数据审核节点将首先全面检查用户导入到 IBM SPSS Modeler 的数据。在初始数据探究过程中经常会使用数据审核报告,该报告显示了摘要统计以及每个数据字段的直方图和分布图,并且它使您可以指定缺失值、离群值和极值的处理。
本例使用 telco.sav 数据文件
1.读入数据
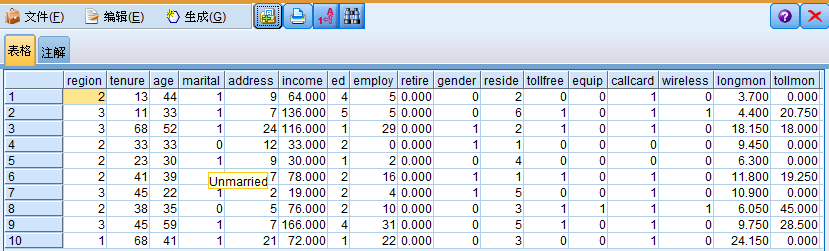
2. 添加"类型"节点以定义字段,并将 churn 指定为目标字段(角色为目标)。为了使此字段成为唯一目标字段,应将所有其他字段的角色设置为输入。
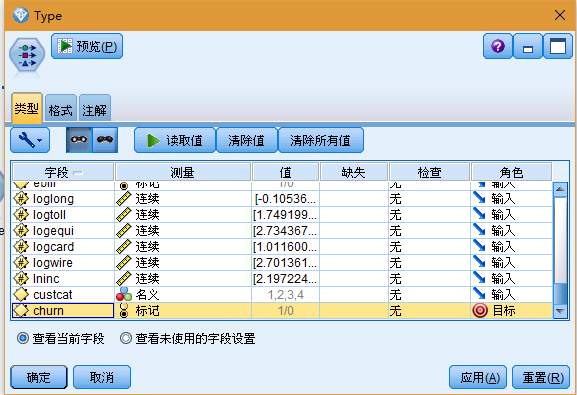
3. 确认已正确定义字段的测量级别。例如,大多数值为 0 和 1 的字段都可以用作标志字段,但某些字段,比如性别,作为包含两个值的名义字段会更加准确。
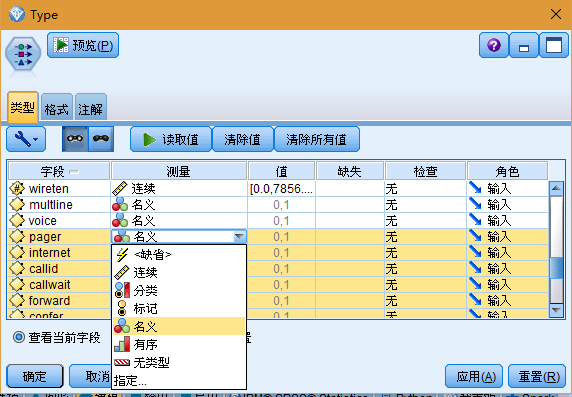
提示:要更改多个具有相似值(例如 0/1)的字段的属性,请单击值列标题以按照该列对字段进行排序,然后使用 Shift 键选择所有要更改的字段。然后可以右键单击选定项,更改所有选定字段的测量级别或其他属性。
4. 将"数据审核"节点附加到流。在"设置"选项卡上,保留缺省设置以便在报告中包含所有字段。由于 churn 是类型节点中定义的唯一目标字段,系统会自动将其用作交叠字段。在"质量"选项卡上,保留检测缺失值、离群值和极值的所有缺省设置,然后单击运行。
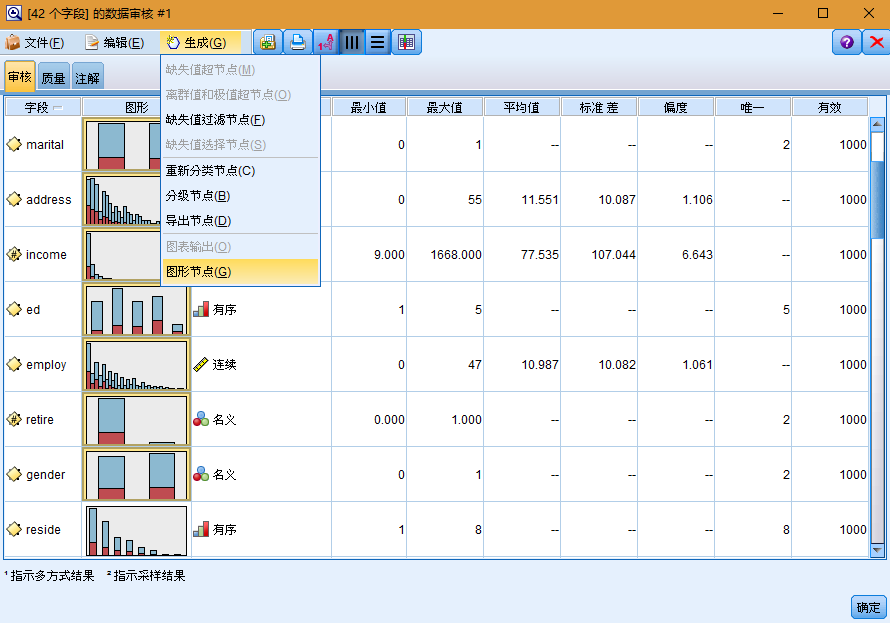
将显示"数据审核"浏览器,其中包含每个字段的缩略图和描述统计。
使用工具栏显示字段和值标签,并将图表从水平对齐切换为垂直对齐(仅适用于分类字段)。
1. 也可以使用工具栏或"编辑"菜单选择要显示的统计量。
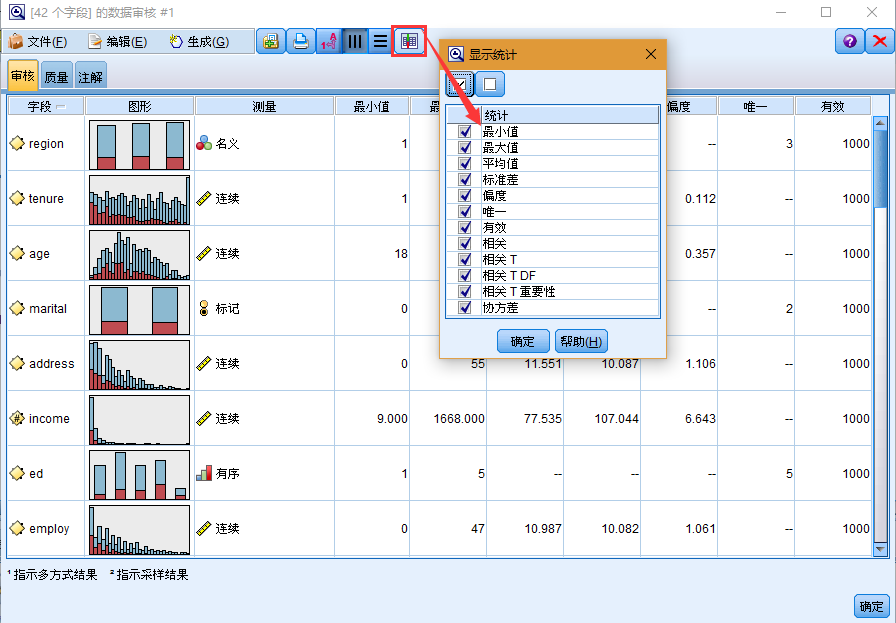
双击审核报告中的任意缩略图可以查看该图表的全尺寸版本。由于 churn 是流中的唯一目标字段,系统会将其自动用作交叠字段。可以使用图形窗口工具栏来切换字段标签和值标签的显示,也可以单击"编辑方式"按钮对该图表进行进一步定制。
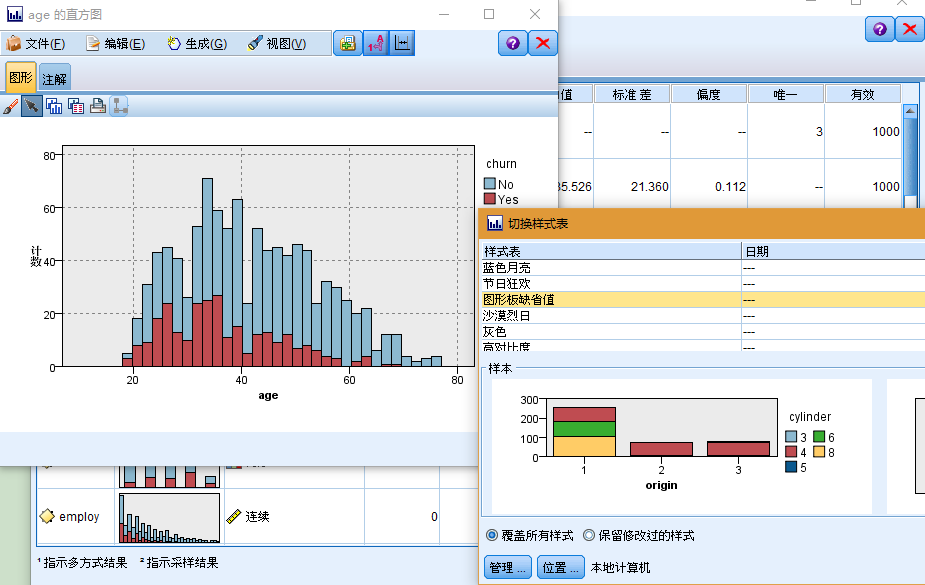
另外,您也可以选择一个或多个缩略图并为每个缩略图生成"图形"节点。生成的节点将放在流画布中,您可以将其添加到流中以重新创建该特定的图形。
处理离群值和缺失值
审核报告中的"质量"选项卡显示有关离群值、极值和缺失值的信息。
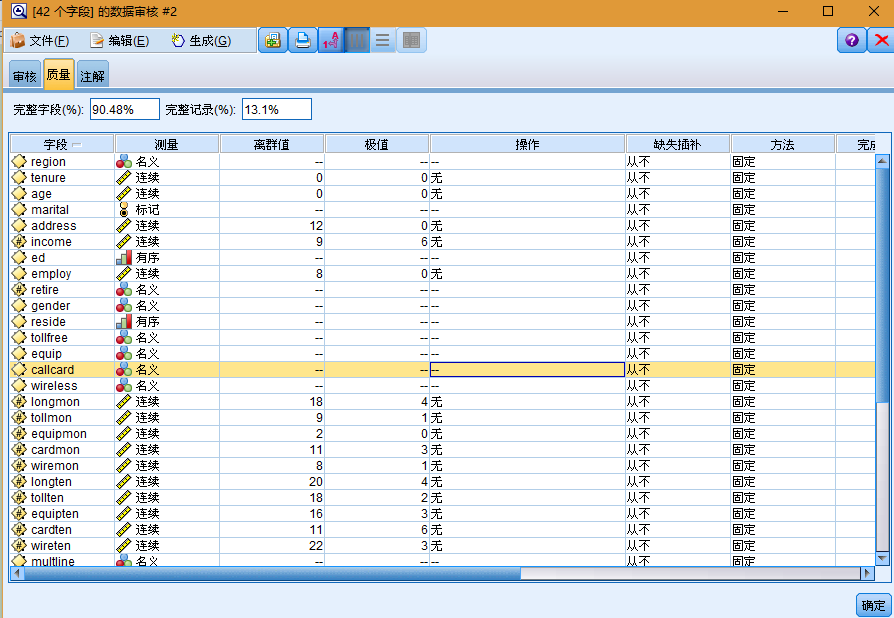
也可以指定处理这些值的方法并生成超节点,以自动应用各种变换。例如,您可以使用多种方法(包括 C&RT算法)来选择一个或多个字段并选择插补或替换这些字段的缺失值。
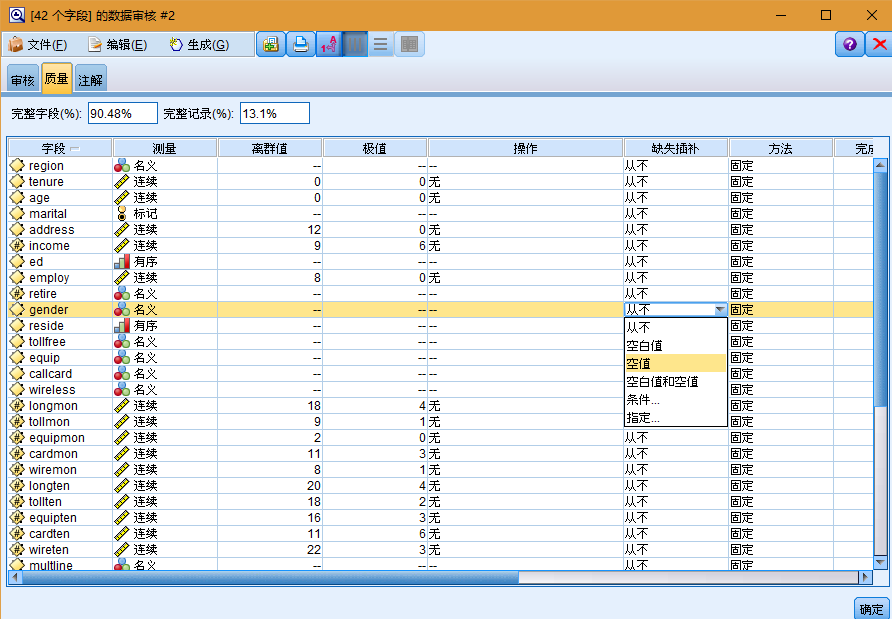
指定用于一个或多个字段的归因方法后,要生成缺失值超节点,请从菜单中选择:
生成 > 缺失值超节点
另外,也可以生成"选择"节点或"过滤"节点,以除去具有缺失值的字段或记录。例如,您可以过滤掉质量百分比低于指定阈值的任何字段。
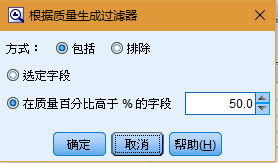
也可以用类似的方法来处理离群值和极值。指定要对每个字段执行的操作(强制、废弃或取消)并生成超节点,以应用各种变换。
完成审核并将生成的节点添加到流中之后,您可以继续进行分析。您可能会选择使用"异常检测"、"特征选择"或其他多种方法来进一步筛选数据。
文末转一个超节点的知识:https://www.sohu.com/a/152105778_99910245
