作者:黄天元,复旦大学博士在读,目前研究涉及文本挖掘、社交网络分析和机器学习等。希望与大家分享学习经验,推广并加深R语言在业界的应用。
邮箱:huang.tian-yuan@qq.com
这次介绍如何在Python与R中进行表格数据的分组排序,也就是分组进行统一运算,以及按照规则进行排列。
Python
```python
载入模块
import pandas as pd import numpy as np import matplotlib.pylab as plt
载入数据
edu = pd.readcsv('G:/Py/introduction-datascience-python-book-master/files/ch02/educfigdp1Data.csv', navalues=':', usecols=['TIME', 'GEO', 'Value']) #navalues是把“:”符号认为是缺失值的意思 ```
数据可以在以下网址取得:https://github.com/DataScienceUB/introduction-datascience-python-book
排序
```python
按照Value从大到小排序,ascending控制正序倒序,inplace控制是否在原数据集进行修改
edu.sort_values(by='Value', ascending=False, inplace=True) edu.head() ```
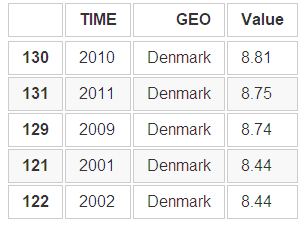
```python
返回原始排序
edu.sort_index(axis=0, ascending=True, inplace=True) edu.head() ```
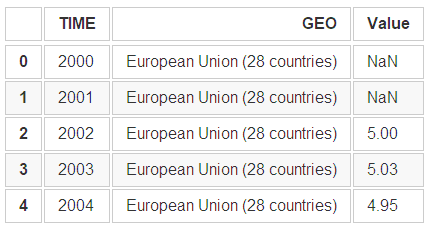
由此,我们也可以发现,无论我们怎么进行排序,原始的行号是一直得以保存的,有了这个我们就可以从新恢复数据的排序。
分组
```python
根据GEO分组得到组内的平均值
group = edu[['GEO', 'Value']].groupby('GEO').mean() group.head() ```
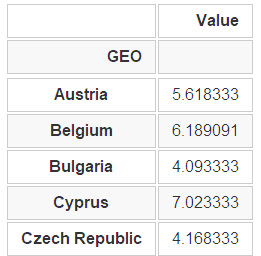
整合
python filtered_data = edu[edu['TIME'] > 2005] pivedu = pd.pivot_table(filtered_data, values='Value', index=['GEO'], columns=['TIME']) pivedu.head()
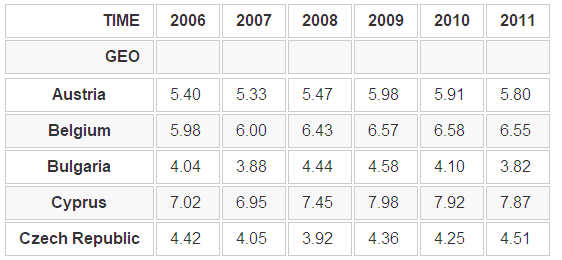
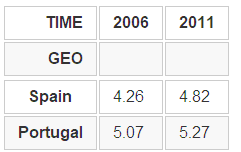
python pivedu.loc[['Spain', 'Portugal'], [2006, 2011]]
R
下面看看R语言中实现相同操作的步骤:
```R
加载包与数据读取
library(tidyverse)
edu = readcsv('G:/Py/introduction-datascience-python-book-master/files/ch02/educfigdp1Data.csv', na=":") %>%
select(TIME,GEO,Value)
```
-- Attaching packages --------------------------------------- tidyverse 1.2.1 -- √ ggplot2 3.0.0 √ purrr 0.2.5 √ tibble 1.4.2 √ dplyr 0.7.6 √ tidyr 0.8.1 √ stringr 1.3.1 √ readr 1.1.1 √ forcats 0.3.0 -- Conflicts ------------------------------------------ tidyverse_conflicts() -- x dplyr::filter() masks stats::filter() x dplyr::lag() masks stats::lag() Parsed with column specification: cols( TIME = col_integer(), GEO = col_character(), INDIC_ED = col_character(), Value = col_double(), `Flag and Footnotes` = col_character() )
排序
R edu %>% arrange(desc(Value)) %>% head

首先,要知道desc()加在Value前,就会变为降序排列,否则默认为升序。 这里,如果需要在原始数据中变更,赋值给本身即可,其实在原始数据中改数据是极其危险的,不推荐,应该总是用copy来操作,如果出错了随时回到原始备份再次copy。
分组
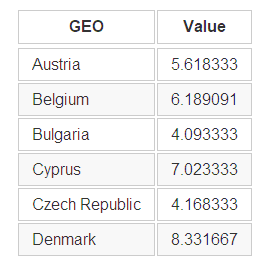
R edu %>% select(GEO,Value) %>% #选择指定列 group_by(GEO) %>% #按照GEO分组 summarize (Value = mean(Value,na.rm = T)) %>% #按照分组计算Value的均值,忽略缺失值 head() #取前几行进行展示
整合
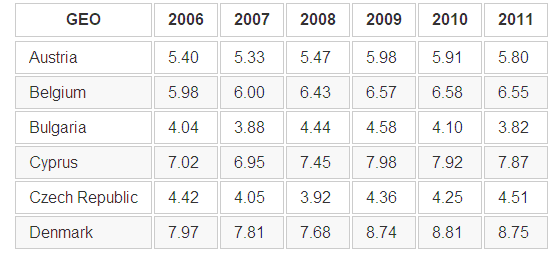
R edu %>% filter(TIME > 2005) %>% spread(key = TIME,value = Value) -> pivedu pivedu %>% head
分析
同样的步骤,不同的表达,大同小异。
温馨提示
后面所有的教程都会坚持用最简单的例子,这样有一点不会的同学也能够很容易通过查询进行扩展。如果个别函数不知道如何使用,请使用?来查询使用方法,如R中“?spread”。
