作者:young2415 Python爱好者社区专栏作者
博客:https://blog.csdn.net/young2415
这篇文章是我的上一篇文章从中秋节福利说起,Python可以有这种操作!的改良版,主要是对代码进行了改良。还有就是那篇文章写得比较仓促,思路描述的不够清晰,今天正好趁着中秋节假期再重新整理一下发出来。
事情是这样的,中秋节假期前的某一天下午,我突然接到了女朋友的紧急求助电话,让我帮她做一个表格。
我正纳闷儿是怎么回事,仔细一听,原来中秋节要到了,女朋友单位准备给员工发福利,福利分4个档次,不同档次的福利包含的东西不尽相同,每个部门的员工都有不同档次的福利。现在已经有了两个Excel表格,一个是员工信息表,表中记录了每个员工的所属部门以及该员工应该发放哪个档次的福利;另一个是福利明细表,表中显示了每个档次的福利应该包含什么东西。单位领导让我女朋友她们部门统计一下每个部门分别要买多少东西,汇总到一个表格上面,然后去采购。女朋友给我打电话时已经快到下班的点儿了,领导要求下班之前必须汇总出来,不得已她才向我求助。
作为一个程序员以及Python的死忠粉,这点小事当然难不倒我,确切的说是难不倒Python,当然这都不重要,重要的是,这可是在女朋友面前表现的大好机会啊!内心不禁窃喜~
先来分析一下需求,现有的两张表格长这样:
员工信息表,文件名叫做details.xlsx,这张表我只截了一部分,总共有200多名员工

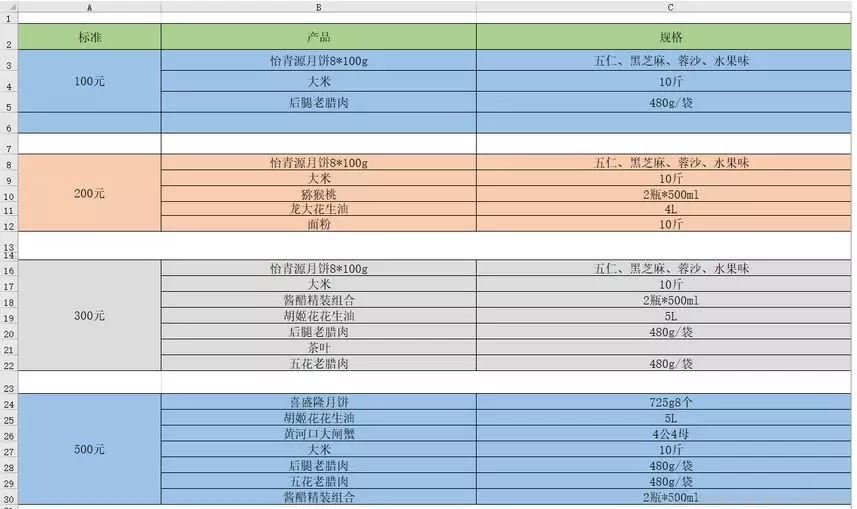
福利明细表,文件名是welfare.excel,100元的是4档福利,200元的3档福利,300元的是2档福利,500元的是1档福利
我要做的就是统计每个部门每样东西各需要几个,然后做成一张表,这张表应该是这样的:
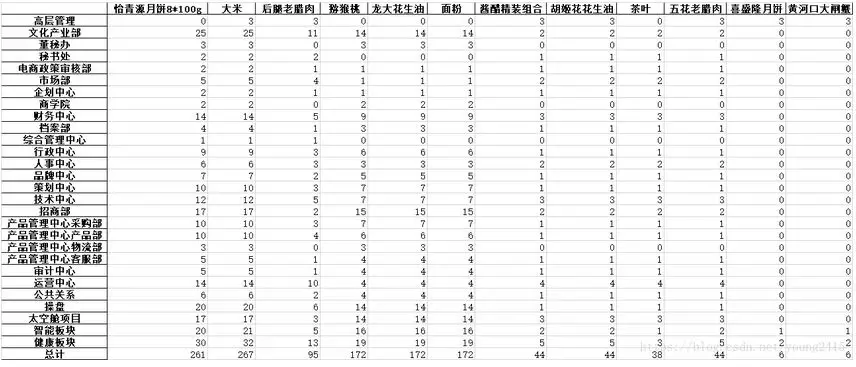
这是我最终做出来的成果,提前放到这里。接下来我们一步步介绍如何做到。
正如前面所说,我要用Python来完成这件事,具体一些,就是用现在特别流行的数据分析库pandas。我的思路是:
1. 提取员工信息表中的“部门”和“备注”这两列的信息
#导入pandas库
import pandas as pd
# 文件路径
Location1 = r'details.xlsx'
# 读取detail.xlsx的第C列和第H列,即员工所在部门和员工的福利档次
df_details = pd.read_excel(Location1, usecols="C, H", names=['department','welfare_level'])

2. 提取福利明细表中的“标准”和“产品”这两列的信息
Location2 = r'welfare.xlsx'
# 读取welfare.xlsx的第A列和第B列,每个档次的福利的价格标准和物品
df_welfare = pd.read_excel(Location2, usecols="A, B", names=['price', 'content'])
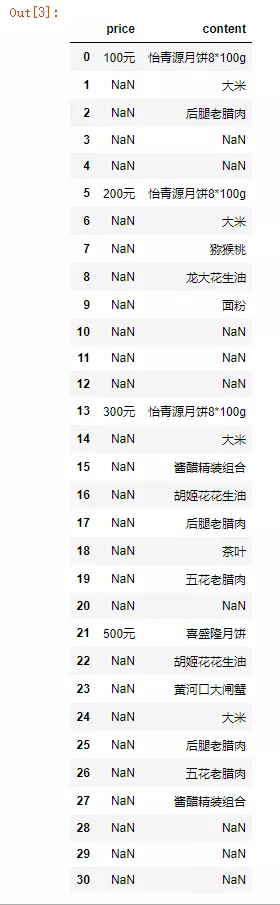
我们发现,在福利信息表中提取的数据中有一些“NaN”,这些“NaN”是空值的意思,现在我们要去掉这些空值。
3. 清洗数据
#去掉df_welfare中content值为空的行
df_welfare = df_welfare[df_welfare.content.isnull() == False]
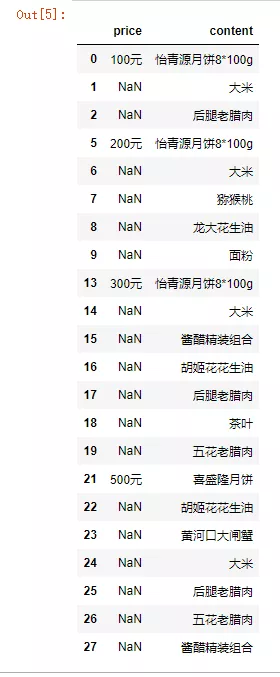
刚才只是去掉了content中的空值,但是price中还有空值,这些空值不能去掉,需要填充,从welfare.xlsx中可以得知,序号0 ~ 2是4档福利,5~9是3档福利……以此类推,那么我们需要把price那一列的值换成1 ~ 4之间的值,代表福利档次,以便和前面的员工信息表进行合并。
#填充空值,参数method=‘ffill’是告诉函数向前填充
df_welfare = df_welfare.fillna(method='ffill')
填充完之后,df_welfare里面的值是这样的:

然后我们要把“100元”换成“4”,把“200元”换成“3”……以此类推,然后将price那一列的列名改为“welfare_level”。该列名是为了和df_details有共同的列名,这样才能合并。
##获取到所有的不重复的价格
price = list(df_welfare.price.dropna().unique())
#这一步是为了让price的元素的序号与福利档次相对应,比如1档福利的价格就是price[1],即500元;2档福利的价格就是price[2],即300元
price.append(None)
price.reverse()
#替换
for i in range(1, len(price)):
df_welfare = df_welfare.replace(price[i], i)
#将price那一列的列名改为“welfare_level”
f_welfare.rename(columns={'price':'welfare_level'}, inplace = True)
替换之后是这样的:

4. 合并,分组
这样我们就可以将两张表进行合并了,合并之后在最右边增加一列“quantity”,值都是1,表示物品的数量,这样便于稍后计算总数。
#合并df_details和df_welfare
summary = df_details.merge(df_welfare)
#增加一列,每个物品的数量都是1
summary['quantity'] = 1
合并之后:
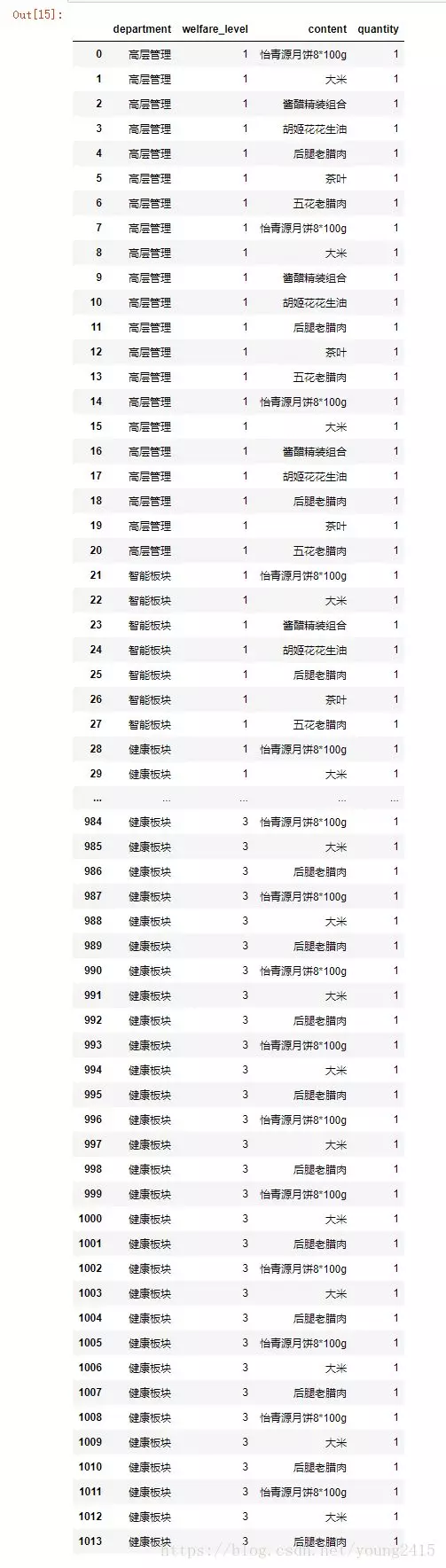
对数据进行分组:
#多层次分组
gp_dp = summary.groupby(['department', 'content']).sum()
#去掉多余的列
del gp_dp['welfare_level']
分组之后:

5. 创建表格,填充数据
在创建表格之前,我们先创建一个DataFrame对象,存储我们想要的数据,然后再把数据写入Excel表格中。
#获取到所有的不重复的部门名称
department = df_details.department.unique()
#获取到所有的不重复的物品名称,dropna函数的功能是去掉序列中的空值
materials = df_welfare.content.dropna().unique()
result = pd.DataFrame(index = department, columns = materials)
result的值目前还全部为空
接下来把数据填充到result中:
for i in department:
for j in materials:
try:
result.loc[i][j] = int(gp_dp.loc[i].loc[j])
except KeyError:
result.loc[i][j] = 0
填充之后,result里面的数据:
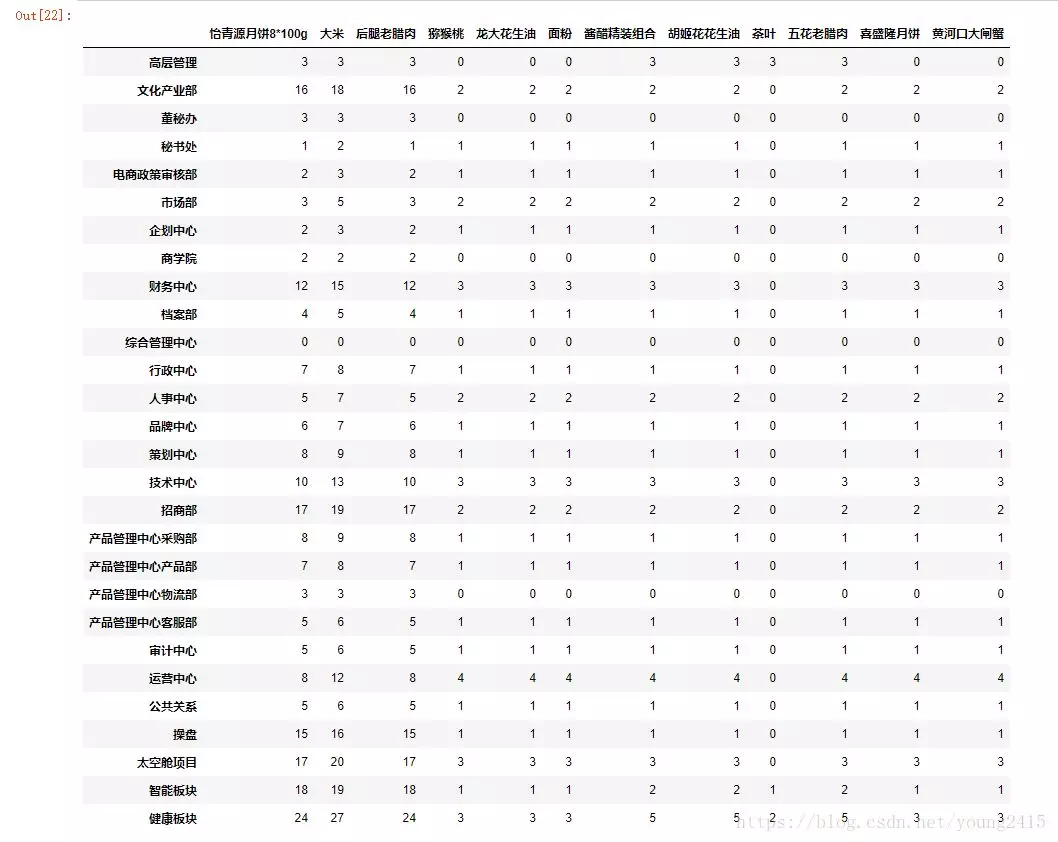
做到这里,基本上算是大功告成了,但是我一看表,时间还早,那就再顺手帮我女朋友计算一下每样物品总共需要多少件吧。
#基于“content”进行分组
gp_con = summary.groupby(['content']).sum()
del gp_con['welfare_level']
#新建一个DataFrame
total = pd.DataFrame(index = ['总计'], columns = materials)
#将total添加到result末尾
result = result.append(total)
for i in materials:
result.loc['总计'][i] = int(gp_con.loc[i])
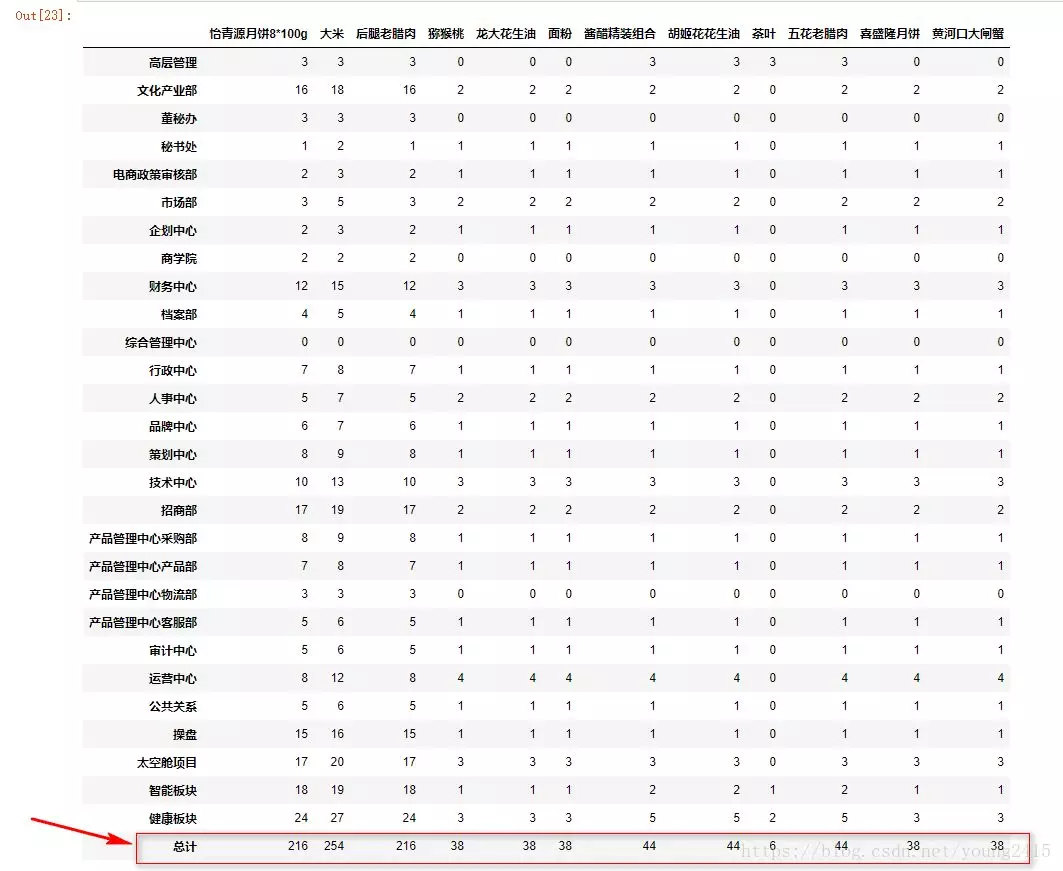
Perfect!最后要做的就是把result导出为Excel文件。
result.to_excel("result.xlsx", index = "department")
以下是完整代码:
#导入pandas库
import pandas as pd
# 文件路径
Location1 = r'details.xlsx'
# 读取detail.xlsx的第C列和第H列,即员工所在部门和员工的福利档次
df_details = pd.read_excel(Location1, usecols="C, H", names=['department','welfare_level'])
Location2 = r'welfare.xlsx'
# 读取welfare.xlsx的第A列和第B列,每个档次的福利的价格标准和物品
df_welfare = pd.read_excel(Location2, usecols="A, B", names=['price', 'content'])
#去掉df_welfare中content值为空的行
df_welfare = df_welfare[df_welfare.content.isnull() == False]
#填充空值,参数method=‘ffill’是告诉函数向前填充
df_welfare = df_welfare.fillna(method='ffill')
df_welfare
##获取到所有的不重复的价格
price = list(df_welfare.price.dropna().unique())
#这一步是为了让price的元素的序号与福利档次相对应,比如1档福利的价格就是price[1],即500元;2档福利的价格就是price[2],即300元
price.append(None)
price.reverse()
#替换
for i in range(1, len(price)):
df_welfare = df_welfare.replace(price[i], i)
#将price那一列的列名改为“welfare_level”
df_welfare.rename(columns={'price':'welfare_level'}, inplace = True)
#合并df_details和df_welfare
summary = df_details.merge(df_welfare)
#增加一列,每个物品的数量都是1
summary['quantity'] = 1
#多层次分组
gp_dp = summary.groupby(['department', 'content']).sum()
#去掉多余的列
del gp_dp['welfare_level']
#获取到所有的不重复的部门名称
department = df_details.department.unique()
#获取到所有的不重复的物品名称,dropna函数的功能是去掉序列中的空值
materials = df_welfare.content.dropna().unique()
result = pd.DataFrame(index = department, columns = materials)
for i in department:
for j in materials:
try:
result.loc[i][j] = int(gp_dp.loc[i].loc[j])
except KeyError:
result.loc[i][j] = 0
#基于“content”进行分组
gp_con = summary.groupby(['content']).sum()
del gp_con['welfare_level']
#新建一个DataFrame
total = pd.DataFrame(index = ['总计'], columns = materials)
#将total添加到result末尾
result = result.append(total)
for i in materials:
result.loc['总计'][i] = int(gp_con.loc[i])
result.to_excel("result.xlsx", index = "department")
我把文章中用到的两个Excel文件放到了百度网盘上 ,大家可以下载下来使用,不过我把一些涉及到隐私的信息删除了,因此开头读取数据时的代码可能需要稍作改动,不过影响不大,相信大家能够搞定。
公众号后台回复中秋福利获取本文Excel文件。

Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门免费视频课程!!!
【最新免费微课】小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。

