描述统计就是用表格、图形和数值方法来汇总数据,本文根据《商务与经济统计》第二、三章内容,进行总结并练习得来(可能图表会有点丑)。
为知笔记 http://d97f6ea3.wiz03.com/share/s/3pvSWz0Bgk2X2KohY50WU5fI3wxtjc025QgM2nnMyQ2GaT_y
#一、数据类型
1.分类型数据:用于识别每一个体属性的标记或名称。既可以用名义尺度度量也可以用顺序尺度度量,既可以是非数值型的也可以是数值型的。
2.数值型数据:表示事物大小或多少的数值。既可以用间隔尺度度量也可以用比率尺度度量。
#二、表格法和图形法
##1.思维导图
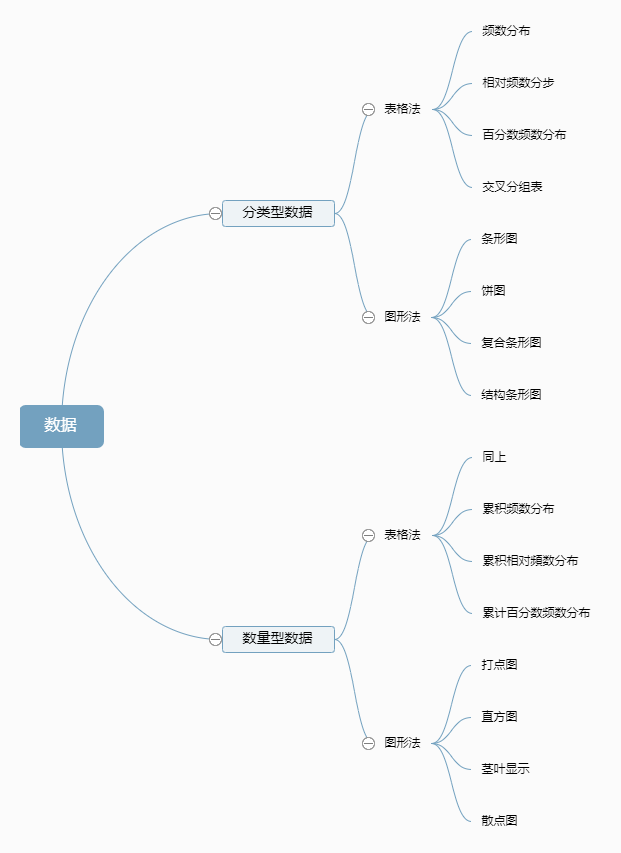
##2.练习
###(1)分类型数据
频数分布、累积频数分布、条形图、饼图
####01数据集 FedBank 民意调查“您如何评价联邦银行在处理金融市场信用问题时的表现?”
法一:COUNTIF
A.在旁边列出所有的答案(Excellent、Good、Fair、Bad、Terrible)
B.用COUNTIF对D2:D6计数,在E2中输入COUNTIF(A2:A1016,D2),按F4选择区域则变成绝对定量COUNTIF($A$2:$A$1016,D2)
C.拖拉下拉到E6
D.对D2:E6插入图表,选择条形图
法二:用数据透视表
A.插入数据透视表,选择区域A1:A1016
B.拖Rating进入行、值(计数项)
####02 数据集 SoftDrink
步骤同上
###(2)数值型数据
Audit数据集(会计审计时间)
法一(EXCEL)
A.将数据升序排列
B.在旁边找位置将上限都列出来,
选择“数据”中的“数据分析”
按一下 “直方图”
在“输入区域”就选择刚才排序过的数据,注意注意!是排序之后的数据!!
在“接收区域”选择列好在一旁的上限!
在“输出选项”中,选择“累计百分率”,“图标输出”即可!
对接受区域的组范围进行改变
C.选择数据,插入散点图,删除图标标题,删除垂直坐标刻度及网格线,调整水平坐标刻度,最后调整图形高度,完成打点图绘制。
D.累积频数分布:最后一个数据项总等于观测值的总数。累计相对频数分布的最后一个数据项总等于1.00,累积百分数频数分布的最后一个数据项总等于100。
法二 数据透视表
A.将数据排序(升序排列)
B.在C1格点插入---数据透视表---将Audit Time拖到行、值框中
C.点击值框中的“值字段设置”选项,值汇总方式选择计数,确定
D.单击C2或任一分类单元格,右击,选择“组合”选项,起始于改成10,终止于改成34,步长设为5,确定
E.选择数据透视表,点击插入---数据透视图---条形图(直方图画不了,不知道为什么),可以再一点点改变间距
###(3)交叉分组表、复合条形图、结构条形图
以饭店数据集为例 Restaurant.csv
####01 EXCEL
A.先对数据根据“Quality Rating”进行排序(Good,Very Good,Excellent)插入---数据透视表---区域A1:C301
B.拖拽Quality Rating到行,Meal Price到列,Restaurant到值,在值的求和项的下拉列表中选择“值字段设置”选项,值汇总方式选择计数,确定
C.点击列变量任一单元格,右击选择“组合”,起始值为10,终止值为49,步长10,确定
D.选取数据透视表,插入复合条形图、结构条形图
计数项:Restaurant列标签
行标签10-1920-2930-3940-49总计
Good4240284
Very Good3464466150
Excellent214282266
总计781187628300
如果不先排序的话,就会变成下面这个样子(行标签有点乱)
计数项:Restaurant列标签
行标签10-1920-2930-3940-49总计
Excellent214282266
Good4240284
Very Good3464466150
总计781187628300
####02 Minitab
1.打点图
以Audit.CSV为例
(1)用Minitab打开Audit.CSV文件,选择Graph(图形)下拉菜单,选择Dotplot(打点图)
(2)一个Y,简单
(3)在图形变量中输入C1,或者在左侧选择要添加的变量,确定
2.直方图
(1)以Audit.CSV为例,用Minitab打开Audit.CSV文件,选择Graph(图形)下拉菜单,选择Histogram(直方图)
(2)选择简单,确定
(3)在图形变量中输入C1,或者在左侧选择要添加的变量,确定
(4)修改组宽
当直方图出现时,将鼠标放在任意一个纵条上双击,出现编辑条形框,###可是感觉和书本上的还不一样
3.茎叶显示
以Audit.CSV为例
(1)以Audit.CSV为例,用Minitab打开Audit.CSV文件,选择Graph(图形)下拉菜单,选择Stem and Leaf(茎叶图)
(2)选择简单,确定
(3)在图形变量中输入C1,或者在左侧选择要添加的变量,确定
#####结果有点不太对
4.散点图
(1)用Minitab打开Audit.CSV文件,选择Graph(图形)下拉菜单,选择Scatter Plot(散点图)
(2)选择简单,确定
(3)在Y变量输入C3,在X变量输入C2
5.交叉分组表
以Restqurant.CSV为例
Minitab只能建立品质变量的交叉分组表,而餐价是数量变量,所以我们首先需要通过规定每个餐价所属的类,来对参加数据编码。下面的步骤可以对餐价数据编码,在C4列产生四个类:10~19美元,20~29美元,30~39美元,40~49美元
(1)用Minitab打开Restqurant.CSV文件,选择Data(数据)下拉菜单,选择Code(编码),选择数字到文本
(2)在“列中的编码数据”填入C3,在“在列中存储的编码数据”填入C4,原始值变量中分别填入10:19,20:29,30:39,40:49,依次在新值框中填入10~19,20~29,30~39,40~49
(3)对于在C3中的每一个餐价,对应的参加类别将分别出现在C4列。我们用C2和C4中的数据绘制表格
a.选择统计---表格---交叉分组表和卡方
b.行:C2; 列:C4 ; 显示:计数
#三、数值法
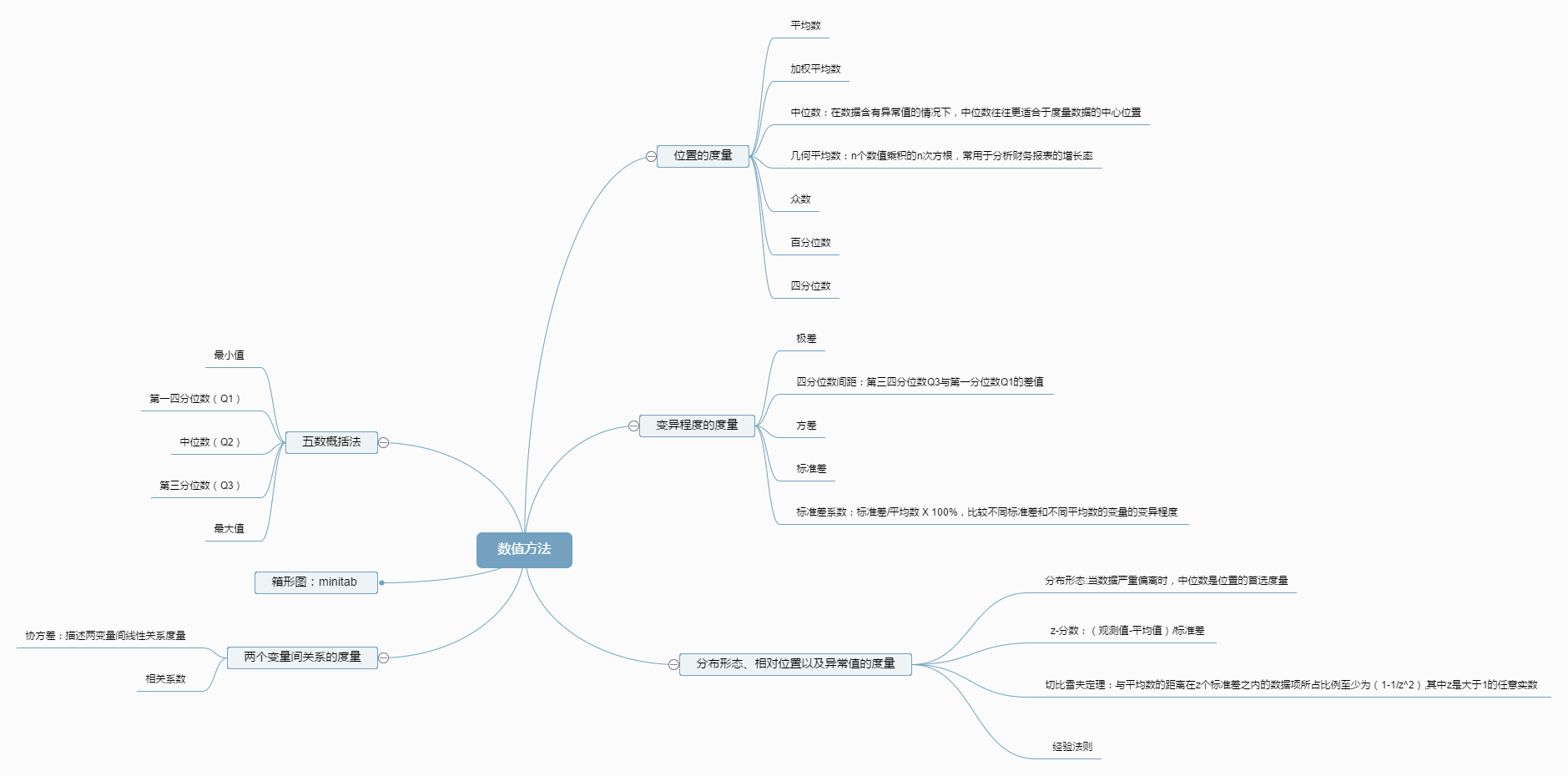
用Minitab计算统计量及绘制箱线图
##1.描述性统计量
以2012StartSalary.CSV为例
##2.补充的描绘统计量
在出现上图2的“显示描述性统计量”的框时,选择“统计量”,勾选出自己喜欢的统计量
##3.箱形图
以2012StartSalary.CSV为例
把数据整理成这种格式,用Minitab打开
以图3-8 MajorSalary.CSV为例(本来格式就是整理完的) 好像没有办法变换颜色
##4.注意点:
###1.辛普森悖论
我们常常需要合并或综合两个或两个以上的交叉分组表的数据,生成一个汇总的交叉分组表,但从两个或多个单独的交叉分组表得到的结论与以及综合的交叉分组表数据得到的结论可能截然相反,这种现象被称为辛普森悖论。
在得出结论之前,应该审查交叉分组表是综合形式还是未综合形式,以便提出较好的见解和悖论。特别的,党交叉分组表包括综合数据时,你应该审查是否存在可能影响结论的隐藏变量,使得分开的或未综合交叉分组表提供不同的、可能更好地见解和结论
###2.切比雪夫定理
与平均数的距离在z个标准差之内的数据项所占的比例至少为(1-1/z^2),其中z是大于1的任意实数
经验法则(数据集呈现峰形或钟形分布):
- 大约68%的数据集与平均数的距离在1个标准差之内
- 大约95%的数据集与平均数的距离在2个标准差之内
- 几乎所有的数据集与平均数的标准差在3个标准差之内
###3.异常值的断定:
1)具有钟形分布的数据集,根据经验法则判断:几乎所有的数据集与平均数的标准差在3个标准差之内
因此,把z-分数小于-3或大于+3的数值都视为异常值
2)根据第一四分位数和第三四分位数以及四分位数间距(IQR=Q3-Q1)
下限:Q1- 1.5 X IQR
上限:Q3+1.5 X IQR
###4.相关系数
相关系数提供了线性但不是因果关系的一个度量。两个变量之间较高的相关系数,并不意味着一个变量的变化会引起另一个变量的变化。
