1、索引的种类
常用的index按物理属性有B-Tree Index(常规树)、B Tree(二叉树)、B+Tree、Bitmap Index(位图)、Reverse Index(反向)、Hash Index、分区和非分区Index。按使用方法上划分有 唯一和非唯一索引、组合索引、函数索引、聚簇和非聚簇索引。
了解索引的原理,对SQL查询优化有着及其重要的作用,现在就逐个的解析这些索引的原理。
2、常规树, B-tree Index
一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。可以用下图一来描述B树索引的结构。其中,B表示分支节点,而L表示叶子节点。
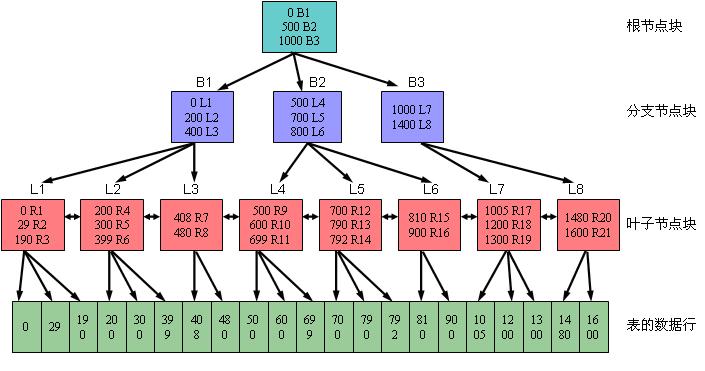
- 分支节点块:索引条目都是按照顺序排列的,每个索引条目都具有两个字段。
第一个字段:该分支节点块下面所链接的索引块中所包含的最小键值;
第二个字段:链接的索引块的地址,该地址指向下面一个索引块。
从上图一可以看到对于 根节点块来说,包含三条记录,分别为(0 B1)、(500 B2)、(1000 B3),它们指向三个分支节点块。其中的0、500和1000分别表示这三个分支节点块所链接的键值的最小值。而B1、B2和B3则表示所指向的三个分支节点块的地址。
- 叶子节点块:索引条目与分支节点一样,按照顺序排列的。叶子节点 指向 兄弟节点。
第一个字段:索引的键值,对于单列索引来说是一个值;而对于多列索引来说则是多个值组合在一起的
第二个字段:表示键值所对应的记录行的ROWID,该ROWID记录行在表里的物理地址
用途:定位高效、利用率高、自我平衡,特别适用于高基数字段,定位单条或小范围数据非常高效。Oracle默认使用B-tree,比如 唯一Index、非唯一Index。达到1千万条数据时,B-tree索引也是三层结构(亿级别数据量是4层或更多)。定位记录只需要三次I/O,因此100条数据和1千万条数据的定位,在b-tree索引中的花销是一样的。
B-Tree的真实结构是这样的:
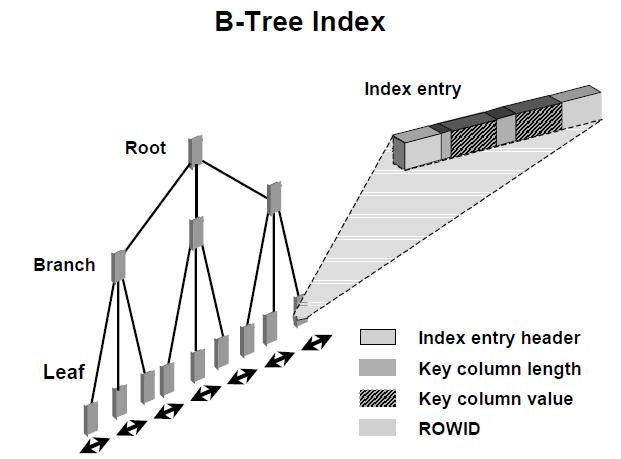
叶子节点:索引头 + 索引键长度+索引键+ROWID
优势:
- 树的所有叶子块都在相同深度,索引中从任何地方检索任何记录都大约花费相同的时间
- B-tree 自动保持平衡
- B-tree 对大范围查询提供优秀的检索性能,包括精确匹配和访问查询
- 插入、更新和删除操作有效,维护键的顺序,以快速检,适合OLTP
- B-tree 性能对小表和大表都很好,不会随着表的增长而降低
3、链式索引
- 链式索引,也称之为组合索引,多个字段组合起来的索引键,如'a'+'b'+'c'。这种索引对于表的多条件查询非常高效。
- 看完Btree 的结构,组合索引的‘最左原则’就非常好理解了。用b,c,b+c,a+c都用不到该组合索引,查询效率会很低。
- 必须是a,a+b,或a+b+c才会利用该索引。
- 最左边的字段,必须是最常用的查询字段。
4、反向索引
也是基于BTree结构,不难理解反向索引的作用。为避免索引的分支节点块的I/O访问冲突,建立反向reverse索引。
如基于用户账号建立索引,
'5101000876','5101000877','5101000878','5101000879','5101000880'
--如果一个查询 '5101000876',一个查询'5101000877',则会有2个I/O同时访问‘5101000876’这个分支节点。
反向索引键如下,刚好避开I/O冲突,使得BTree分散得更均衡
'6780001015','7780001015','8780001015','9780001015','8080001015'
