作者:黄天元,复旦大学博士在读,目前研究涉及文本挖掘、社交网络分析和机器学习等。希望与大家分享学习经验,推广并加深R语言在业界的应用。
邮箱:huang.tian-yuan@qq.com
通常,我们拿到一份数据不能马上分析,要先搞清楚这份数据的特点是什么。探索性数据分析就是为了解决这个问题而设计的,下面我们通过一个案例进行展示。本案例数据可在这里获得:
https://github.com/DataScienceUB/introduction-datascience-python-book
Python
数据导入
#数据读入
file = open('G:/Py/introduction-datascience-python-book-master/files/ch03/adult.data', 'r')
def chr_int(a): if a.isdigit(): return int(a) else: return 0
data=[] for line in file: data1=line.split(', ') if len(data1)==15: data.append([chrint(data1[0]),data1[1],chrint(data1[2]),data1[3],chrint(data1[4]),data1[5],data1[6],\ data1[7],data1[8],data1[9],chrint(data1[10]),chrint(data1[11]),chrint(data1[12]),data1[13],\ data1[14]])
print (data[1:2])
结果:
[[50, 'Self-emp-not-inc', 83311, 'Bachelors', 13, 'Married-civ-spouse', 'Exec-managerial', 'Husband', 'White', 'Male', 0, 0, 13, 'United-States', '<=50K\n']]
数据转化与审视
#转化为数据框格式
%matplotlib inline import pandas as pd
df = pd.DataFrame(data) # Two-dimensional size-mutable, potentially heterogeneous tabular data structure with labeled axes
df.columns = ['age', 'typeemployer', 'fnlwgt', 'education', "educationnum","marital", "occupation", "relationship", "race","sex", "capitalgain", "capitalloss", "hrperweek","country","income"]
观察前几行
df.head()
(点击放大哦)
观察后几行
df.tail()
(点击放大哦)
查询行列数量
df.shape
结果:
(32561, 15)
对国家进行汇总统计
counts = df.groupby('country').size()
print (counts)
结果:
country
? 583
Cambodia 19
Canada 121
China 75
Columbia 59
Cuba 95
Dominican-Republic 70
Ecuador 28
El-Salvador 106
England 90
France 29
Germany 137
Greece 29
Guatemala 64
Haiti 44
Holand-Netherlands 1
Honduras 13
Hong 20
Hungary 13
India 100
Iran 43
Ireland 24
Italy 73
Jamaica 81
Japan 62
Laos 18
Mexico 643
Nicaragua 34
Outlying-US(Guam-USVI-etc) 14
Peru 31
Philippines 198
Poland 60
Portugal 37
Puerto-Rico 114
Scotland 12
South 80
Taiwan 51
Thailand 18
Trinadad&Tobago 19
United-States 29170
Vietnam 67
Yugoslavia 16
dtype: int64
这里大家可以自行尝试对其他变量进行汇总统计
数据分割
#根据性别、收入水平对数据取子集
ml = df[(df.sex == 'Male')] ml1 = df[(df.sex == 'Male')&(df.income=='>50K\n')] fm =df[(df.sex == 'Female')] fm1 =df[(df.sex == 'Female')&(df.income=='>50K\n')] df1=df[(df.income=='>50K\n')]
这里大家可以尝试看看每个子集的行列数量,并可以试着计算高收入群体的的比例、男/女性群体中高收入群体的占比。
基本统计量展示
#求均值、方差、标准差
mlmu = ml['age'].mean() fmmu = fm['age'].mean() mlvar = ml['age'].var() fmvar = fm['age'].var() mlstd = ml['age'].std() fmstd = fm['age'].std() print ('Statistics of age for men: mu:', mlmu, 'var:', mlvar, 'std:', mlstd) print ('Statistics of age for women: mu:', fmmu, 'var:', fmvar, 'std:', fmstd)
#求中位数
mlmedian= ml['age'].median() fmmedian= fm['age'].median() print ("Median age per men and women: ", mlmedian, fmmedian)
mlmedianage= ml1['age'].median() fmmedianage= fm1['age'].median() print ("Median age per men and women with high-income: ", mlmedianage, fmmedianage)
结果:
Statistics of age for men: mu: 39.43354749885268 var: 178.77375174529985 std: 13.370630192526448
Statistics of age for women: mu: 36.85823043357163 var: 196.3837063948063 std: 14.013697099438332
Median age per men and women: 38.0 35.0
Median age per men and women with high-income: 44.0 41.0
清除离群点
首先明确什么是离群点,离群点就是离中位数或均值非常遥远的数据点,它们可能是由于观察、操作错误引起的,也有可能是随机事件,也就是极端的情况。如果我们希望发现总体情况的时候,应该清楚这些数据点,否则对我们的结果造成非常大的影响,误导我们的认识。 在这个案例中,我们清除掉比中位数大或小3倍标准差的点。
df.shape
结果:
(32561, 15)
df2 = df.drop(df.index[(df['hrperweek'] > (df['hrperweek'].median() + 3df['hrperweek'].std())) & (df['hrperweek'] < (df['hrperweek'].median() - 3df['hrperweek'].std()))]) df2.shape
结果:
(32561, 15)
上面的函数,本质意义是找到中位数大于上界或小于下界的点,然后清楚掉,剩下的就是非离群点。没有清除掉任何离群点。
R
下面来看在R中如何实现相同步骤。
数据导入与审视
#读取
library(tidyverse)
readcsv("G:/Py/introduction-datascience-python-book-master/files/ch03/adult.data",colnames = F) -> df
#设置列名称
names(df) = c('age', 'typeemployer', 'fnlwgt', 'education', "educationnum","marital", "occupation", "relationship", "race","sex", "capitalgain", "capitalloss", "hrperweek","country","income")
观察前几行
df %>% head

(点击放大哦)
观察后几行
df %>% tail
(点击放大哦)
R df %>% dim
32561
15
R df %>% count(country)
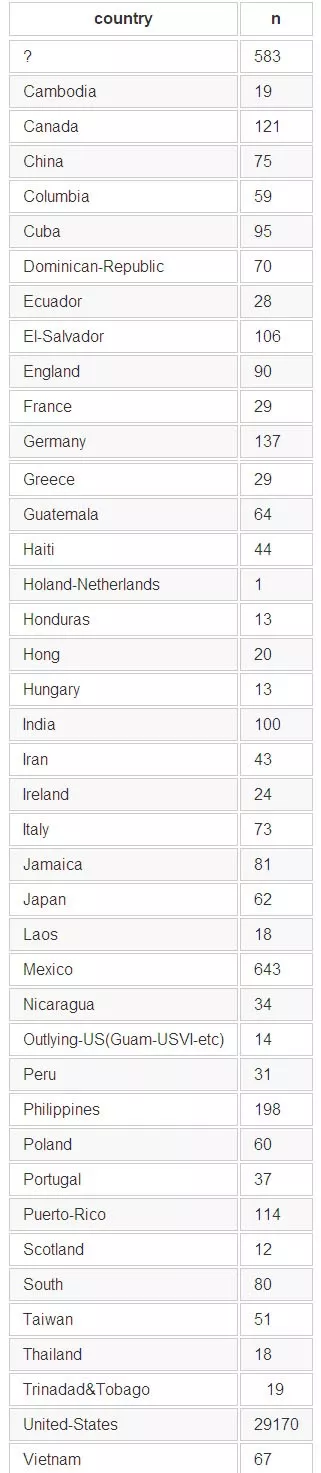
数据分割
R df %>% filter(sex == 'Male') -> ml df %>% filter(sex == 'Male',income == '>50K\n') -> ml1 df %>% filter(sex == 'Female') -> fml df %>% filter(sex == 'Female',income == '>50K\n') -> fml1 df %>% filter(income == '>50K\n') -> df1
基本统计量展示
ml %>% pull(age) %>% mean -> mlmu ml %>% pull(age) %>% var -> mlvar ml %>% pull(age) %>% sd -> mlstd ml %>% pull(age) %>% median -> mlmedian
print(c(mlmu,mlvar,mlstd,mlmedian))
结果:
[1] 39.43355 178.77375 13.37063 38.00000
清除离群点
R df %>%dim
32561
15
df %>% pull(hrperweek) %>% sd -> hrsd df %>% pull(hrperweek) %>% median -> hrmedian
df %>% filter(hrperweek <= (hrmedian + 3hrmedian) | hrperweek >= (hrmedian - 3hrmedian)) -> df2
dim(df2)
32561
15
上面的操作本质是筛选在上下界之间的数据点。
分析
在清楚离群点的时候,两个语言用的函数和思路不一样,需要体会一下。值得注意的是,使用dplyr管道的时候要随时注意数据集的改变,因此对中位数和标准差的计算需要在外部进行,然后在最后的函数中直接以常数的形式被利用。
大家都在看
R语言二分类问题案例分析:以泰坦尼克号沉船为例
无缝对接Spark与R:Sparklyr系列—探讨属于数据科学家的Spark
R与Python手牵手:数据的分组排序
R与Python手牵手:数据框的构建、读取与基本描述
R与Python手牵手:数据科学导论系列(包的载入)

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法

