作者:ApacheCN【翻译】 Python机器学习爱好者
Python爱好者社区专栏作者
GitHub:https://github.com/apachecn/hands_on_Ml_with_Sklearn_and_TF
前文传送门:
多项式核
添加多项式特征很容易实现,不仅仅在 SVM,在各种机器学习算法都有不错的表现,但是低次数的多项式不能处理非常复杂的数据集,而高次数的多项式却产生了大量的特征,会使模型变得慢。
幸运的是,当你使用 SVM 时,你可以运用一个被称为“核技巧”(kernel trick)的神奇数学技巧。它可以取得就像你添加了许多多项式,甚至有高次数的多项式,一样好的结果。所以不会大量特征导致的组合爆炸,因为你并没有增加任何特征。这个技巧可以用 SVC 类来实现。让我们在卫星数据集测试一下效果。
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
))
poly_kernel_svm_clf.fit(X, y)
这段代码用3阶的多项式核训练了一个 SVM 分类器,即图 5-7 的左图。右图是使用了10阶的多项式核 SVM 分类器。很明显,如果你的模型过拟合,你可以减小多项式核的阶数。相反的,如果是欠拟合,你可以尝试增大它。超参数coef0控制了高阶多项式与低阶多项式对模型的影响。
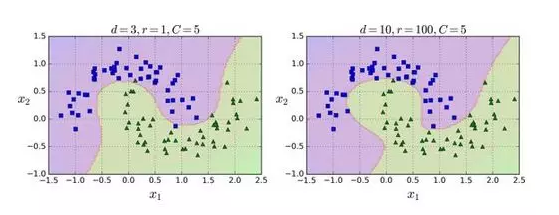
通用的方法是用网格搜索(grid search 见第 2 章)去找到最优超参数。首先进行非常粗略的网格搜索一般会很快,然后在找到的最佳值进行更细的网格搜索。对每个超参数的作用有一个很好的理解可以帮助你在正确的超参数空间找到合适的值。
增加相似特征
另一种解决非线性问题的方法是使用相似函数(similarity funtion)计算每个样本与特定地标(landmark)的相似度。例如,让我们来看看前面讨论过的一维数据集,并在x1=-2和x1=1之间增加两个地标(图 5-8 左图)。接下来,我们定义一个相似函数,即高斯径向基函数(Gaussian Radial Basis Function,RBF),设置γ = 0.3(见公式 5-1)
公式 5-1 RBF
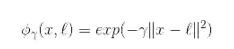
它是个从 0 到 1 的钟型函数,值为 0 的离地标很远,值为 1 的在地标上。现在我们准备计算新特征。例如,我们看一下样本x1=-1:它距离第一个地标距离是 1,距离第二个地标是 2。因此它的新特征为x2=exp((-0.3 × 1)^2)≈0.74和x3=exp((-0.3 × 2)^2)≈0.30。图 5-8 右边的图显示了特征转换后的数据集(删除了原始特征),正如你看到的,它现在是线性可分了。
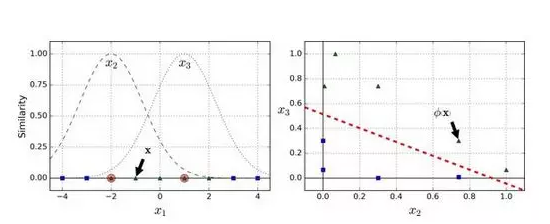
你可能想知道如何选择地标。最简单的方法是在数据集中的每一个样本的位置创建地标。这将产生更多的维度从而增加了转换后数据集是线性可分的可能性。但缺点是,m个样本,n个特征的训练集被转换成了m个实例,m个特征的训练集(假设你删除了原始特征)。这样一来,如果你的训练集非常大,你最终会得到同样大的特征。
高斯 RBF 核
就像多项式特征法一样,相似特征法对各种机器学习算法同样也有不错的表现。但是在所有额外特征上的计算成本可能很高,特别是在大规模的训练集上。然而,“核” 技巧再一次显现了它在 SVM 上的神奇之处:高斯核让你可以获得同样好的结果成为可能,就像你在相似特征法添加了许多相似特征一样,但事实上,你并不需要在RBF添加它们。我们使用 SVC 类的高斯 RBF 核来检验一下。
rbf_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="rbf", gamma=5, C=0.001))
))
rbf_kernel_svm_clf.fit(X, y)
这个模型在图 5-9 的左下角表示。其他的图显示了用不同的超参数gamma (γ)和C训练的模型。增大γ使钟型曲线更窄(图 5-8 左图),导致每个样本的影响范围变得更小:即判定边界最终变得更不规则,在单个样本周围环绕。相反的,较小的γ值使钟型曲线更宽,样本有更大的影响范围,判定边界最终则更加平滑。所以γ是可调整的超参数:如果你的模型过拟合,你应该减小γ值,若欠拟合,则增大γ(与超参数C相似)。
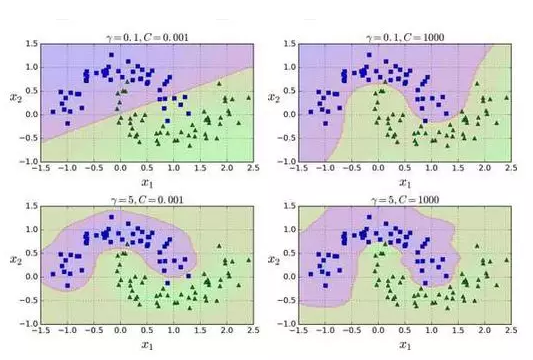
还有其他的核函数,但很少使用。例如,一些核函数是专门用于特定的数据结构。在对文本文档或者 DNA 序列进行分类时,有时会使用字符串核(String kernels)(例如,使用 SSK 核(string subsequence kernel)或者基于编辑距离(Levenshtein distance)的核函数)。
提示
这么多可供选择的核函数,你如何决定使用哪一个?一般来说,你应该先尝试线性核函数(记住LinearSVC比SVC(kernel="linear")要快得多),尤其是当训练集很大或者有大量的特征的情况下。如果训练集不太大,你也可以尝试高斯径向基核(Gaussian RBF Kernel),它在大多数情况下都很有效。如果你有空闲的时间和计算能力,你还可以使用交叉验证和网格搜索来试验其他的核函数,特别是有专门用于你的训练集数据结构的核函数。
计算复杂性
LinearSVC类基于liblinear库,它实现了线性 SVM 的优化算法。它并不支持核技巧,但是它样本和特征的数量几乎是线性的:训练时间复杂度大约为O(m × n)。
如果你要非常高的精度,这个算法需要花费更多时间。这是由容差值超参数ϵ(在 Scikit-learn 称为tol)控制的。大多数分类任务中,使用默认容差值的效果是已经可以满足一般要求。
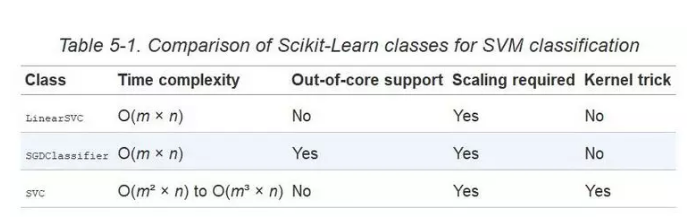
SVC 类基于libsvm库,它实现了支持核技巧的算法。训练时间复杂度通常介于O(m^2 × n)和O(m^3 × n)之间。不幸的是,这意味着当训练样本变大时,它将变得极其慢(例如,成千上万个样本)。这个算法对于复杂但小型或中等数量的数据集表现是完美的。然而,它能对特征数量很好的缩放,尤其对稀疏特征来说(sparse features)(即每个样本都有一些非零特征)。在这个情况下,算法对每个样本的非零特征的平均数量进行大概的缩放。表 5-1 对 Scikit-learn 的 SVM 分类模型进行比较。
SVM 回归
正如我们之前提到的,SVM 算法应用广泛:不仅仅支持线性和非线性的分类任务,还支持线性和非线性的回归任务。技巧在于逆转我们的目标:限制间隔违规的情况下,不是试图在两个类别之间找到尽可能大的“街道”(即间隔)。SVM 回归任务是限制间隔违规情况下,尽量放置更多的样本在“街道”上。“街道”的宽度由超参数ϵ控制。图 5-10 显示了在一些随机生成的线性数据上,两个线性 SVM 回归模型的训练情况。一个有较大的间隔(ϵ=1.5),另一个间隔较小(ϵ=0.5)。
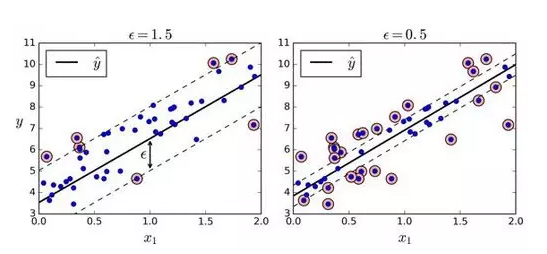
添加更多的数据样本在间隔之内并不会影响模型的预测,因此,这个模型认为是不敏感的(ϵ-insensitive)。
你可以使用 Scikit-Learn 的LinearSVR类去实现线性 SVM 回归。下面的代码产生的模型在图 5-10 左图(训练数据需要被中心化和标准化)
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon=1.5)
svm_reg.fit(X, y)
处理非线性回归任务,你可以使用核化的 SVM 模型。比如,图 5-11 显示了在随机二次方的训练集,使用二次方多项式核函数的 SVM 回归。左图是较小的正则化(即更大的C值),右图则是更大的正则化(即小的C值)
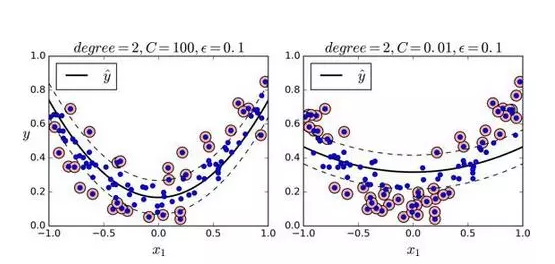
下面的代码的模型在图 5-11,其使用了 Scikit-Learn 的SVR类(支持核技巧)。在回归任务上,SVR类和SVC类是一样的,并且LinearSVR是和LinearSVC等价。LinearSVR类和训练集的大小成线性(就像LinearSVC类),当训练集变大,SVR会变的很慢(就像SVC类)
from sklearn.svm import SVR
svm_poly_reg = SVR(kernel="poly", degree=2, C=100, epsilon=0.1)
svm_poly_reg.fit(X, y)
注
SVM 也可以用来做异常值检测,详情见 Scikit-Learn 文档
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。


