作者:量化小白H Python爱好者社区专栏作者
个人公众号:量化小白上分记
前文传送门:
【Python金融量化】VaR系列(一):HS,WHS,RM方法估计VaR
上一篇总结了三种简单的计算VaR的方法:HS,WHS和RM方法,其中RM方法表现最好,HS和WHS基本没什么作用,不过加权分位数的概念还是挺有意思的,也许别的地方可以借鉴。
这一篇介绍三种稍微复杂一些的方法,并将他们的结果与之前效果最好的RM方法的结果相对比。数据和代码在后台回复"VaR2"可得。
首先对VaR的定义做一回顾,上一篇提到,如果我们假设资产标准化的收益率符合正态分布,那么VaR的理论表达式为

上式右边第一项为资产收益率的波动率,第二项为正态分布分布函数的逆函数在p处的值。事实上,即使资产标准化的收益率不符合正态分布,只要右边第二项表示资产标准化的收益率的分布,等式依然成立。
因此,对VaR的估计可以分为两部分,对于波动率的估计和对于资产分布函数的估计。之前三种方法都假设资产标准化的收益率服从标准正态分布,因此只对波动率进行建模,HS和WHS方法过于简单不说,RM方法实际上可以看成是简化版的Garch模型。准确的说,是基于正态分布假设的Garch(1,1)模型的简化版。
这一篇的三种方法主要思路也是围绕上式中波动率估计和资产分布函数的估计展开。
1. 波动率估计
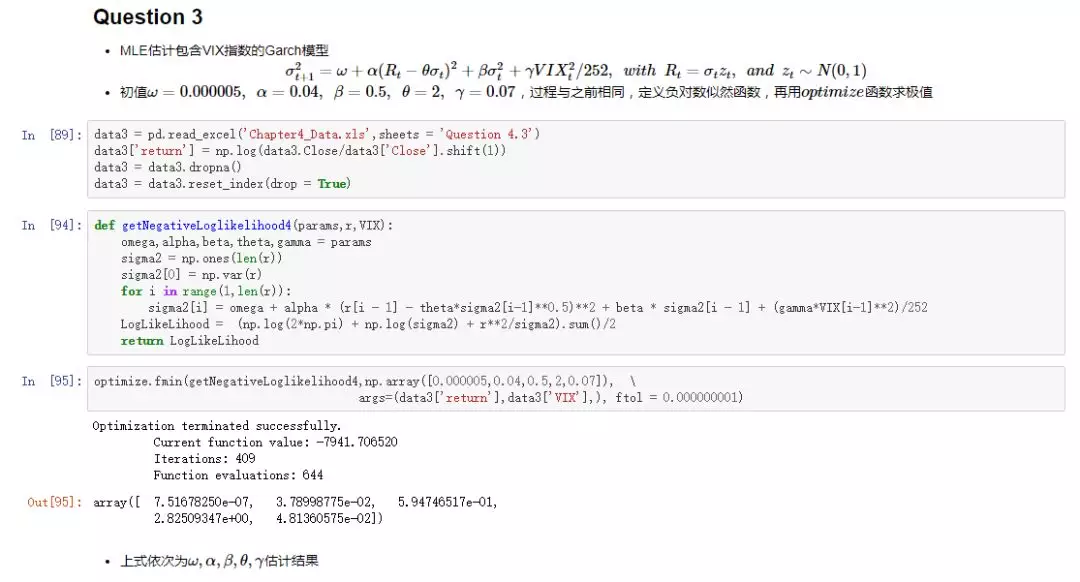
因为文章所用的数据中已经给出了波动率的估计结果,所以实际建模中这部分的模型就略过了。而实际上所用数据波动率的估计结果是书中第四章习题的结果,波动率的估计是通过带VIX指数项的Garch模型,要深究的话可以运行下面图片中的代码,得到的波动率结果和数据给出的是一致的。
因此本文介绍的三种方法主要是对标准化的收益率z的分布进行估计。
2. CF模型
CF(Cornish-Fisher)方法认为将标准化收益率的分布假设为正态分布是不太合理的,省略了过多信息。

因此直接用正态分布函数代替标准化收益率的分布D(0,1)误差会很大, 所以采用了类似泰勒展开的方法:
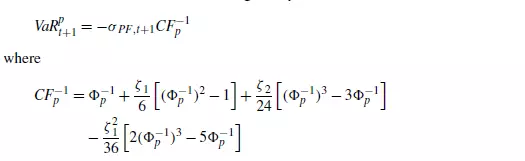
这种方法可以看做是在正态分布附近的泰勒展开到三次, ,
, 分别是标准化资产收益率的偏度和峰度。如果将他们看做为0,等价于假设标准化资产收益率的分布是标准正态分布。
分别是标准化资产收益率的偏度和峰度。如果将他们看做为0,等价于假设标准化资产收益率的分布是标准正态分布。
用这种方法估计VaR的话,只需要多估计峰度和偏度两个参数,直接用矩估计的方法估计即可。(代码统一附在最后)
3. Garch模型
garch模型不过多介绍,资料网上一大堆,或者直接调用python的arch包,即使不懂原理也可以直接用,Garch模型实际上是对收益率的波动率进行建模。

Garch模型的参数估计一般采用极大似然估计方法(MLE)或者似极大似然方法(QMLE),对VaR问题来说,二者差别不大。这里我们采用两种Garch模型进行建模,一种是常见的基于正态性假设的Garch模型,一种是基于t分布的Garch模型。
基于正态性假设的Garch模型

模型的似然函数可以表示为

极大似然估计方法即最大化似然函数或对数似然函数。

python中可以利用optimize函数计算函数的极值。
基于t分布的Garch模型
金融数据分布最普遍的一个性质是尖峰厚尾,这使得用正态分布去拟合数据误差很大,因此大佬们找出了各种各样神奇的分布去代替正态分布拟合数据,之前提到的CF模型是一种方法,这里讲的t分布是另一种方法。

t分布有一个自由度参数d,随着d的增大,t(d)越来越逼近于正态分布。这里我们用基于t分布的Garch模型进行建模,首先推导Garch模型的极大似然估计方法。
t分布的密度函数为

z是标准化的收益率

z的密度函数为

其中,

在t分布假设下

对数似然函数为

因此,只需要求解使上述函数取最大值的d,这也可以通过optimize函数完成。
读入数据估计参数
import os
os.chdir('F:\\python_study\\python_friday\\Aug')
import pandas as pd
import numpy as np
from scipy import optimize
from scipy.special import gammaln
import statsmodels.api as sm
from scipy import stats
from scipy.stats import norm,t
import matplotlib.pyplot as plt
data5 = pd.read_excel('Chapter6_Data.xls',sheetname='Question 6.5')
data5['return'] = np.log(1+data5.Close.pct_change(1))
data5['sigma'] = data5['sigma2']**0.5
data5['z'] = data5['return']/data5['sigma']
data5 = data5.dropna()
data5 = data5.reset_index(drop = True)
data_train = data5.loc[0:2008]
data_test = data.loc[2009:]
这里为了比较各种方法的优劣,将数据分为两段,data_train和data_test,训练集用来估计参数计算VaR,测试集用于之前相同的方法构建投资组合计算收益。
optimize函数只能求函数的最小值,因此根据之前的公式定义负对数似然函数,最小化负对数似然函数。
def getNegativeLoglikelihood(d,r):
LogLikeLihood = r.shape[0]*(gammaln((d+1)/2) - gammaln(d/2) -np.log(np.pi)/2 - np.log(d-2)/2) - 1/2*(1+d)*np.log(r['z']**2/(d-2)+1).sum()
return -LogLikeLihood
d_best = optimize.fmin(getNegativeLoglikelihood,np.array([10]), \
args=(data_train,),ftol = 0.000000001)
print('QMLE估计结果为:',d_best)
给定d的初值,d的极大似然估计结果为11.81,我们通过qq图来看参数的效果。
QQ-plot
s = sm.ProbPlot(data5['z'], dist=stats.t, distargs=(d_best[0],),a = 0.5)
x = s.qqplot(line = '45')
plt.xlim(-8,8)
plt.ylim(-8,8)
plt.show()

QQ图结果来看,参数效果还可以,估计出d之后,就可以计算VaR

除了用t分布之后,还可以用渐近t分布进行估计,方法类似,不再赘述。
4.EVT模型
EVT模型也可以称为极值理论,是风险模型中一类比较重要的方法,这种方法的思想也很有意思,它认为,风险的发生与否,与绝大多数数据是没有关系的,只与那些小概率事件即出现大波动的情况有关系,也就是尖峰厚尾的尾部,因此,我们可以过滤掉那些不重要的数据,只用它的尾部去建模,这样刻画风险的效果可能会更好。极值理论认为尾部既不服从正态分布也不服从t分布,而是服从广义帕累托分布(Generalized Pareto Distribution)

这里的 是GPD中唯一需要估计的参数,也可以通过MLE进行估计。
是GPD中唯一需要估计的参数,也可以通过MLE进行估计。
在估计 之前,还需要做的一件事情是定义尾部,设定一个阈值u,超出这个阈值就认为这是尾部,不超出就认为它不是尾部,估计GPD分布中参数的值只从尾部中取,即只从大于等于u的值中取。
之前,还需要做的一件事情是定义尾部,设定一个阈值u,超出这个阈值就认为这是尾部,不超出就认为它不是尾部,估计GPD分布中参数的值只从尾部中取,即只从大于等于u的值中取。
这里u的选取是一个典型的bias and variance trade-off,如果u过大,尾部的值非常少,这样估计得到的 很不稳定,如果u很小,尾部值非常多,不符合EVT模型的假设,这样得到的结果是有偏的。 这个教材里也没有提很高大上的估计方法,只是给出了一个经验估计方法:选取的u保证尾部的值有50个即可。
很不稳定,如果u很小,尾部值非常多,不符合EVT模型的假设,这样得到的结果是有偏的。 这个教材里也没有提很高大上的估计方法,只是给出了一个经验估计方法:选取的u保证尾部的值有50个即可。
而GPD分布的参数在MLE下有很简单的解析解表达式如下图,推导过程中运用了Hill estimator,过程略,细节见教材。
 从而,极值部分的分布函数可以表示为
从而,极值部分的分布函数可以表示为

其中,T是样本总量,Tu是极值个数,本文中就是50。
从而,VaR可以表示为

其中,

EVT-QQ plot
首先估计参数
T = data_train.shape[0]
Tu = 50
u = data_train.z.sort_values().values[Tu]
print('u = ',u)
xi = 1/50*np.log(data_train.z.sort_values().values[:Tu]/u).sum()
print('xi = ',xi)
c = Tu/T*abs(u)**(1/xi)
print('c = ',c)
这里的xi就是 ,得到结果为
,得到结果为
u = -2.05402902944
xi = 0.204467350277
c = 0.841148514934
作出极值理论建模下的QQ图,,因为懒得自己写QQ-plot的函数,而scipy中qqplot函数又必须是scipy中的分布对象,可是scipy中又没有直接可以用的GPD分布函数,所以这里偷了个懒,从scipy中继承了正态分布,再把分布函数改成GPD的分布函数,然后直接调用scipy中的qqplot看结果,过程其实还是很tricky的,对我来说,这里可能是全文最难的点了,其他地方都很快写完了,这里写了蛮久,开始给这个对象定义了好多方法,后来发现其实只需要定义好做qqplot需要用的逆函数就行了。
from scipy.stats._continuous_distns import norm_gen
class EVT(norm_gen):
def _ppf(self,q):
u = -2.225
xi = 0.215
return u*(q**(-xi))
结果

看起来比之前的t分布结果要好很多。
5. VaR
用训练集得到的参数计算VaR,结果如图,其中RM方法为上一篇中介绍过的。

看上去很接近,没什么差别,用与上一篇相同的方法构造投资组合,曲线图如下。(不想去看怎么构造的可以这样想,收益越高,表明估计效果最好)

可以看出,CF的效果最差,EVT和RM的效果差不多是最好的,后期RM的效果超过了EVT,两种Garch方法的结果居中。
本文整篇的流程都是按照作者在原书中的方法进行的,但是在Garch方法这里,感觉逻辑上是有一些问题的,Garch模型只在了对标准化收益的分布函数中,但实际上波动率也应该用估计得到的波动率替换,这样才是配套的,但作者使用的一直是另外一种方法得到的波动率,而EVT和CF中没有单独对波动率的估计,所以用别的方法估计波动率没有什么问题。
总的来说,RM方法是最简洁易行的,而且效果最好,EVT方法用到的数据量最少,仅50个,效果也很好。
6. 代码
var计算
p = 0.01
phi = norm(0,1).ppf(p)
data5['VAR_EVT'] = -data5['sigma']*u*(p/(Tu/T))**(-xi)
data5['VAR_norm'] = - data5['sigma']*phi
data5['VAR_t'] = - data5['sigma']*t(d_best[0]).ppf(p)*((d_best[0] - 2)/d_best[0])**0.5
data5['VAR_CF'] = - data5['sigma']*(phi + data5.z.skew()/6*(phi**2-1) + \
data5.z.kurt()/24*(phi**3-3*phi) - data5.z.skew()**2/36*(2*phi**3-5*phi))
data5['sigma2_RM'] = np.nan
data5.loc[0,'sigma2_RM'] = 0
for i in range(data5.shape[0] - 2):
data5.loc[i + 1,'sigma2_RM'] = data5.loc[i,'sigma2_RM']*0.94 + 0.06* data5.loc[i,'return']**2
data5['VAR_RM'] = -data5['sigma2_RM']**0.5 * phi
var作图
xticklabel = data5.loc[:,'Date'].apply(lambda x:str(x.year) + '-' +str(x.month) + '-' +str(x.day))
xticks = np.arange(0,data5.shape[0]+1,np.int((data5.shape[0]+1)/4))
X = np.arange(data5.shape[0])
plt.figure(figsize=(16,5))
SP = plt.axes()
plt.plot(X,data5.VAR_EVT,label = 'VAR_EVT')
plt.plot(X,data5.VAR_norm,label = 'VAR_EVT')
plt.plot(X,data5.VAR_t,label = 'VAR_t(d)')
plt.plot(X,data5.VAR_CF,label = 'VAR_CF')
plt.plot(X,data5.VAR_RM,label = 'VAR_RM')
SP.set_xticks(xticks)
SP.set_xticklabels(xticklabel[xticks])
plt.grid()
plt.legend()
plt.show()
组合收益计算
data51 = data5.loc[2009:].copy()
data51 = data51.reset_index(drop = True)
data51['position_EVT'] = 100000/(data51['VAR_EVT']*np.sqrt(10))
data51['position_norm'] = 100000/(data51['VAR_norm']*np.sqrt(10))
data51['position_t'] = 100000/(data51['VAR_t']*np.sqrt(10))
data51['position_CF'] = 100000/(data51['VAR_CF']*np.sqrt(10))
data51['position_RM'] = 100000/(data51['VAR_RM']*np.sqrt(10))
data51['return_EVT'] = (np.exp(data51['return']) - 1)*data51['position_EVT']
data51['return_norm'] = (np.exp(data51['return']) - 1)*data51['position_norm']
data51['return_t'] = (np.exp(data51['return']) - 1)*data51['position_t']
data51['return_CF'] = (np.exp(data51['return']) - 1)*data51['position_CF']
data51['return_RM'] = (np.exp(data51['return']) - 1)*data51['position_RM']
data51['cum_EVT'] = data51['return_EVT'].cumsum()
data51['cum_norm'] = data51['return_norm'].cumsum()
data51['cum_t'] = data51['return_t'].cumsum()
data51['cum_CF'] = data51['return_CF'].cumsum()
data51['cum_RM'] = data51['return_RM'].cumsum()
组合收益曲线
X = np.arange(data51.shape[0])
xticklabel = data51.loc[:,'Date'].apply(lambda x:str(x.year) + '-' +str(x.month) + '-' +str(x.day))
xticks = np.arange(0,data51.shape[0],np.int((data51.shape[0])/5))
plt.figure(figsize = [20,5])
SP = plt.axes()
SP.plot(X,data51['cum_EVT'],label = 'EVT')
SP.plot(X,data51['cum_norm'],label = 'Garch-norm')
SP.plot(X,data51['cum_t'],label = 'Garch-t')
SP.plot(X,data51['cum_CF'],label = 'CF')
SP.plot(X,data51['cum_RM'],label = 'RM')
SP.set_xticks(xticks)
SP.set_xticklabels(xticklabel[xticks],rotation=45,size =20)
plt.legend()
plt.grid()
plt.show()
参考文献
《Elements of Financial Risk Management》

Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门免费视频课程!!!
【最新免费微课】小编的Python快速上手matplotlib可视化库!!!
崔老师爬虫实战案例免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。

