作者简介:
Treant 人工智能爱好者社区专栏作者
博客专栏:https://www.cnblogs.com/en-heng
前言
分类与回归树(Classification and Regression Trees, CART)是由四人帮Leo Breiman, Jerome Friedman, Richard Olshen与Charles Stone于1984年提出,既可用于分类也可用于回归。本文将主要介绍用于分类的CART。CART被称为数据挖掘领域内里程碑式的算法。
不同于C4.5,CART本质是对特征空间进行二元划分(即CART生成的决策树是一棵二叉树),并能够对标量属性(nominal attribute)与连续属性(continuous attribute)进行分裂。
2. CART生成
前一篇【十大经典数据挖掘算法】Naïve Bayes提到过决策树生成涉及到两个问题:如何选择最优特征属性进行分裂,以及停止分裂的条件是什么。
特征选择
CART对特征属性进行二元分裂。特别地,当特征属性为标量或连续时,可选择如下方式分裂:
An instance goes left if CONDITION, and goes right otherwise
即样本记录满足CONDITION则分裂给左子树,否则则分裂给右子树。
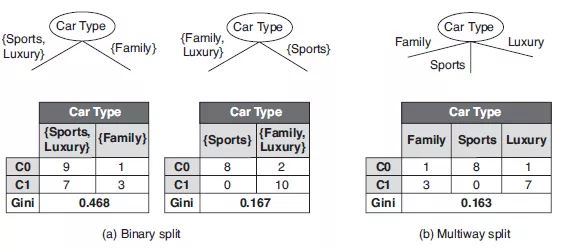
标量属性
进行分裂的CONDITION可置为 ;比如,标量属性
;比如,标量属性 取值空间为
取值空间为 ,二元分裂与多路分裂如下:
,二元分裂与多路分裂如下:
连续属性
CONDITION可置为不大于ε;比如,连续属性 ,
,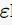 取属性相邻值的平均值,其二元分裂结果如下:
取属性相邻值的平均值,其二元分裂结果如下:
接下来,需要解决的问题:应该选择哪种特征属性及定义CONDITION,才能分类效果比较好。CART采用Gini指数来度量分裂时的不纯度,之所以采用Gini指数,是因为较于熵而言其计算速度更快一些。对决策树的节点 t ,Gini指数计算公式如下:

Gini指数即为1与类别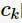 的概率平方之和的差值,反映了样本集合的不确定性程度。Gini指数越大,样本集合的不确定性程度越高。分类学习过程的本质是样本不确定性程度的减少(即熵减过程),故应选择最小Gini指数的特征分裂。父节点对应的样本集合为D,CART选择特征A分裂为两个子节点,对应集合为
的概率平方之和的差值,反映了样本集合的不确定性程度。Gini指数越大,样本集合的不确定性程度越高。分类学习过程的本质是样本不确定性程度的减少(即熵减过程),故应选择最小Gini指数的特征分裂。父节点对应的样本集合为D,CART选择特征A分裂为两个子节点,对应集合为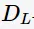 与
与 ;分裂后的Gini指数定义如下:
;分裂后的Gini指数定义如下:
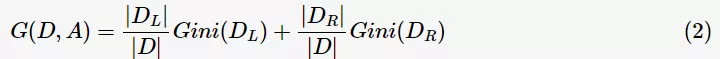
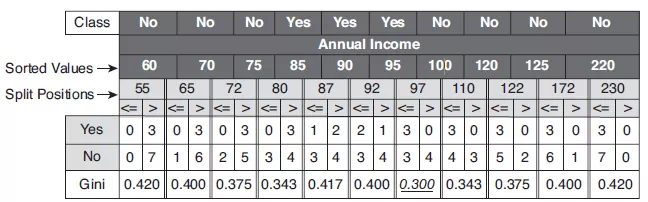
其中, 表示样本集合的记录数量。如上图中的表格所示,当Annual Income的分裂值取87时,则Gini指数计算如下:
表示样本集合的记录数量。如上图中的表格所示,当Annual Income的分裂值取87时,则Gini指数计算如下:
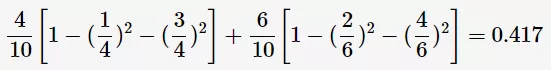
CART算法
CART算法流程与C4.5算法相类似:
3. CART剪枝
CART剪枝与C4.5的剪枝策略相似,均以极小化整体损失函数实现。同理,定义决策树T的损失函数为:
 其中,C(T)表示决策树的训练误差,α为调节参数,|T|为模型的复杂度。
其中,C(T)表示决策树的训练误差,α为调节参数,|T|为模型的复杂度。
CART算法采用递归的方法进行剪枝,具体办法:
如何计算最优子树为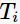 呢?首先,定义以t为单节点的损失函数为
呢?首先,定义以t为单节点的损失函数为
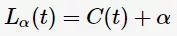
以t为根节点的子树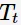 的损失函数为
的损失函数为
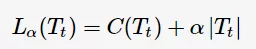
令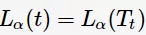 ,则得到
,则得到
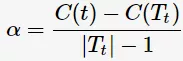
此时,单节点t与子树 有相同的损失函数,而单节点t的模型复杂度更小,故更为可取;同时也说明对节点 t 的剪枝为有效剪枝。由此,定义对节点 t 的剪枝后整体损失函数减少程度为
有相同的损失函数,而单节点t的模型复杂度更小,故更为可取;同时也说明对节点 t 的剪枝为有效剪枝。由此,定义对节点 t 的剪枝后整体损失函数减少程度为
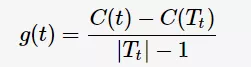
剪枝流程如下:
关于CART剪枝算法的具体描述请参看[1],其中关于剪枝算法的描述有误:
(6)如果T不是由根节点单独构成的树,则回到步骤(4)
应改为 ,要不然所有α均一样了。
,要不然所有α均一样了。
(注:李航老师已经在勘误表给出修改了。)
4. 参考资料
[1] 李航,《统计学习方法》.
[2] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
[3] Dan Steinberg, The Top Ten Algorithms in Data Mining.
往期回顾:
【十大经典数据挖掘算法】C4.5
【十大经典数据挖掘算法】k-means
【十大经典数据挖掘算法】SVM
【十大经典数据挖掘算法】Apriori
【十大经典数据挖掘算法】EM
【十大经典数据挖掘算法】PageRank
【十大经典数据挖掘算法】AdaBoost
【从传统方法到深度学习】图像分类
【十大经典数据挖掘算法】kNN
【十大经典数据挖掘算法】Naïve Bayes
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

 ,计算得到对应于区间
,计算得到对应于区间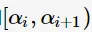 的最优子树为
的最优子树为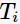 ;
; 选出最优的(即损失函数最小的)。
选出最优的(即损失函数最小的)。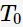 ,自上而下计算内部节点的g(t);选择最小的g(t)作为
,自上而下计算内部节点的g(t);选择最小的g(t)作为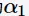 ,并进行剪枝得到树
,并进行剪枝得到树 ,其为区间
,其为区间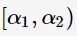 对应的最优子树。
对应的最优子树。 ,再次自上而下计算内部节点的g(t);
,再次自上而下计算内部节点的g(t);
