正则表达式
- 它的设计思想就是用一种描述性语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为他是“匹配”了,否则,该字符串就是不合法。
- 创建一个匹配Email的正则表达式
- 用该正则表达式去匹配用户的输入来判断是否合法。
字符来描述字符
在正则表达式中,如果直接给出字符就是精确匹配。
\d匹配一个数字
\w匹配一个字母或数字
\b代表着单词的开头或结尾,也就是单词的分界处。
"."可以用来匹配任何字符
“*”表示任意个字符(包括0个)
“+”表示至少一个字符
“?”表示0个或1个字符
“{n}”表示n个字符
“{n,m}”表示n-m个字符
“\s”可以匹配一个空格(包括Tab等空白符)
要显示‘-’要用'\'来转义。因为‘-’是特殊字符。
进阶
【0-9a-zA-Z\_】可以匹配一个数字、字母或下划线。
【0-9a-zA-Z\_】+可以匹配至少由一个数字、字母或下划线组成的字符串。
【a-zA-Z\_】【0-9a-zA-Z\_】*可以匹配由一个字母或下划线开头,后接任意个由一个数字、字母或下划线组成的字符串,也就是Python合法的变量。
【a-zA-Z\_】【0-9a-zA-Z\_】{0,19}更精确地限制了变量的长度是1-20个字符(前面一个字符+后面最多19个字符)
A|B可以匹配A或B
^表示行的开头 ^\d表示必须以数字开头
$表示行的结束,\d$表示必须以数字结束
^py$这种形式表示整行匹配,只能匹配py。
re模块
在Python中,re模块,包含所有正则表达式的功能。由于Python的字符串本身也用\来转义。所以要特别注意。
match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则就是None.
test = '用户输入的字符串'
if re.match(r'正则表达式',test):
print('ok')
else:
print('failed')
切分字符串
re.split(r'[\s\,\;]+','a,b;c d')
结果:['a', 'b', 'c', 'd']
若用户输入一组标签,要用正则表达式来把不规范的输入转化成正确的数组。
分组
正则表达式还可以提取子串。
()表示要提取的分组。
如果正则表达式中定义了组,就可以在Match对象上用group()方法来提取子串。
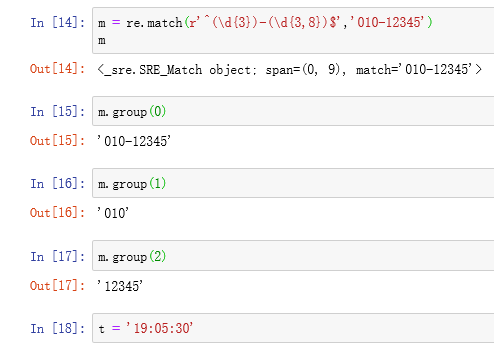
正则表达式有时候也不能完全验证,比如识别日期,这时就需要程序配合识别。
贪婪匹配
正则匹配是贪婪匹配,即匹配尽可能多的字符。
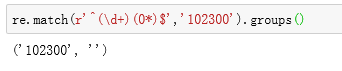
由于\d+采用的是贪婪匹配,直接把后面的0全部匹配了,结果0*只能匹配空字符串。
加个?就可以采用非贪婪匹配。


