作者介绍:蔡主希,目前就职于京东金融-金融科技业务部,哥大统计数据狗,京东金融算法工程狮,可代码可软文的非典型理科男一枚,知乎号: @JovialCai,数据森麟公众号(ID:shujusenlin)特邀作者
本文转载自公众号数据森麟
本文首发于知乎(作者:京东金融)
链接:https://zhuanlan.zhihu.com/p/42204964
欢迎各位同学回来,本文承接上周发表的文章:统计思维如何帮助大数据应用从人工走向智能?(上),感兴趣的同学可以去了解下。
在本文上半部分中,笔者主要总结了自己的Advisor郑甜教授关于统计思维的讲座内容。而在下半部分中,笔者将分享统计思维在京东金融建模场景中的应用,尤其是在金融科技对外输出这一块。
金融科技作为国内互联网公司近年来新兴的业务场景,与自然语言处理、图像识别一样,都是大数据算法应用的试验田。但是与后两者场景中深度学习等“黑箱”模型大规模应用并且取得显著成果不同,金融科技领域中的高级算法应用一直处于瓶颈阶段,效果和接受度都不被认可,笔者认为有如下几个原因。
(1) 金融业务产生的数据与语音、文本、图像类问题相比属于小数据问题。
通常银行或者大型互金公司的全量数据集在百万条左右,考虑到数据质量、成熟度、安全性等问题,可供训练模型的数据集就更少了。基于有限的训练集,深度学习等复杂网络算法容易产生过拟合,导致模型的泛化能力不强。
(2) 金融模型的底层特征难以获取。
对于文本和图像问题,深度学习中有embedding和convolution两大神器,可以通过高维空间映射的方式自动提取大量的数据特征。但是这两个方法在金融数据上的使用都存在一定局限性,首先自动提取的特征在业务上难以解释,其次金融客户行为属性的差异会导致映射后的特征矩阵稀疏,这两点都会影响模型的预测效果。而传统的机器学习依赖于特征工程,需要丰富的数据源和人工经验支持。
(3) 金融客户对于模型的可解释性要求高。
由于对外输出的金融科技模型主要服务于传统的银行、保险等金融机构,受到监管部门的压力,B端客户对于模型可解释性的要求极高,使得“黑箱”模型难以在真正落地场景中推广。目前金融行业主流的模型还是逻辑回归,树类模型慢慢在被传统金融机构接受中。
基于以上几点,统计思维在金融科技模型中的应用就显得尤为重要。因为统计思维可以帮助分析人员透过数据现象找到背后规律的本质,得到更稳定、解释性更强的模型。同时统计学中的一些理论知识和检验手段,可以适当地打开深度学习模型的“黑箱”,找到神经网络与传统机器学习算法结合的平衡点。
以下分享几个笔者在实际工作中利用统计思维优化模型的案例。
1. 选取稳定的训练集:
在机器学习建模问题中,训练集的选取至关重要。一个好的训练集,应该能够尽可能的刻画未来我们要预测的场景,这样训练出来的模型才能够具有比较强的泛化能力。在实际问题中,许多业务都存在刚起步阶段经营策略调整频繁的问题,反应到数据中就是存在着一定的随机性,因而利用统计思维尽可能排除早期数据积累中的噪声、筛选出稳定的训练集就非常有意义。
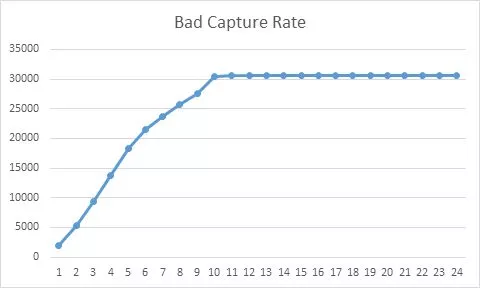
以信贷风控模型为例,我们将京东借钱平台历史上发生过逾期30+天作为坏人定义,那么如何筛选出稳定的训练集来搭建模型呢?“一头一尾”两个方面考虑。从“头”的角度,早期借钱平台放款笔数较少,并且风控策略仍在试探阶段,因而导致这些数据中坏人规律性不强。我们利用统计分布,观察借钱平台上各个资方各个申请月份新增贷款用户的坏人占比,找出业务前期坏人分布异常的资方或者申请月份数据删除。从“尾”的角度,信贷场景中的客户还款行为需要一定时间的表现期,表现期过短也会导致客户的贷后表现不充分,从而表现出错误的坏人规律,这里坏人捕获率曲线可以帮助我们确定整个信贷平台的账龄成熟期。
如下图所示,曲线上每个点表示截止到当前期数的累计坏人数,第9期以后累计坏人数增长趋于平缓,说明9个月是京东借钱平台的整体账龄成熟期,距今9个月内的申请数据都不能作为训练集。
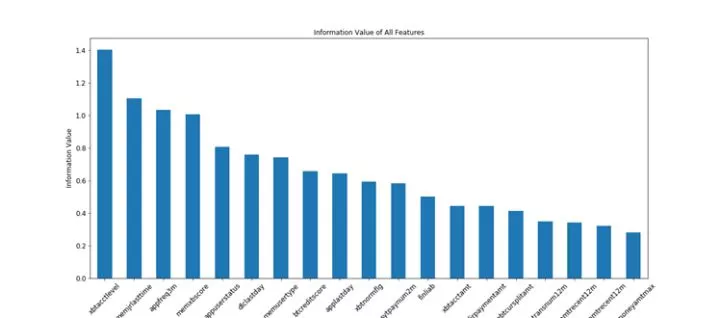
2. 层层筛选模型特征:
3. 划分并搭建子模型:
机器学习中经典的No Free Lunch Theorem(Wolpert,1996)告诉我们,在不考虑具体问题的情况下,没有一个机器学习算法总是比其他的更优。因此,在一个特定的概率分布上,才有可能设计出性能良好的机器学习模型,这也就是在实际问题中搭建子模型的出发点所在。只有利用严谨的统计思维,才能将一个复杂的数据问题拆解成多个小问题来解决。对于京东借钱平台上的风控模型,由于不同的资方风险偏好不同,需要根据资方属性搭建多个子模型,从而预测客户在不同资方贷款申请的逾期概率并给出合理的定价。目前借钱风控模型分为银行和小贷两个子模型,其中银行子模型适用于日利率0.03%-0.06%的银行、消费金融贷款产品,这部分资方可以调取申请客户的央行征信报告并且整体逾期率较低;而小贷子模型适用于日利率0.06%-0.1%的小贷公司贷款产品,这部分资方能够接受风险评分较低的客户,但是同时需要较高的利率定价来弥补资金损失。在实际数据测试中,子模型通常可以比通用模型ks提高0.03-0.05。
以上就是笔者从哥大论坛和实际工作案例中总结的一些关于统计思维的思考。人工智能算法发展到今日,数据工作者们的关注重心也从单纯的模型结果逐步转向预测的过程。加入更多的统计思维,提高模型的精细度和智能化,是笔者认为人工智能走向下个阶段的必由之路。
往期回顾:
卫视实时收视率对比 | R爬虫&可视化第1季
当古代文人参加“中国好诗人”节目 | R爬虫&可视化第2季
同花顺股票分数可视化 | R爬虫&可视化第3季
近三十年6000部国产电视剧告诉了我们些什么 | R爬虫&可视化第四季
R爬虫&可视化第五季-图解欧洲足球五大联赛
爬虫告诉你, 互联网大数据行业有多赚钱!
透过日播放量超过6亿的《延禧攻略》,看2018视频网站格局
统计思维如何帮助大数据应用从人工走向智能?(上)

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
