基础机器配置:MacBook Pro 其他机器可以搞个linux的虚拟机也一样。
1、下载flink安装文件:
路径:https://flink.apache.org/downloads.html
一种是下载与hadoop匹配的版本,一种是下载纯净的flink版本,
下面的是hadoop的全部版本,该案例下的是纯净版本:flink-1.5.2-src,没有使用hadoop绑定的版本,如果需要的话可以自己进行构建合适的版本。

2、解压安装flink:
flink部署一共有三种模式: Local(单机)、Standalone Cluster (独立集群)、Yarn Cluster(部署在yarn环境)
我们安装本地模式部署,进行flink的开发和学习。
解压文件到指定目录,可以切换到目录再进行解压:
tar zxf flink-1.5.2-bin-hadoop27-scala_2.11.tgz /usr/app/flink
解压之后找到flink目录,目录下的文件如下:
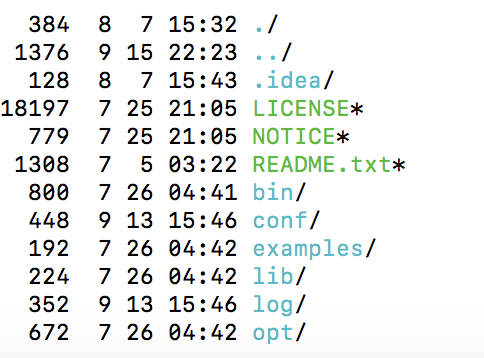
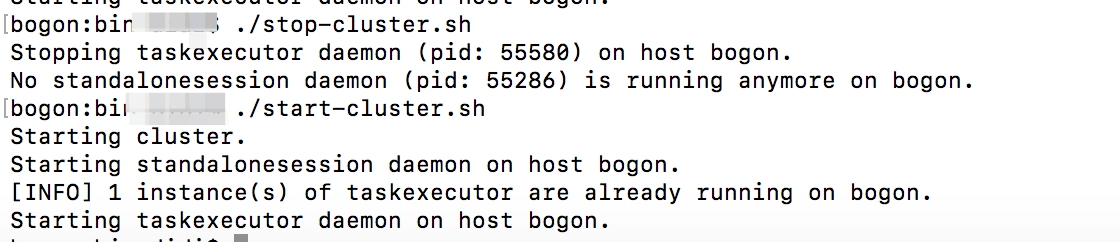
进入bin目录 ./start-cluster.sh,或者直接执行 ./bin/start-cluster.sh 启动flink程序。
正常启动信息如下:
3、ui后台:
flink正常启动之后可以打开:http://localhost:8081/#/overview
查看flink的后台系统,这个ui可以看到flink的任务及集群的运行情况。
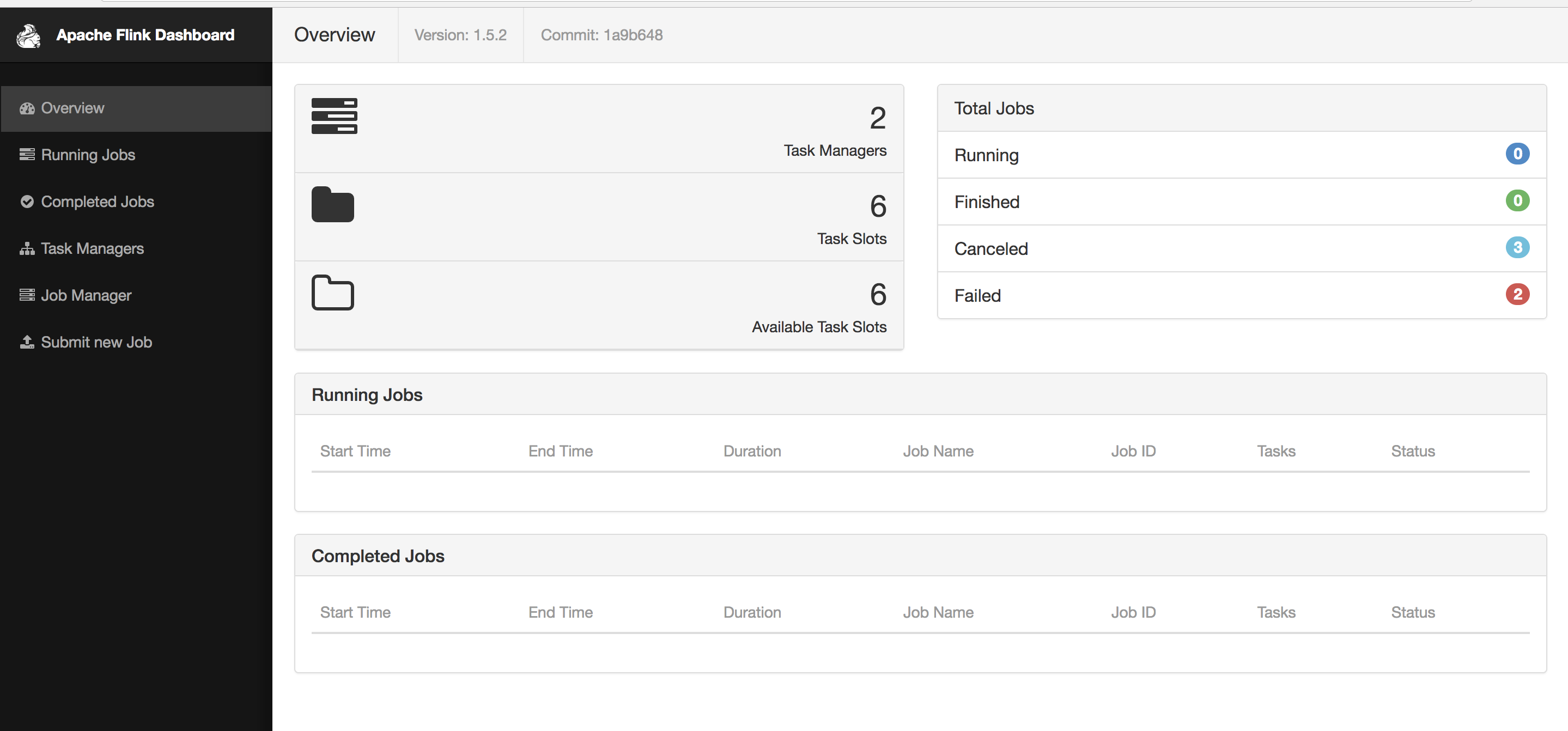
那么说明flink集群已经起来,可以正常运行了。
4、配置文件修改:
因为单机的flink默认的slots是0,你需要手动调整一下参数,例如:
设置:taskmanager.numberOfTaskSlots: 3
这样测试demo的时候不会报没有资源或者内存的错误了。

其他conf文件一版都是设置集群模式才需要设置。
