训练误差和泛化误差
在训练集上的误差称为训练误差或者经验误差,在新样本上的误差称为泛化误差。
误差评估方法
使用测试集来测试学习期对新样本的判别能力,然后以测试集上的测试误差作为泛化误差的近似。需要注意一点:测试集尽量与训练集互斥。
1.留出法
直接将数据集D划分为两个互斥的集合,一个集合为训练集S,另一个集合为测试集T,这时就满足关系D=S并T,S交T=空集。
需要注意的是:训练集和测试集尽量保持数据分布一致。
在使用留出法时,一般采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
一般情况下,2/3~4/5的样本用于训练。
2.交叉验证法
将数据集划分为K个大小相似的互斥子集,每个子集尽可能保持数据分布的一致性,然后将其中的K-1个子集的并作为训练集,剩下一个子集作为测试集,这样就可以获得K组训练集/测试集,最终返回这K个测试结果的均值。这就是K折交叉验证,通常K取5,10,20。
与留出法相似,将数据集划分为K个子集的过程中存在多种划分方式,为了减小因样本划分不同而引入的差别,K折交叉验证通常要随机使用不同的划分重复P次,最终评估结果是这P次K折交叉验证结果的均值,例如常见的10次10折交叉验证。
当有M个数据,这时使K=M,就是一种交叉验证的特例,留一法。这种方法往往被认为是比较准确的,但是当样本很多时时间开销特别大,因此并不适合大样本数据。
3.自助法
以自助采样法为基础,减少训练样本规模不同造成的影响,同时比较高效的进行实验估计。
假设对于有m个数据的数据集D,我们采样生成的数据集Q,这个采集过程是这样的:每次随机从D中选取一个样本放入Q中,然后再将它放回D中,使得这个样本仍然有机会被采集到;这个过程重复进行m次之后,就得到包含m个数据的Q,即自助采样的结果。
可以估算出样本在m次采样中始终不被采集到的概率是: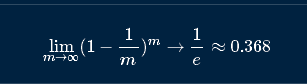
这里使用Q为训练集,D-Q(集合之间做的减法)作为测试集,这样实际估计的模型和期望评估的模型都使用m个训练样本,剩余的占数据总量约1/3没在训练集中出现的数据用于测试,这样的测试结果称为“包外估计”。需要明确的是,这里的训练集是抽出来的Q,而测试集是没有被抽中的那部分数据,千万不要搞错了!!!
自助法用于数据集较小,难以有效划分训练集测试集,此外这对集成学习很有帮助。
但是自助法产生的数据集改变了数据本身的分布,会引起估计误差。
因此,在初始数据量足够的强狂下,留出法和交叉验证法更常用。
4.调参与最终模型
我们用训练集训练完模型并用测试集测试后,学习算法和参数配置已经确定,这时应该用数据集D重新训练模型,这个模型使用了所有m个数据,这才是我们最终提交给用户的模型。
注意:通常把学得模型在实际中遇到的数据称为测试数据,为了加以区分,模型评估与选择过程中评估测试的数据集称为“验证集”。因此可以归结为我们把数据分为彩色文字训练集和验证集,最后在实际中遇到的数据称为测试集。
--读周志华的《机器学习》总结而来

