上一讲中,我们介绍了如何用SPL将一行日志结构化为一条记录,今天则要说一下多行日志对应一条记录的情况,我们称之为不定行日志。
事实上,集算器自己的输出日志就是这种不定行日志,我们来看一下集算器节点机下的一个日志文件rqlog. log,同样摘录两段日志:
[2018-05-14 09:20:20]
DEBUG: 临时文件过期时间为:12小时。
[2018-05-14 09:20:20]
DEBUG: Temporary file directory is:
D:\temp\esProc\nodes\127.0.0.1_8281\temp.
Files in temporary directory will be deleted on every 12 hours.
简单分析一下这两段日志,每一段第一行都是方括号中的时间,紧接着第二行是用冒号分隔的日志类型和日志内容,随后各行都是日志内容的补充,直至遇到下一个方括号中的时间行。由此可以确定,结构化后的字段应该有三个:日志时间、日志类型和日志内容。
对于这种不定行的日志,最直接的结构化思路就是逐行加载,并根据条件拼接成相应的字段。但这里有个麻烦,由于每条记录对应的行数不确定,所以需要另外通过条件判断来识别每条记录的起始行。另一个问题就是当使用游标分析比较大的文件时,由于每次fetch的行数不可能总是刚好断在一条记录的末尾,所以在fetch的块与块之间还要考虑衔接问题。
所以,对于这种类型的日志,最理想的方法,是应该能把每一块日志与其它块自动分开。这样,就可以直接将每一块日志解析到一条记录,而不需要考虑读取的行应该属于上一条记录还是下一条记录。
SPL中就有这样的分组方式,形如A.group@i(exp),只不过其中的分组表达式exp不能返回枚举值,而应该返回布尔值。而i选项则表示根据相邻行计算exp,如果返回true就表示建立一个新组,其后面连续返回false的行都归于这个组。
有了这样的分组方式,我们只要写出能解析记录第一行的exp就可以了。本例中,记录第一行是以方括号“[”开始的一个日期时间,如果能够确定后面的内容中不会有以“[”开始的行,那么分组表达式只需判断每一行的第一个字符是否为‘[’就可以了。
下面是实现的脚本文件convertlog.dfx:
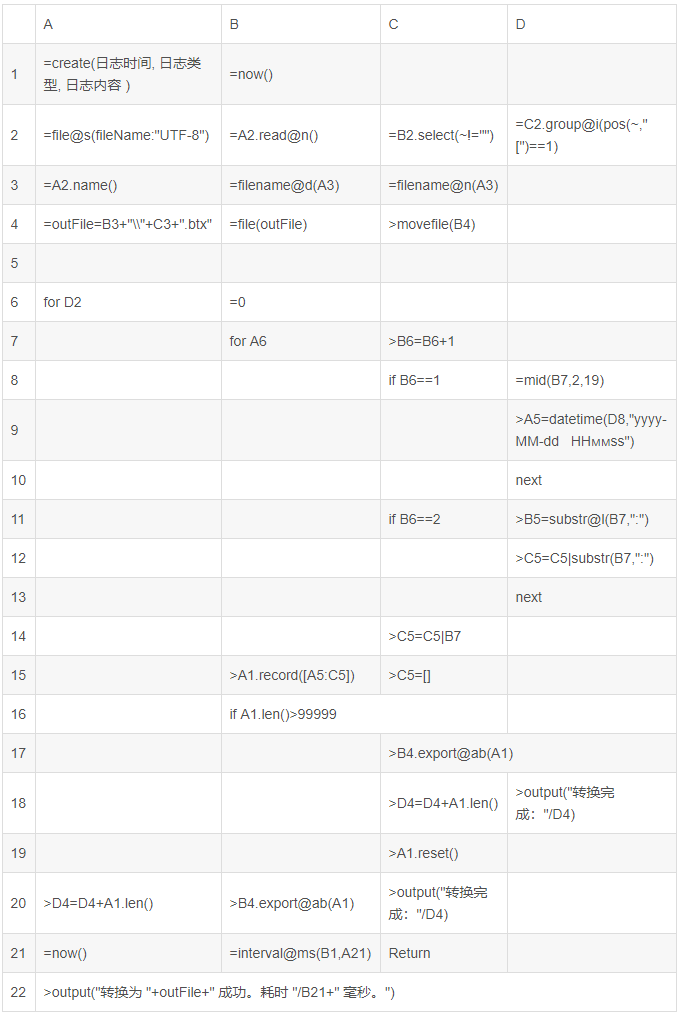
表(1)
脚本仍然是一次性将文件全部读入,只是在分析过程中,每凑够十万行就将其追加到输出文件。下面是重点代码的解析:
1) C2过滤空行,日志的块与块之间可能有很多空行,此处用select函数选出非空行。
2) D2是本例的重点,按照每一行是否由‘[’开头来进行分组,分组后的结果是每一块对应一个序列,再由这些块序列组成一个大的序列。
3) 第5行空了出来,其实是预留A5到C5来容纳解析后的3个字段。
4) 由于D2返回的序列已经是按照记录对应的块做好分组了,所以只需在A6中对D2序列循环即可。
5) B7到C14将每一块日志结构化到各个字段。
6) A20到C20将最后一段不够十万行的数据,写到文件。
下面是当前代码的执行结果:
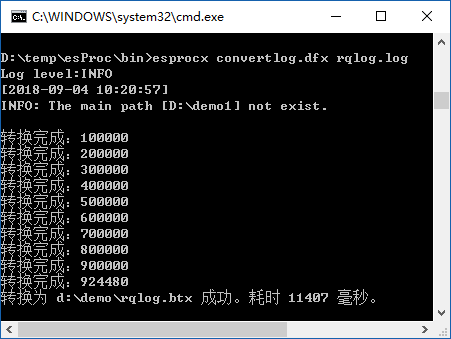
图(1)
上面这个例子介绍了如何用分组来结构化不定行的日志。不过,分析前仍然导入了整个文件,占用的内存较大。为了减少内存占用,我们可以使用游标来处理。和上面这个例子非常类似,从文件得到游标后,紧接着的是和序列几乎一样的过滤、分组方法。细微的区别是由于游标中返回的分组是序表,而不再是序列,因此需要用字段名‘_1’来引用各行的值。另外,使用游标后,每次fetch得到的是一个序表的序列,因此相对于全文导入,要多一层循环处理。
下面是实现的脚本文件convertLogCursor.dfx:

表(2)
可以看到,除了用游标时,表达式中需要使用缺省字段名‘_1’,以及多了一层循环取数,这个脚本和前面全部读入文件的方式完全一致。执行后可以看到结果也跟convertLog.dfx完全一样。
看到这里,细心的读者可能会想到,是不是也可以像上一讲一样,使用多路游标来提升性能?答案是肯定的,不过需要调整一下方法。如果只是简单使用cursor@m返回多路游标的话,由于线程游标是由SPL自动创建的,每个游标会被自动分配一段属于自己的数据,这就有可能会将本来属于同一条记录的数据块,分配给了两个线程,从而造成线程内部难以处理数据缺失的部分。如果不介意部分数据不完整,那么可以稍稍调整一下脚本,直接跳过残缺的记录。而如果对数据的完整性要求很严格的话,就需要将不完整的记录头和记录尾返回给主程序,让主程序来集中处理了。但要注意的是多路游标的各线程游标是自动创建的,线程之间的顺序不好确定,所以主程序拿到这些不完整的记录头和记录尾,也会因为次序没法确定而无法正确衔接。因此,这时就需要改用 fork to(n)语句来主动创建顺序线程了。fork语句所在的格子值就是当前线程的序号,然后在代码段中创建局部游标,并加载相应的数据段就可以了。 不过,无论如何都会麻烦一些,因不是很常见,这里也就不再举例了,有兴趣的同学可以将它作为一个练习题。
最后总结一下,不定行日志的处理关键是确定几行日志可以“凑”成一条记录。而利用集算器SPL中group函数的@i选项,就可以定义日志块的分隔条件,从而简洁方便地“庖丁解牛”了。
