在上次使用了下kafka,在此测试下CentOS 7中Spark streaming连接kafka,并把数据传入postgresql中
一、环境部署
安装python3.6、spark 2.3、kafka,具体可以参考我前面的文章
二、启动相应程序
启动Zookeeper:
$cd /spark/kafka_2.11-0.9.0.0
$bin/zookeeper-server-start.sh config/zookeeper.properties
启动Server
$cd /spark/kafka_2.11-0.9.0.0/
$bin/kafka-server-start.sh config/server.properties
三、下载Spark Streaming依赖包
具体要求可参考官网文档:http://spark.apache.org/docs/latest/streaming-programming-guide.html
依赖包下载地址:https://search.maven.org/#search%7Cga%7C1%7Cg%3A%22org.apache.spark%22%20AND%20v%3A%222.3.1%22,选定对应的依赖包,即spark-streaming-kafka-0-8-assembly_2.11-2.3.1.jar,把该安装包放在/spark/spark-2.3.0-bin-hadoop2.7/jars文件夹下的目录中
四、Kafka连接Streaming测试
1.先启动kafka生产界面
$cd /spark/kafka_2.11-0.9.0.0/
$bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test #本机上创建test的主题
2、修改streaming日志
在Streaming界面运行会显示太多的INFO、WARN信息,需要改变日志的显示级别
$cd /spark/spark-2.3.0-bin-hadoop2.7/conf
$mv log4j.properties.template log4j.properties #改变log4j名称
$vi log4j.properties
log4j.rootCategory=INFO, console -> log4j.rootCategory=ERROR, console #设置显示级别
3.启动Streaming
$cd /spark/spark-2.3.0-bin-hadoop2.7
$bin/spark-submit --jars jars/spark-streaming-kafka-0-8-assembly_2.11-2.3.1.jar examples/src/main/python/streaming/kafka_wordcount.py localhost:2181 test #依赖包位置是前面下载的文件放的位置; kafka_wordcount.py是安装spark时自带的脚本
在生产界面随意输入字符串:hello world,在streaming中就可以看到相应的输出结果

五、把kafka传递的数据插入pg数据库
1.创建checkpoint文件夹
在streaming中使用reduceByKeyAndWindow函数时必须要chechpoint文件夹(本机单独使用,非分布式),在linux输入
$cd /spark/spark-2.3.0-bin-hadoop2.7/examples/src/main/python/streaming &&mkdir checkpoint #注意文件权限问题
2、建立pg连接池,设置数据库
在自己的postgresql数据库中创建表,设置主键(update+insert 必须要主键)
定义连接池函数,文件名connection_pool_pg.py,放在 /spark/spark-2.3.0-bin-hadoop2.7/examples/src/main/python/streaming下
from psycopg2.pool import ThreadedConnectionPool
DSN = "dbname='postgres' user='postgres' host='x.x.x.x' port='5432' password='postgres'"
tcp = ThreadedConnectionPool(3, 20, DSN)
def getConnection():
return tcp.getconn()
def returnConnection(conn):
return tcp.putconn(conn)
上面文件中引用了函数,需要安装psycopg2模块
$find -name pip3 2>/dev/null #当pip3不能成功时,找到pip3的位置
$cd ~/.config #当默认的网址被墙时需要修改pip的连接网址
$mkdir pip #创建pip文件夹
$vi pip/pip.conf #打开文件,修改内容
[global]
index-url = http://pypi.douban.com/simple
trusted-host = pypi.douban.com
disable-pip-version-check = true
timeout = 120
$pip3 install psycopg2 #当受到限制时,跳到文件夹添加权限,如$cd /usr/local/lib &&sudo chown -R chris:users python3.6
$sudo vim /var/lib/pgsql/10/data/pg_hba.conf #添加本机的ip地址,如host all all x.x.x.x/32 trust
$systemctl restart postgresql-10 #重启数据库
3.修改streaming文件夹下kafka_wordcount.py文件内容
from __future__ import print_function
import sys
import json
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
from psycopg2.pool import ThreadedConnectionPool
import connection_pool_pg
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: kafka_wordcount.py <zk> <topic>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="PythonStreamingKafkaWordCount")
ssc = StreamingContext(sc, 5)
ssc.checkpoint('/spark/spark-2.3.0-bin-hadoop2.7/examples/src/main/python/streaming/checkpoint')
zkQuorum, topic = sys.argv[1:]
kvs = KafkaUtils.createStream(ssc, zkQuorum, "spark-streaming-consumer", {topic: 1})
lines = kvs.map(lambda v: v[1])
data=lines.map(lambda x:(x,1))
data_count=data.reduceByKeyAndWindow(lambda a,b:a+b,lambda a,b:(a-b),30,10)
def process_data(iter):
SQL = "INSERT INTO test (key,count) VALUES (%s,%s) ON CONFLICT (key) DO UPDATE SET count = EXCLUDED.count;"
conn = connection_pool_pg.getConnection()
for record in iter:
print(record)
cur = conn.cursor()
data = (record[0],record[1])
cur.execute(SQL, data)
cur.close()
conn.commit()
connection_pool_pg.returnConnection(conn)
data_count.foreachRDD(lambda rdd: rdd.foreachPartition(process_data))
ssc.start()
ssc.awaitTermination()
运行命令:
$cd /spark/spark-2.3.0-bin-hadoop2.7
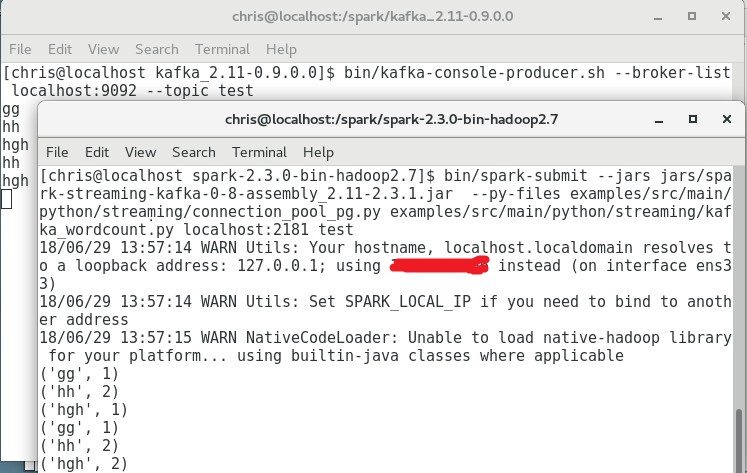
$bin/spark-submit --jars jars/spark-streaming-kafka-0-8-assembly_2.11-2.3.1.jar --py-files examples/src/main/python/streaming/connection_pool_pg.py examples/src/main/python/streaming/kafka_wordcount.py localhost:2181 test
到此就差不多OK了,结果如图所示
关于streaming其它详细地方,可以参考官网在GitHub的代码:https://github.com/apache/spark/tree/master/examples/src/main/python/streaming
