,如果第三方数据的缺失值很低,可以进行填补或者删除,如果缺失值太大,那么就只能删除了
笔者这里也自定义了一个查看各个变量的缺失率的函数
> n_r <- na_ratio(sd)
> head(n_r)
vars na_ratio
1 target 0
2 V1 0
3 V2 0
4 V3 0
5 V4 0
6 V5 0
> tail(n_r)
vars na_ratio
130 V129 0.00000000
131 V130 0.02855439
132 V131 0.12752863
133 V132 0.12752863
134 V133 0.12752863
135 V134 0.00000000
可以看到有些变量是有缺失值的,因为笔者所在公司目前的策略平台并不支持线上处理数据,只能进行简单的四则运算,所以对于缺失值只能将其删除,但是也不妨碍我们在自己练习的时候学一些填补方法
缺失值填补方法整理如下:
1.中心趋势值填补,即对于数值型变量,用平均值或者中位数填补,类别型用众数填补,这类填补方式的优点是计算方便快捷,缺点是没有考虑目标变量的情况
2.处理缺失值的方法,根据变量之间的相关关系填补缺失值。比如选取离缺失值比较近的几行数据来进行填补,用户的最多的就是k近邻算法了,可以用VIM包的中kNN函数来操作,也可以用caret包中的preProcess函数。需要注意的是,采用K近邻方法时,会对原始数据进行标准化,如果需要返回原始值,还需将标准化公式倒推回来;
3.使用Bagging树集成方法,理论上对缺失值的填补更权威,但其效率比较低,这个可以用caret包中的preProcess函数
4.多重插补法,可以试试mice包,其操作原理是基于MC(蒙特卡洛模拟法)
这里笔者用的是最简单的方式:
如果缺失率超过某一阈值,删除那一列;对于数值型变量,符合正态分布的变量用平均值填补,不符合正态分布的用中位数填补;对于名义变量,我们用众数填补
#threshold=0.3代表缺失率超过30%就把这一列数据删除,alpha=0.05用来判断正态分布的
sd <- centralImputation(sd,threshold = 0.3,alpha = 0.05)
no_null_data <- sd$complete_data
> sd$delete_vars
$`以下数值型变量的不重复值少于3个(包含缺失值),建议剔除该变量`
[1] "V11" "V133" "target"
$`以下类别型变量的不重复值少于2个(包含缺失值),建议剔除`
NULL
由结果可看到,V11,V133列因为不重复值太少太少,做规则都不合适了,所以建议剔除
no_null_data <- subset(no_null_data,select=-c(V11,V133))
2.3 删除高相关的预测变量和完全线性关系的变量
上面我们讲到了,如果变量之间相关性较大的话,会导致决策树算出来的模型不稳定
可以利用cor函数来查看每个变量之间的相关性,但是如果变量太多的话人工看过去是很花费时间和精力的,除非自己写个函数把相关性弱的挑出来
这里可以使用caret包中的
函数语法及参数介绍:
findCorrelation(x, cutoff = .90, verbose = FALSE,names = FALSE, exact = ncol(x) < 100)
x:为一个相关系数矩阵
cutoff:指定高度线性相关的临界值,默认为0.9
verbose:逻辑值,指定是否打印出函数运算的详细结果
names:逻辑值,是否返回变量名,默认返回需要删除变量的对应索引值
exact:逻辑值,是否重新计算每一步的平均相关系数
x = subset(no_null_data,select = -c(target))
x_no_character <- subset(x,select = -c(V1)) #去除已知的类别型数据
corr <- cor(x_no_character) #在用findCorrelation之前要先计算出相关性矩阵
发现这里出现了个错误,如下所示,这说明数据里面混入了我所不知道的类别型数据
> corr <- cor(x_no_character)
Error in cor(x_no_character) : 'x' must be numeric
所以只好写了个识别数据类型的函数
> data_type(x_no_character)
$numeric
[1] "V47" "V58" "V69" "V80" "V91" "V102" "V113" "V2" "V13" "V24" "V35"
[12] "V41" "V42" "V43" "V44" "V45" "V46" "V48" "V49" "V50" "V51" "V52"
[23] "V53" "V54" "V55" "V56" "V57" "V59" "V60" "V61" "V62" "V63" "V64"
[34] "V65" "V66" "V67" "V68" "V70" "V71" "V72" "V73" "V74" "V75" "V76"
[45] "V77" "V78" "V79" "V81" "V82" "V83" "V84" "V85" "V86" "V88" "V89"
[56] "V90" "V92" "V93" "V94" "V95" "V96" "V97" "V98" "V99" "V100" "V101"
[67] "V103" "V104" "V105" "V106" "V107" "V108" "V109" "V110" "V111" "V112" "V114"
[78] "V115" "V116" "V117" "V118" "V119" "V120" "V121" "V122" "V123" "V125" "V126"
[89] "V127" "V128" "V129" "V130" "V131" "V132" "V134" "V3" "V4" "V5" "V6"
[100] "V7" "V8" "V9" "V10" "V12" "V14" "V15" "V16" "V17" "V18" "V19"
[111] "V20" "V21" "V22" "V23" "V25" "V26" "V27" "V28" "V29" "V30" "V31"
[122] "V32" "V33" "V34" "V36" "V37" "V38" "V39" "V40"
$category
[1] "V124" "V87"
终于发现了问题所在,分别查看这两列数据,发现是用户ID,是没有用的,所以将其删除
x_no_character <- subset(x_no_character,select = -c(V124,V87))
data_type(x_no_character) #发现已经没有类别型数据了
corr <- cor(x_no_character) #在用findCorrelation之前要先计算出相关性矩阵
corr[upper.tri(corr)] #返回相关系数矩阵中的上三角值,预先查看高相关性值,但不能明确那组变量间是高相关的。
library(caret)
fc <- findCorrelation(corr,cutoff=0.80) #返回需要删除变量的对应索引值
x_need_data <- subset(x_no_character,select = -fc)
2.4 计算各个变量的WOE值
后续的下回再写
