
上图中,我们最常用的就是TPR(True Positive Rate)和FPR(False Positive Rate):
其中:
TPR = TP/(TP+FN)即真实1中预测错的;
FPR = FP/(FP+TN)即真实0中预测错的;
Precision = TP/(TP+FP)即预测1中对的
最理想的模型,是TPR尽量高而FPR尽量低,然而任何模型在提高正确预测概率的同时,也会难以避免地增加误判率。听起来有点抽象,好在有ROC曲线非常形象地表达了二者之间的关系。
ROC曲线是以FPR为横轴,TPR为纵轴,在不同阈值下计算FPR和TPR的值画出的图形。这个不同阈值的设定可以是将[0,1]区间等分然后取阈值进行计算。当然这样会出现一个新的问题,假如某些概率只落在[0.0092,0.578]区间内时,那么将阈值取0.1到0.9时会出现ROC曲线后边的点都为(0,0),因此需要改进。
改进原理:将区间[0.0092,0.578]按照之前的等分划分方法划分为10份,然后再按不同阈值计算。
具体步骤:1.将(0,1)升级为(min(p),max(p))
2.取值(min(p),max(p))/10,设定阈值为(min(p),max(p))*k/10,其中k=1,......9
3.根据不同阈值计算的不同的(FPR,TPR)值
对于多个指标可以画出好几条ROC曲线,此时看AUC指标选优,AUC为ROC曲线下方的面积,值越大说明模型的分辨效果越好。
KS曲线与ROC有着相同的作用:
KS曲线是将概率从小到大进行排序,取10%的值为阈值,同理将10%*k(k=1,......9)处值作为阈值,计算不同的FPR和TPR,以10%*k(k=1,......9)为横坐标,同时分别以TPR和FPR为纵坐标画出两条曲线就是KS曲线。而KS值=|max(TPR-FPR)|。详细的可以参考网址:https://www.sohu.com/a/132667664_278472
另外,还有另一种计算KS值的方法:
将所有的样本根据分数值从低到高排序均分成20组,分别计算20组的实际好样本数、实际坏样本数、累积好样本数、累积坏样本数、累积好样本数占比、累积坏样本数占比、差值。其中,实际好坏样本数分别为该组内的好坏样本数;累积好坏样本数为该组累积好坏样本数;累积好坏样本数占比为累积好坏样本数占总好坏样本数的比值;差值为累积坏样本数占比 - 累积好样本数占比。KS值为差值绝对值的最大值,具体的可以从下方的表看:
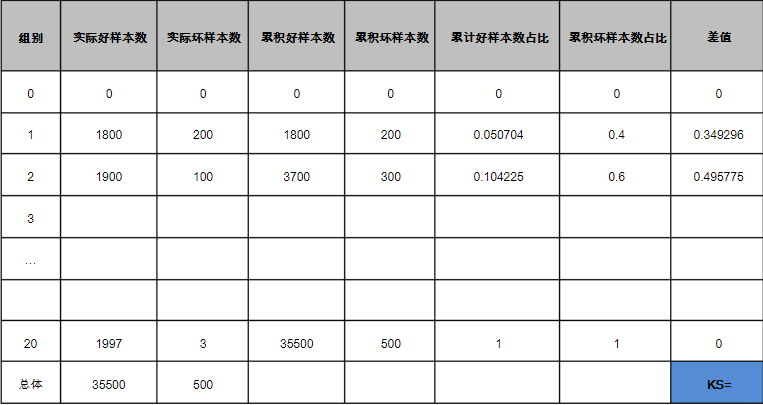
详细的可以参考网址:https://wenku.baidu.com/view/5f3e9c803c1ec5da51e2700e.html
在一个小案例中,为了方便计算10个变量的KS值自己定义了一个计算KS值的函数:
ks_value <- function(data_analysis, independent_variable, dependent_variable, level1, level2){
# 注:
# data_analysis是待分析的数据
# independent_variable是自变量
# dependent_variable是因变量
# level1是因变量中的一个因子水平
# level2是因变量中另一个因子水平
data_arrange <- data_analysis%>%
arrange(eval(parse(text = independent_variable)))
#将数据按照自变量从小到大排序
independent <- data_arrange %>%
select(independent_variable) %>%
unlist()
#筛选出排序后的自变量
cut_independent_variable <- cut2(independent, g = 20)
#对排序后的自变量进行深度分箱操作,分20组,并返回每个数据所在的组别
data_cut <- data.frame(data_arrange, cut_independent_variable)
#将返回的组别与排序后的所有数据放在一起
fact_level1 <- data_cut %>%
filter(eval(parse(text = dependent_variable)) == level1) %>%
group_by(cut_independent_variable) %>%
summarise(fact_level1 = n())
#分组计算出因子水平1的总数
fact_level2 <- data_cut %>%
filter(eval(parse(text = dependent_variable)) == level2) %>%
group_by(cut_independent_variable) %>%
summarise(fact_level2 = n())
#分组计算出因子水平2的总数
fact_sample <- left_join(fact_level1, fact_level2, by = "cut_independent_variable") %>%
na.omit() %>%
mutate(cumsum_level2 = cumsum(fact_level2), #level2累积和
cumsum_level1 = cumsum(fact_level1), #level1累积和
cum_sum_level2_prob = cumsum_level2/sum(fact_level2), #level2累积占比
cum_sum_level1_prob = cumsum_level1/sum(fact_level1), #level1累积占比
D_value = abs(cum_sum_level1_prob - cum_sum_level2_prob)) #两累积占比的差
ks_value = fact_sample %>%
select(D_value) %>%
max()
#计算ks值:ks值是两累积占比的最大值
ks_value
}
ks_value(loandata, "score10", "bad_good", "bad", "good")
该代码的数据如下附件中所示。完整代码附件中也有。
