Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。
数据类型包括 :变量 变量名 值。整数(int)浮点数(float) 复数(complex)布尔值(bool)类型(type)
1. 基础操作——
# 表示单行注释,不运行。 shift+Enter 向下 运行 ctrl+Enter 本行运行
A==B 判断是否相等 单双引号的嵌套使用 三引号的使用。 a+=1 #等同于a=a+1
num[0:2]#后]是开区间 不包含
基本的插入 重新赋值 增加 删除操作
num.insert(2,5)#位置从0开始,在第二个位置插入5 num.append(6)#末尾增加6
num=num+[7,8]#增加7.8 num.pop() #删除末尾一个数 num.pop(3)#删除位置在3的数字
2. 三大结构——元组 () 列表 [ ] 字典{ }
b=[[1,2],[3,4]]#增加元组
[row]*3 #列表组合 —— [[row], [row], [row]] set(a)- set(b)# a有b没有
list(a.items())#字典的key+values
# 为特定数字增加字符串
list_2=['str'+str(i) for i in range (1,101) if(i%2==0)&(i%3==0)]
#查询列表中相应元素的个数 d={}
for i in a:
if i in d.keys():
d[i]=d[i]+1
else:
d[i]=1
#查询数量 import collections collections.Counter()
#列表中查找特定元素 array查找的数据类型必须相同,list不必相同
#查看类型 a.dtype #更改类型 s.astype('str')
#赋值 df.Age=[24,28,32,46] #增加索引 df.index=list('ABCD')
#iloc通过所在行的行号为索引,loc以标签所在行为索引,ix——通过行标签或者行号索引行数据(基于loc和iloc 的混合)
#把29变为26 df.loc[df.Age==29,'Age']=26
df.info() 表的基础信息 #查询 df.query('companyId>100000').city
#分类筛选 | 并集 &或者
df[(df.companyId>100000)&(df.city=='北京')|df.secondType=='数据分析')]
#读取csv
import pandas as pd
df=pd.read_csv("DataAnalyst_utf.csv")
df.sort_values('city',ascending=False)
#按最小值降序分级
df['rank']=df.companyId.rank(ascending=False,method='min')
#查找唯一值 df.city.unique() #工作年限分类 df.workYear.value_counts()
3. 控制循环——基本语句“while if else continue/pass/break"
count=0
while count<10:
count=count+1
if count%2==0:
continue
print('this num is:',count)
函数及控制循环:#加减乘除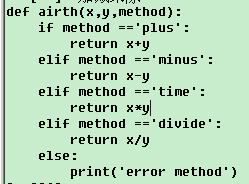 airth(6,2,'time')#乘
airth(6,2,'time')#乘
# 大小均值中位数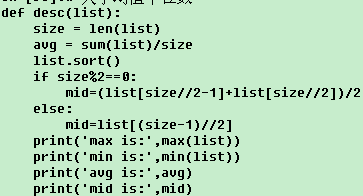
list(map(lambda x:x*x+3, [1,2,3,4]))# map全匹配
df_duplicates=df.drop_duplicates(subset='positionId',keep='first') #去重
#分析描述 df_clean.describe()
#按城市分组并求平均薪资最大值 df_clean.groupby(by='city').avgsalary.max()
#所有元素平均值 df_clean.groupby(by=['city','workYear']).mean
#为数字分区,分阶层
df_clean['bins']=pd.cut(df_clean.avgsalary,bins=4,labels=['0`10','10`20','20`30','30`40'])
#按分类选择读取相应的薪资,多重索引
df_clean.groupby(by=['city','education']).mean().loc['上海','本科']
#增加索引 df_clean.set_index(['city','education'])
#设置 列-索引 并按索引排序 index
df_clean.sort_values(by=['city','education']).set_index(['city','education'])
#重置索引 reset
df_clean.groupby(by=['city','education']).mean().reset_index('city')
#文本函数清洗
df_clean.positionLables.str.count('')
#df_clean.positionLables.str.find('')位置
#去掉引号“”
df3=df_clean.positionLables.str.replace("'","")
#去掉中括号[ ] df3.str[1:-1]
#把上海变为空值 df_clean.loc[df_clean.city=='上海','city']=np.NaN
#去掉空值 df_clean.dropna()
#替换 replace dft=df_clean.replace('不限','1年以上')
#为数字加上单位
df_clean.avgsalary.astype('str')+'k'
df_clean.avgsalary.apply(lambda x: str(x)+'K')
#为不同区间的数字加上单位或归类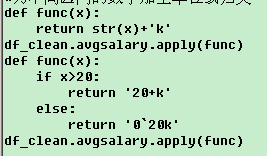
#按城市的平均薪资排序F降序,T升序
def func(x):
r=x.sort_values('avgsalary',ascending=False)
return r[:5]
# apply聚合函数 分类
df_clean.groupby('city').apply(func)
#agg不涉及形式变化的求和
df_clean.groupby('city').agg(['mean','sum'])
4. 数据透视表——
import numpy as np
df_clean.pivot_table(index=['city','education'],columns='workYear',values=['avgsalary'],aggfunc=[np.mean,np.sum],margins=True)
df_clean.pivot_table(index=['city','education'],columns='workYear',values=['avgsalary','topsalary'],
aggfunc={'avgsalary':np.mean,'topsalary':len},margins=True).reset_index
().to_csv() #变更形式为csv
5.关联—— #axis=1行,=0列
pd.concat([df1,df2],axis=1)
df1.merge(right=df2,how='inner',on='name')
#concat堆叠 ,merge通mysql里的join,关联更精准
6.连接数据库——
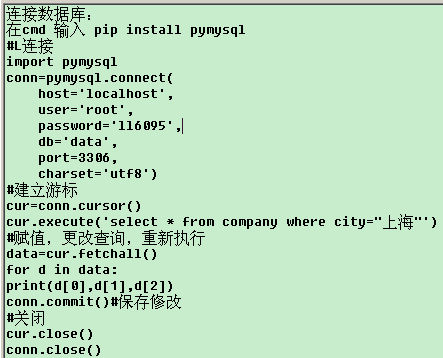
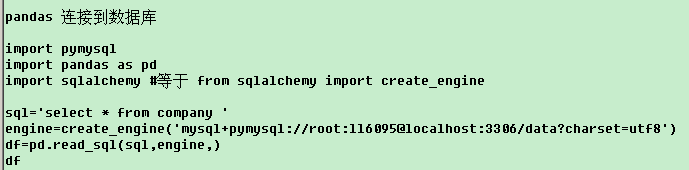
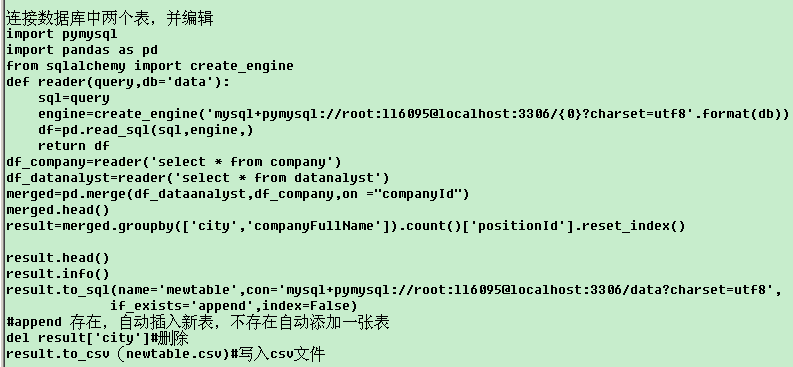
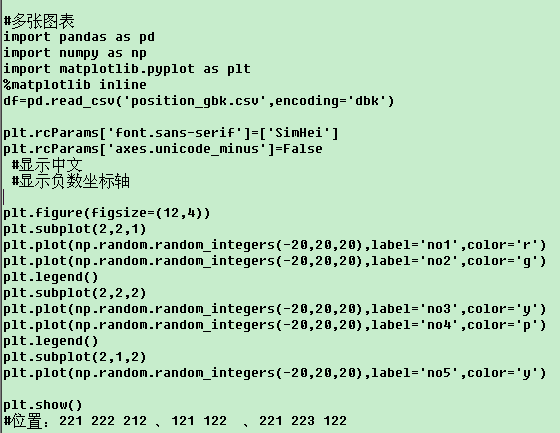
7. 可视化——
import pandas as pd
df=pd.read_csv('position_gbk.csv',encoding='gbk')
%matplotlib inline
#折线图 plot 柱形图 bar 直方图 hist 箱线图box 密度 kde 面积图 area 散点图 scatter 散点矩阵图 scatter_matrix 饼图 pie
df.avg.value_counts().plot() #出现顺序降序 索引X轴 出现次数 y轴
df.avg.value_counts().sort_index().plot()#索引升序
各类图形:
df.pivot_table(index='city',columns='education',values='avg',aggfunc='count').plot.bar() #柱形图
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.hist(alpha=0.5,
stacked=True,bins=30,orientation='horizontal') #横向堆积图
#箱线图df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.box()
df.boxplot(column='avg',by='education')
#密度图 df.avg.plot.kde()
#面积图 df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.area()
#饼图 df.city.value_counts().plot.pie(figsize=(6,6))