如附件中的数据所示:
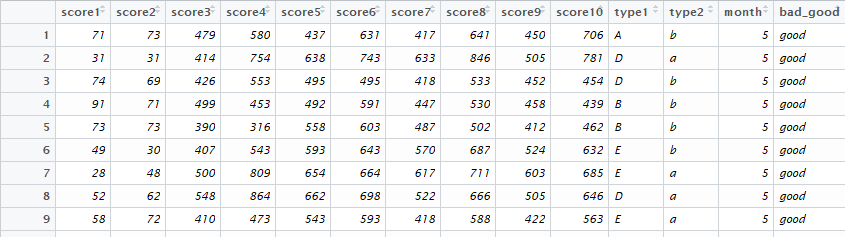
有10个score变量,现在需要探究这10个score与因变量bad_good之间的影响关系。
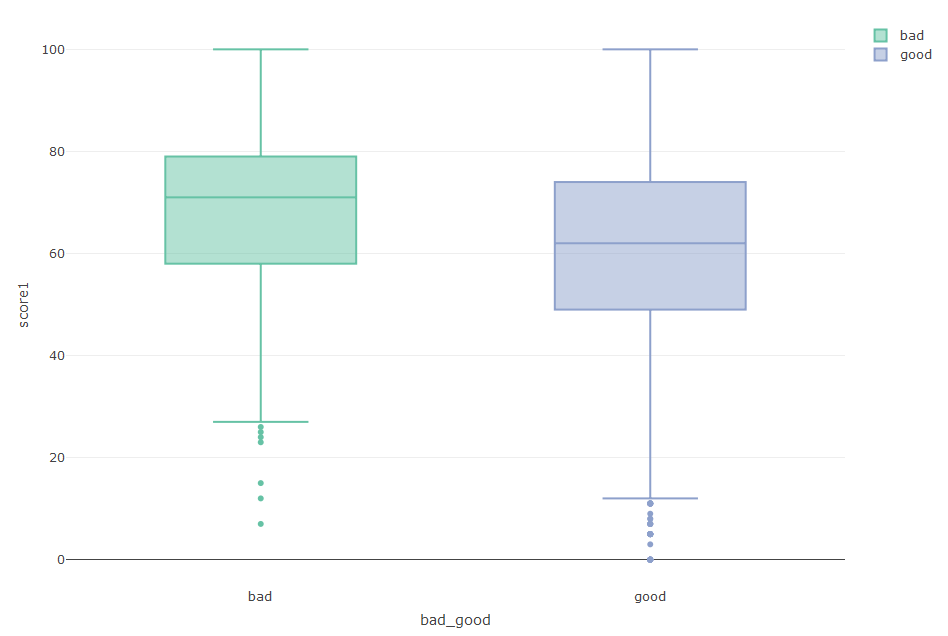
在这之前将每个score做纵坐标,bad_good做横坐标画箱线图,但是关系不是很明显,需要进一步展示他们之间的关系,如下图(以score1为例)。
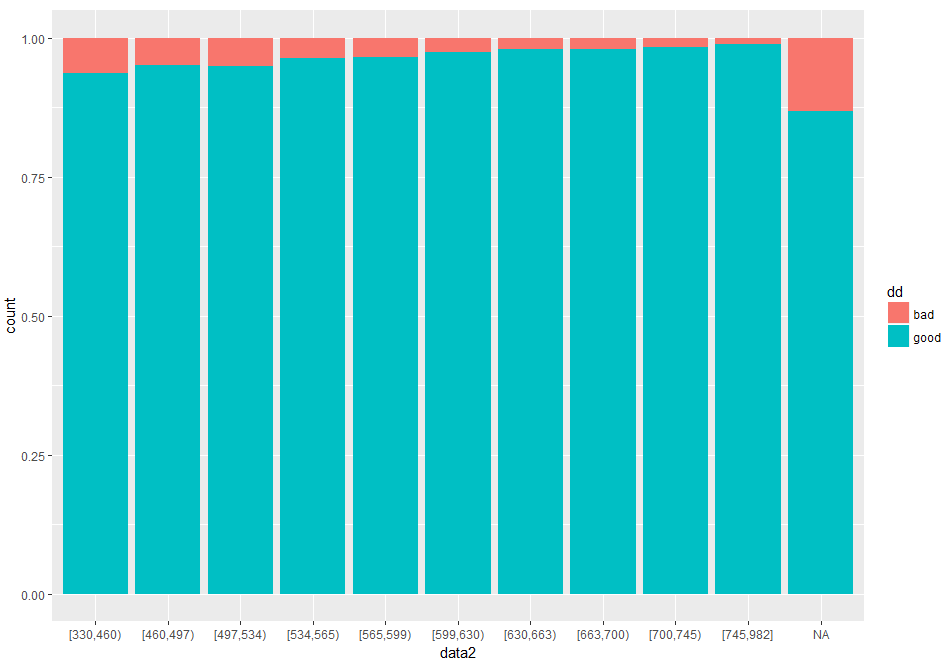
在探索更好的方法中,我首先将score从小到大排序,利用深度分箱将数据分成10段(深度分箱就是将数据分成想分成的组数,然后每个组的个数尽量相等,这是一种很好的将连续性数据离散化的方法,返回的是每个数据对应的区间,并且自动将缺失值排除在外。还有另一种分箱也可以将连续性数据离散化,具体的可以百度)然后按分组分别计算bad_good中bad和good的占比(ggplot2自动计算)然后画出柱状图,如下(以score10为例):
但是,我们关注的是bad对因变量的作用,因此我们只用将图的上半部分bad拿出来画柱状图,另外,要看去世的话,折线图最好用,因此这里再将bad那部分的柱状图画成折线图的形式,同样,这里我也封装了一个函数,下次可以直接使用:
mygraghfun <- function(data_analysis, independent_variable, dependent_variable, attention){
#注:
# data_analysis是待分析的数据
# independent_variable是需要画图的自变量
# dependent_variable是需要展示的因变量
# attention是因变量中需要重点展示的水平
#用函数的时候以这种形式输入:mygraghfun(loandata, "score10", "bad_good", "bad")
data_arrange <- data_analysis %>%
arrange(eval(parse(text = independent_variable)))
#对连续性自变量进行排序
library(Hmisc)
data_cut <- data_arrange %>%
select(independent_variable) %>%
unlist()%>%
cut2(g = 10)
#排序后的自变量进行深度分箱操作,分为10组(返回每个数据在的组别)
dependent <- data_arrange %>%
select(dependent_variable)
#提取排序后的数据中的因变量
data_bind <- data.frame(data_cut, dependent)
#将排序后的因变量和分割的数据合并
bad <- data_bind %>%
filter(eval(parse(text = dependent_variable)) == attention) %>%
group_by(data_cut) %>%
summarise(bad_n = n())
#计算每组中受关注度的数据总数
sum <- data_bind %>%
group_by(data_cut) %>%
summarise(sum_n = n()) %>%
select(sum_n) %>%
unlist()
#计算每组的总数
bad_need <- bad %>%
mutate(prob = bad_n/sum)
#添加新的一列:受关注变量分别占每组总的变量的比率
data_cut_factor_level <- bad_need %>%
select(data_cut) %>%
unlist() %>%
factor(exclude = FALSE)
#对分好组的自变量因子进行处理,使缺失值在因子水平中显示出来
bad_need %>%
ggplot(aes(x = data_cut, y = prob, group = 1)) +
geom_line(colour = "steelblue", size = 1) + #画折线
scale_y_continuous(labels = percent) + #将纵向刻度变为百分制
scale_x_discrete(limits = rev(levels(data_cut_factor_level))) + #横坐标因子逆序
geom_point(colour = "steelblue", size = 2) + #加入点图
geom_text(aes(label = percent(prob), hjust = 1)) + #将纵坐标换算成百分制
labs(x = independent_variable) + #修改横坐标标签
theme_dark() + #一种主题
theme(panel.background = element_blank(), #去掉背景色
panel.grid.major.x = element_blank(), #去掉纵轴线
panel.grid.minor.x = element_blank(), #去掉纵轴线
axis.text.x = element_text(angle = 30)) #横坐标标签旋转30度
}
mygraghfun(loandata, "score8", "bad_good", "bad")
需要用到的信息都在注释里边了。最后的完整代码在附件中也有
画出图的效果(以score10为例):
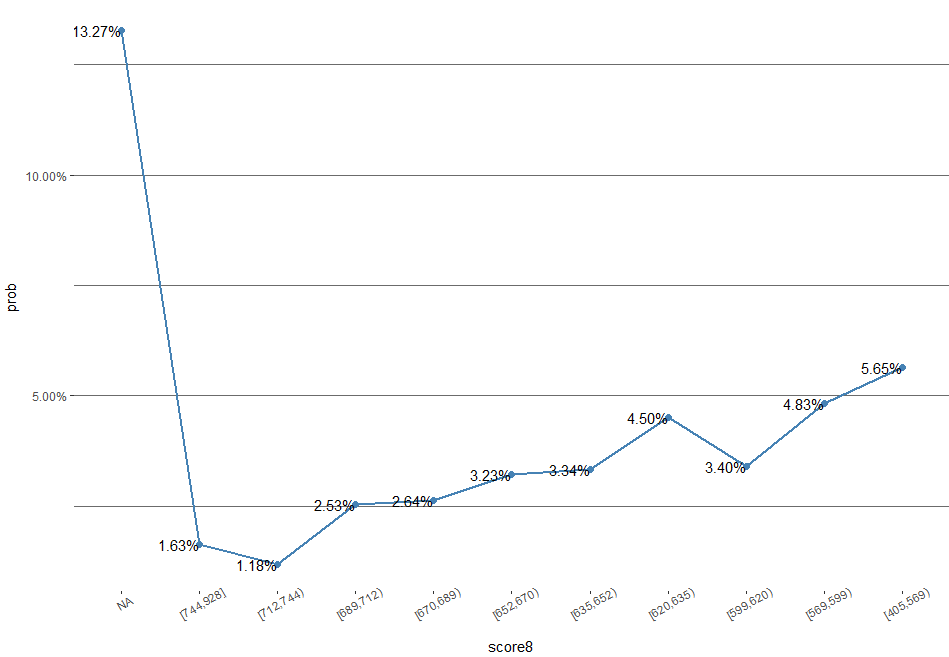
很明显,随着分数段增高,bad出现的概率更高,可以进一步探索信息。
