
作者:鲁伟
一个数据科学践行者的学习日记。数据挖掘与机器学习,R与Python,理论与实践并行。
个人公众号:机器学习实验室 (微信ID:louwill12)
前文传送门:
深度学习笔记13:Tensorflow实战之手写mnist手写数字识别
深度学习笔记14:CNN经典论文研读之Le-Net5及其Tensorflow实现
深度学习笔记15:ubuntu16.04 下深度学习开发环境搭建与配置
深度学习笔记16:CNN经典论文研读之AlexNet及其Tensorflow实现
深度学习第18讲:CNN经典论文研读之VGG网络及其tensorflow实现
在 VGG 网络论文研读中,我们了解到卷积神经网络也可以进行到很深层,VGG16 和 VGG19 就是证明。但卷积网络变得更深呢?当然是可以的。深度神经网络能够从提取图像各个层级的特征,使得图像识别的准确率越来越高。但在2014年和15年那会儿,将卷积网络变深且取得不错的训练效果并不是一件容易的事。
深度卷积网络一开始面临的最主要的问题是梯度消失和梯度爆炸。那什么是梯度消失和梯度爆炸呢?所谓梯度消失,就是在深层神经网络的训练过程中,计算得到的梯度越来越小,使得权值得不到更新的情形,这样算法也就失效了。而梯度爆炸则是相反的情况,是指在神经网络训练过程中梯度变得越来越大,权值得到疯狂更新的情形,这样算法得不到收敛,模型也就失效了。当然,其间通过设置 relu 和归一化激活函数层等手段使得我们很好的解决这些问题。但当我们将网络层数加到更深时却发现训练的准确率在逐渐降低。这种并不是由过拟合造成的神经网络训练数据识别准确率降低的现象我们称之为退化(degradation)。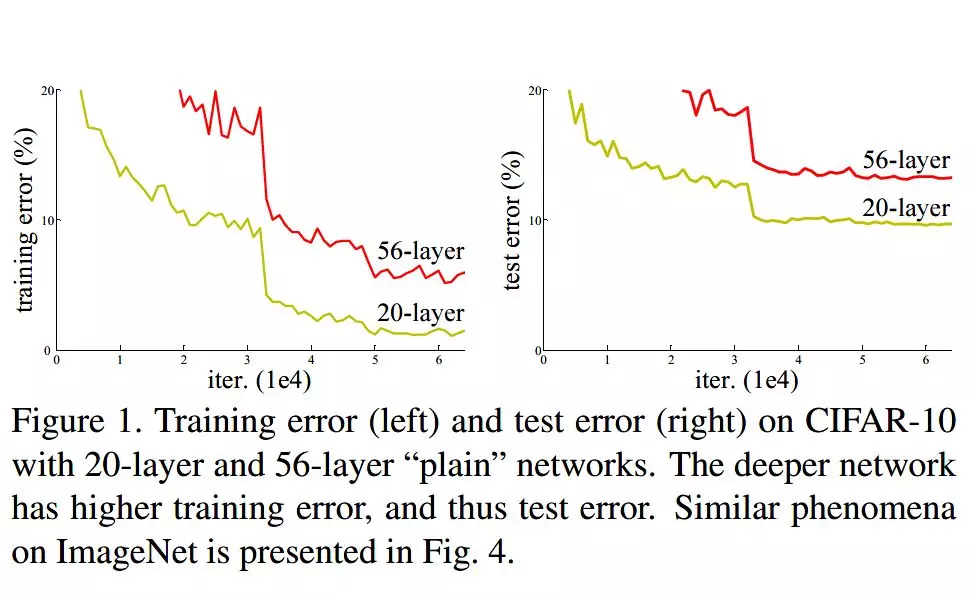
由上图我们可以看到 56 层的普通卷积网络不管是在训练集还是测试集上的训练误差都要高于 20 层的卷积网络。是个典型的退化现象。
这退化问题不解决,咱们的深度学习就无法 go deeper. 于是何凯明等一干大佬就发明了今天我们要研读的论文主题——残差网络 ResNet.
残差块与残差网络
要理解残差网络,就必须理解残差块(residual block)这个结构,因为残差块是残差网络的基本组成部分。回忆一下我们之前学到的各种卷积网络结构(LeNet-5/AlexNet/VGG),通常结构就是卷积池化再卷积池化,中间的卷积池化操作可以很多层。类似这样的网络结构何凯明在论文中将其称为普通网络(Plain Network),何凯明认为普通网络解决不了退化问题,我们需要在网络结构上作出创新。
何凯明给出的创新在于给网络之间添加一个捷径(shortcuts)或者也叫跳跃连接(skip connection),这使得捷径之间之间的网络能够学习一个恒等函数,使得在加深网络的情形下训练效果至少不会变差。残差块的基本结构如下:
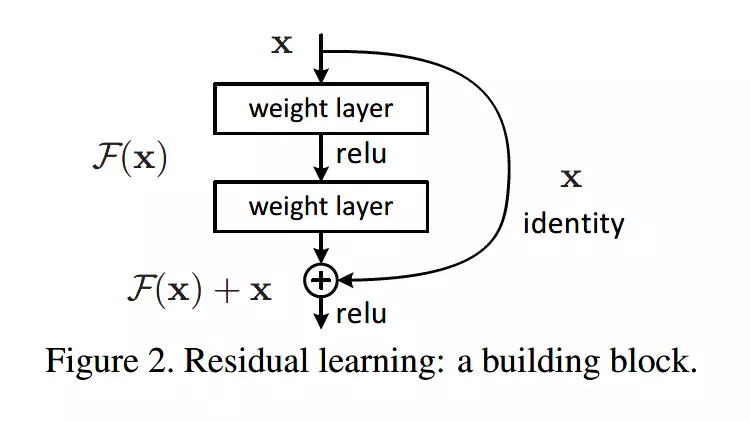
以上残差块是一个两层的网络结构,输入 X 经过两层的加权和激活得到 F(X) 的输出,这是典型的普通卷积网络结构。但残差块的区别在于添加了一个从输入 X 到两层网络输出单元的 shortcut,这使得输入节点的信息单元直接获得了与输出节点的信息单元通信的能力 ,这时候在进行 relu 激活之前的输出就不再是 F(X) 了,而是 F(X)+X。当很多个具备类似结构的这样的残差块组建到一起时,残差网络就顺利形成了。残差网络能够顺利训练很深层的卷积网络,其中能够很好的解决网络的退化问题。
或许你可能会问凭什么加了一条从输入到输出的捷径网络就能防止退化训练更深层的卷积网络?或是是说残差网络为什么能有效?我们将上述残差块的两层输入输出符号改为 和 ,相应的就有:
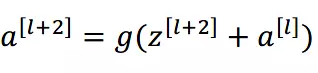
加入 的跳跃连接后就有: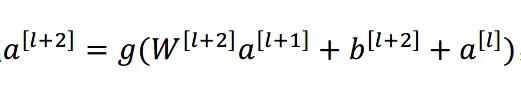
在网络中加入 L2 正则化进行权值衰减或者其他情形下,l+2 层的权值 W 是很容易衰减为零的,假设偏置同样为零的情形下就有 = 。深度学习的试验表明学习这个恒等式并不困难,这就意味着,在拥有跳跃连接的普通网络即使多加几层,其效果也并不逊色于加深之前的网络效果。当然,我们的目标不是保持网络不退化,而是需要提升网络表现,当隐藏层能够学到一些有用的信息时,残差网络的效果就会提升。所以,残差网络之所以有效是在于它能够很好的学习上述那个恒等式,而普通网络学习恒等式都很困难,残差网络在两者相较中自然胜出。
由很多个残差块组成的残差网络如下图右图所示:
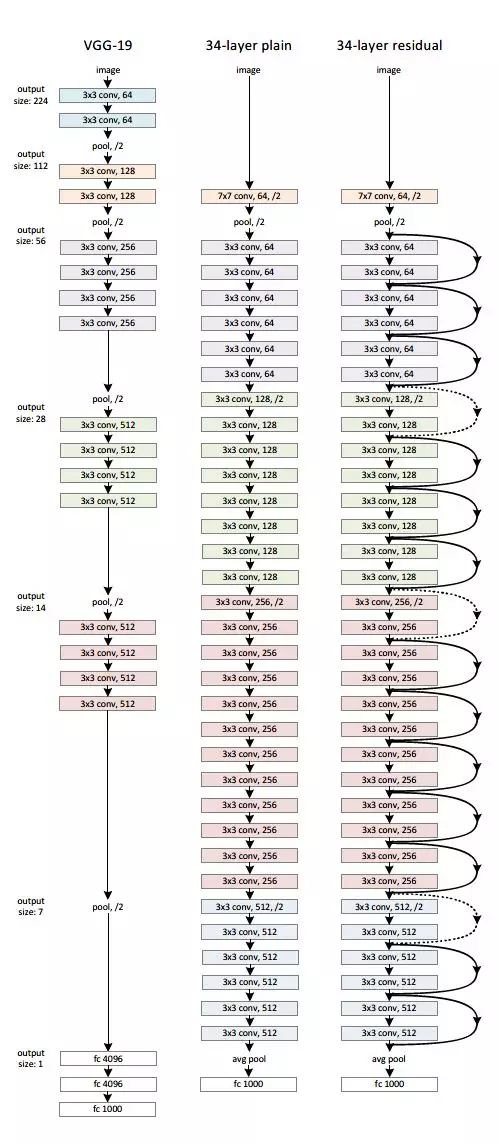
残差块的 keras 实现
要实现一个残差块,关键在于实现一个跳跃连接。实际处理中跳跃连接会随着残差块输入输出大小的不同而分为两种。一种是输入输出一致情况下的 Identity Block,另一种则是输入输出不一致情形下的 Convolutional Block,顾名思义,就是跳跃连接中包含卷积操作,用来使得输入输出一致。且看二者的 keras 实现方法。
Identity Block 的图示如下: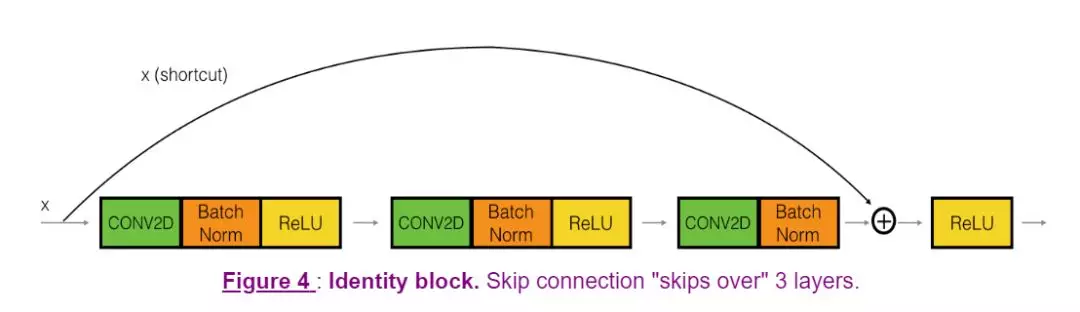
编写实现代码如下:
def identity_block(X, f, filters, stage, block):
"""
Implementation of the identity block as defined in Figure 3
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
Returns:
X -- output of the identity block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# Retrieve Filters
F1, F2, F3 = filters
# Save the input value. You'll need this later to add back to the main path.
X_shortcut = X
# First component of main path
X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
# Second component of main path
X = Conv2D(filters = F2, kernel_size = (f, f), strides= (1, 1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X)
# Third component of main path
X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1, 1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)
# Final step: Add shortcut value to main path, and pass it through a RELU activation
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
return X可见残差块的实现特殊之处就在于添加一条跳跃连接。
Convolutional Block 的图示如下: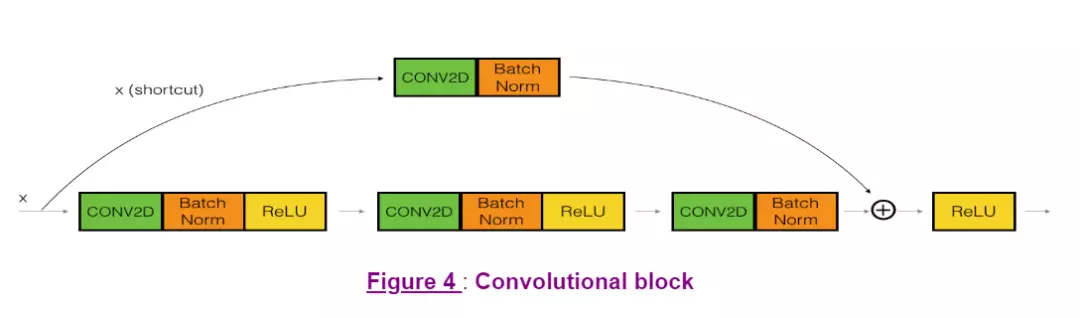
编写实现代码如下:
def convolutional_block(X, f, filters, stage, block, s = 2):
"""
Implementation of the convolutional block as defined in Figure 4
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
s -- Integer, specifying the stride to be used
Returns:
X -- output of the convolutional block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# Retrieve Filters
F1, F2, F3 = filters
# Save the input value
X_shortcut = X
##### MAIN PATH #####
# First component of main path
X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (s,s), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
# Second component of main path
X = Conv2D(filters = F2, kernel_size = (f, f), strides = (1,1), padding = 'same', name = conv_name_base + '2b', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2b')(X)
X = Activation('relu')(X)
# Third component of main path
X = Conv2D(filters = F3, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2c', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2c')(X)
##### SHORTCUT PATH ####
X_shortcut = Conv2D(filters = F3, kernel_size = (1, 1), strides = (s, s), padding = 'valid', name = conv_name_base + '1', kernel_initializer = glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis = 3, name = bn_name_base + '1')(X_shortcut)
# Final step: Add shortcut value to main path, and pass it through a RELU activation
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
return X残差网络 resnet50 的 keras 实现
搭建好组件残差块之后就是确定网络结构,将一个个残差块组成残差网络。下面搭建一个 resnet50 的残差网络,其基本结构如下:
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK2 -> CONVBLOCK -> IDBLOCK3 -> CONVBLOCK -> IDBLOCK5 -> CONVBLOCK -> IDBLOCK2 -> AVGPOOL -> TOPLAYER
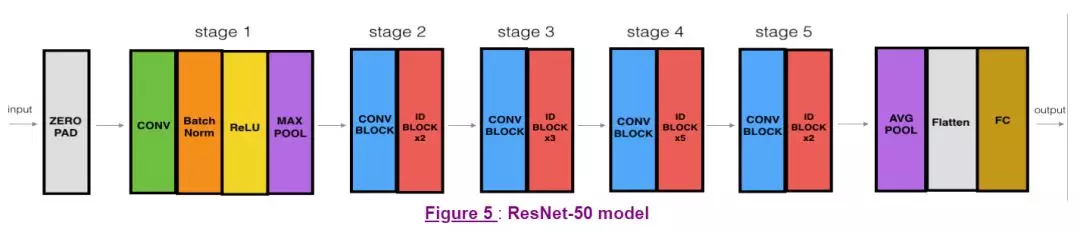
编写实现代码如下:
def ResNet50(input_shape = (64, 64, 3), classes = 6):
# Define the input as a tensor with shape input_shape
X_input = Input(input_shape)
# Zero-Padding
X = ZeroPadding2D((3, 3))(X_input)
# Stage 1
X = Conv2D(64, (7, 7), strides = (2, 2), name = 'conv1', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = 'bn_conv1')(X)
X = Activation('relu')(X)
X = MaxPooling2D((3, 3), strides=(2, 2))(X)
# Stage 2
X = convolutional_block(X, f = 3, filters = [64, 64, 256], stage = 2, block='a', s = 1)
X = identity_block(X, 3, [64, 64, 256], stage=2, block='b')
X = identity_block(X, 3, [64, 64, 256], stage=2, block='c')
# Stage 3
X = convolutional_block(X, f = 3, filters = [128, 128, 512], stage = 3, block='a', s = 2)
X = identity_block(X, 3, [128, 128, 512], stage=3, block='b')
X = identity_block(X, 3, [128, 128, 512], stage=3, block='c')
X = identity_block(X, 3, [128, 128, 512], stage=3, block='d')
# Stage 4
X = convolutional_block(X, f = 3, filters = [256, 256, 1024], stage = 4, block='a', s = 2)
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='b')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='c')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='d')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='e')
X = identity_block(X, 3, [256, 256, 1024], stage=4, block='f')
# Stage 5
X = convolutional_block(X, f = 3, filters = [512, 512, 2048], stage = 5, block='a', s = 2)
X = identity_block(X, 3, [512, 512, 2048], stage=5, block='b')
X = identity_block(X, 3, [512, 512, 2048], stage=5, block='c')
# AVGPOOL (≈1 line). Use "X = AveragePooling2D(...)(X)"
X = AveragePooling2D((2, 2), strides=(2, 2))(X)
# output layer
X = Flatten()(X)
X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer = glorot_uniform(seed=0))(X)
# Create model
model = Model(inputs = X_input, outputs = X, name='ResNet50')
return model这样一个 resnet50 的残差网络就搭建好了,其关键还是在于搭建残差块,残差块搭建好之后只需根据网络结构构建残差网络即可。当然,其间也可以看到 keras 作为一个优秀的深度学习框架的便利之处。
注:本深度学习笔记系作者学习 Andrew NG 的 deeplearningai 五门课程所记笔记,其中代码为每门课的课后assignments作业整理而成。
参考资料:
作者最新课程,限时优惠中
扫码或点击阅读原文了解详情&报名
