作者:师爷,R语言中文社区作者,
知乎专栏:
https://zhuanlan.zhihu.com/rstudio
1.简介整洁数据
虽然我们花费了大量的精力来清理数据以便为分析做好准备,但关于如何使数据清理尽可能简单有效的研究很少。本文讨论了数据清理的一个小但重要的组成部分:数据整理。
整洁的数据集易于操作,建模和可视化,并具有特定的结构:
每个变量都是一列
每个观察值都是一行
每种类型的观察单位是一张表格。
这个可以很容易地整理凌乱的数据集,因为处理各种不整洁的数据集可用的工具非常少。 这种结构还可以更容易地开发用于数据分析的整洁工具,这些工具既可以输入整洁数据同时输出整洁的数据集。最后,通过一个常用的数据操作案例研究来证明:统一的数据结构以及对应配套工具的优势。
人们常说,80%的数据分析都花在清洁和准备过程上数据。令人心烦的是:数据准备不是一蹴而就的,而是随着新问题的出现或新数据的出现,在分析过程中多次重复进行。尽管花费了大量的时间,但却很少关于如何清理数据的研究。一个挑战是它包含的范围广泛:从异常检查,到解析的日期,到缺失值的估算。为了解决问题,本文侧重于数据清理的一个小而重要的方面,我称之为数据整理:构建数据集以便分析。
整洁数据的原则提供了在数据集中组织数据值的标准方法。标准使初始数据清理更容易,因为您不需要从头开始并且每次重新发明轮子。整洁的数据标准旨在促进初步探索和分析数据,并简化数据分析的发展协同工作的工具。当前的工具通常需要进行必要的变换。你必须花时间整洁数据从一个数据工具中以便导入另外一个数据中。整洁的数据集和整洁的工具携手合作,使数据分析更容易,让您专注于有趣的领域问题,而不是无关紧要的数据后勤。整洁数据的原则与关系数据库和Codd的关系代数密切相关,用统计学家熟悉的语言构建。计算机科学家也为数据清理研究做出了很多贡献。例如,Lakshmanan,Sadri和Subramanian(1996)定义了SQL的扩展,允许它在凌乱的数据集上运行,Raman和Hellerstein(2001)提供了清理数据集的框架,Kandel,Paepcke,Hellerstein和Heer开发一个具有友好用户界面的交互式工具,自动创建代码来清理数据。不得不承认这些工具很有用,但是它们以非统计学家的语言呈现,它们没有就如何构建数据集提供太多实用建议,并且它们与既有数据分析工具缺乏联系。没办法只能依靠使用实用数据集的经验推动了整洁数据的发展。由于对其组织的限制很少(如果有的话),这些数据集通常以奇怪的方式构建。在这些工作的过程中,reshape和reshape2软件包非常好用。虽然我可以直观地使用这些工具并通过示例进行教学,但我缺乏使我的直觉明确的框架。本文提供了该框架。它提供了全面的“数据哲学”:基于此开发plyr和ggplot两个包。
论文进行如下:
第2节:首先定义了三个特征使数据集整洁。 由于大多数真实世界数据集都不整洁,
第3节:描述了使杂乱的数据集整洁所需的操作,并用范围说明技术真实的例子。
第4节:定义了整洁的工具,输入和输出整洁数据集的工具,并讨论了整洁的数据和整洁的工具如何使数据分析更容易。
第5节:小案例研究说明了原则。
第6节:以a结尾讨论这个框架错过了什么以及其他方法可能会有成效追求
像家庭一样,整洁的数据集都是相似的,但每个凌乱的数据集都以自己的方式混乱。 整洁数据集提供了一种链接数据集结构的标准化方法(其物理布局)用它的语义(意思)。 在本节中,我将提供一些标准词汇表描述数据集的结构和语义,然后使用这些定义进行定义整洁的数据。
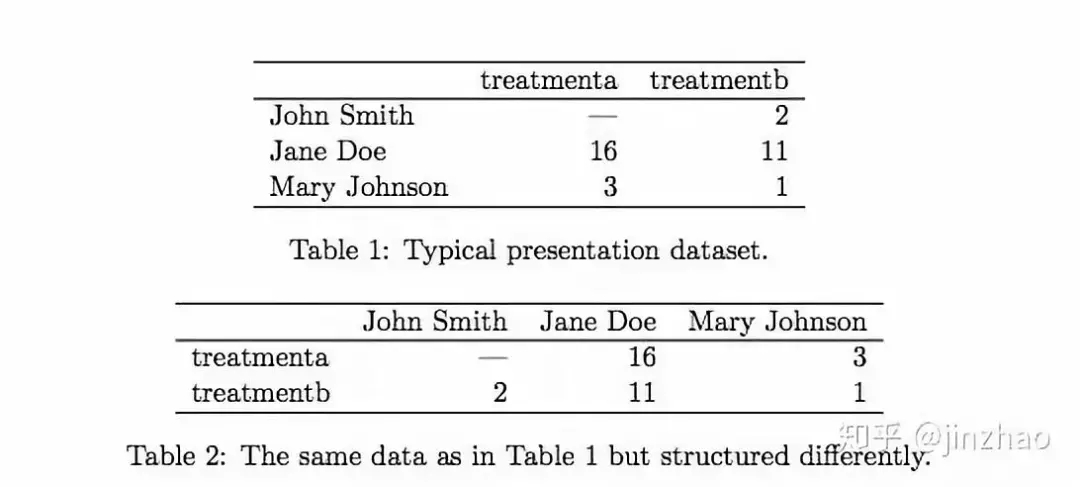
大多数统计数据集是由行和列组成的矩形表。 列几乎总是标记,行有时标记。 表1提供了一些数据关于野外常见的假想实验。 表中有两个列和三行,以及行和列都标记。有许多方法可以构建相同的底层数据。 表2显示了相同的数据如表1所示,但行和列已被转置。 数据是一样的,但是布局不同。 我们的行和列的词汇简直不够丰富,无法描述为什么这两个表代表相同的数据。 除了外观,我们还需要一种方法描述表中显示的值的基础语义或含义。
2.整洁数据的特征
2.1 数据结构
大多数统计数据集是由行和列组成的矩形表。 列几乎总是标记,行有时标记。 表1提供了一些数据关于野外常见的假想实验。 桌上有两个列和三行,以及行和列都标记。有许多方法可以构建相同的底层数据。 表2显示了相同的数据如表1所示,但行和列已被转置。 数据是一样的,但是布局不同。 我们的行和列的词汇简直不够丰富,无法描述为什么这两个表代表相同的数据。 除了外观,我们还需要一种方法描述表中显示的值的基础语义或含义。
2.2 数据语义
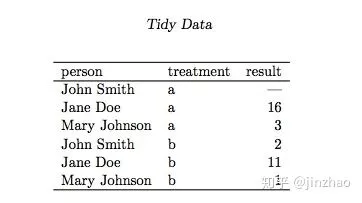
数据集是值的集合,通常是数字(如果是定量的)或字符串(如果定性)。 任何变量都以两种方式组织。 每个值都属于一个变量和一个观察。 变量包含测量相同基础属性的所有值(如高度,温度,持续时间)跨单位。 观察包含测量的所有值跨属性的相同单元(如人,或日,或种族)。表3重新组织表1,使值,变量和观察结果更加清晰。该数据集包含18个值,表示三个变量和六个观察值。 变量是:
1. 字符串:一个人, 有3个变量组成 (John Smith, Mary Johnson, and Jane Doe).
2. 因子:处理方式, 可能有两个方式(a and b).因子
3. 连续值:结论,5到6个值(其中null值)
实验设计告诉我们更多有关观测结构的信息。 在这个实验中,测量了人和治疗的每个组合,完全交叉设计。 实验设计还确定是否可以安全地将丢失缺失值减少。 在此实验中,缺失值表示应该具有的观察值已经测量,或者不是,所以保持它是很重要的。结构缺失值,代表不能进行的测量(例如,怀孕男性的数量)可以是放心的除去。对于给定的数据集,通常很容易弄清楚什么是观察和什么是变量,但一般来说,精确定义变量和观察结果是非常困难。例如,如果表1中的列是高度和重量,我们会很理所当然称他们为变量。如果列是高度和宽度,那么导致切割就不那么清晰了,我们可能会将高度和宽度视为维度变量的值。如果列是家庭电话和工作电话,我们可以将这些视为两个变量,但在欺诈检测中环境我们可能想要变量电话号码和数字类型,因为使用一个多人的电话号码可能暗示欺诈。一般的经验法则是它更容易描述变量之间的函数关系(例如,z是线性组合x和y,密度是重量与体积之比),而不是行之间,并且更容易在观察组之间进行比较(例如,组a的平均值与组b平均值,相对组列之间而言。
在给定的分析中,可能存在多个级别的观察。例如,在新的试验中过敏药物我们可能有三种观察类型:从中收集的人口统计数据每个人(年龄,性别,种族),每天从每个人收集的医疗数据(打喷嚏,眼睛发红),以及每天收集的气象数据(温度,花粉计数)。
2.3 整洁的数据
整洁数据就是将数据集的含义映射到其结构的标准方法。 数据集是凌乱或整洁,取决于行,列和总表如何与观察结果、变量和类型相匹配。 整洁的数据符合以下标准:
1.每个变量形成一列。
2.每个观察形成一排。
3.每种类型的观察单位都形成一张表格。
这是Codd的第三范式,但在此基础上,统计学中有变通的限制,重点放在单个数据集,而不是许多连接的数据集上在关系数据库(如mysql多表关联)。 凌乱的数据是数据的任何其他排列。表3是表1的整洁版本。每行代表一个观察结果,一个结果治疗一个人,每一列都是一个变量。整洁的数据使分析师或计算机可以轻松提取所需的变量,因为它提供了构建数据集的标准方法。比较表3和表1:表1您需要使用不同的策略来提取不同的变量。这减缓了分析和请求错误。如果您考虑有多少数据分析操作涉及a中的所有值变量(每个聚合函数),您可以看到提取这些值的重要性以简单,标准的方式。整洁的数据特别适合矢量化编程像R(R Core Team 2014)这样的语言,因为布局确保了不同的价值来自同一观察的变量总是成对的。虽然变量和观察的顺序不会影响分析,但是良好的排序会产生更容易扫描原始值。组织变量的一种方法是通过它们在分析中的作用:是由数据集合的设计确定的值,还是在过程中测量的值本实验?固定变量描述了实验设计并且事先已知。计算机科学家经常称固定变量维度,统计学家通常表示它们随机变量的下标。测量变量是我们实际测量的变量研究。应该首先使用固定变量,然后是测量变量,每个变量都是有序的相关变量是连续的。然后可以通过第一个变量对行进行排序与第二个和后续(固定)变量联系起来。这是所有人都采用的惯例本文中的表格显示。
3 整理凌乱的数据集
现实的数据集几乎可以通过几乎所有可想象的方式违反整洁数据的三个规则。虽然偶尔你会得到一个可以立即开始分析的数据集,但这是例外,而不是规则。
本节介绍凌乱数据集的五个最常见问题及其补救措施:
列标题是值,而不是变量名。
多个变量存储在一列中。
变量存储在行和列中。
多种类型的观察单位存储在同一个表中。
单个观察单元存储在多个表中。
令人惊讶的是,大多数凌乱的数据集,包括上面没有明确描述的混乱类型,可以用一小组工具来整理:熔化,字符串拆分和铸造( melting, string splitting, and casting)。以下部分说明了我遇到的真实数据集的每个问题,并说明了如何整理它们。
3.1 常见错误
1:列标题是值,而不是变量名
常见类型的凌乱数据集是为展现数据而设计的表格数据,其中变量形成行和列,列标题是值,而不是变量名。
虽然我会把这种安排称为凌乱,但在某些情况下它会非常有用。它提供完全交叉设计的高效存储,可以实现极其高效的计算,因为数据可以使用矩阵运算。这个问题在讨论中深度见第6节。表4显示了此表单的典型数据集的子集。该数据集探索了美国的收入和宗教之间的关系。它来自皮尤研究所制作的报告1中心,一个美国智库,收集有关宗教主题的态度数据到互联网,并生成许多包含此格式的数据集的报告。该数据集有三个变量,宗教,收入和频率。为了整理它,我们需要融化或堆叠。换句话说,我们需要将列转换为行。这样做被描述为制作宽或窄表,我将避免使用这些术语,因为它们是不精确。熔化由已经原表的列名转化为新表一列中的参数。简而言之。其他列转换为两个变量:一个名为income的一列,内容为原表列名,
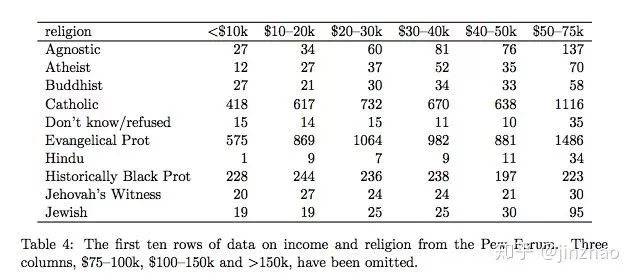
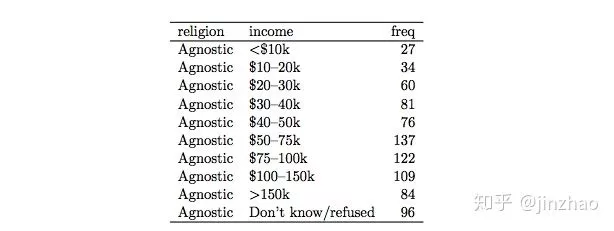
另一个名为frq的变量的值来自先原单独列的连接数据值。熔化的结果是熔融数据集。Pew数据集有一个colvar,宗教和熔化产量表6.为了更好地反映他们在这个数据集中的角色,变量列已经被重命名为income和value列到freq。此表单变得整洁,因为每列代表一个变量和每一行表示观察,在这种情况下是对应于组合的人口统计单位宗教和收入。该数据格式的另一个常见用途是记录随时间变化的规则间隔观测值。例如,表7中显示的Billboard数据集记录了歌曲首次输入的日期Billboard Top 100.它包含艺术家,曲目,日期,排名和星期的变量。该进入前100名后每周的排名记录在75列中,wk1到wk75。如果是一首歌在不到75周的时间内进入前100名,其余列填充了缺失值。这种存储形式不是很整洁,但它对于数据输入很有用。它减少了重复则每周的每首歌都需要自己的行,歌曲元数据就像标题和艺术家需要重复。这个问题将在3.4节中进行更深入的讨论。此数据集包含colvars year,artist,track,time,date,entered。
往期回顾
初学者如何避免bug:RStudio代码实时错误提示功能
如何在RStudio中预览数据
用RStudio导入数据
RStudio控制台“撸”代码的奇技淫巧?
其实你根本不懂RStudio的用心良苦!
R Markdown 简介
R Markdown与RStudio IDE深度结合

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
