粉丝独白
说起热门的B站相信很多喜欢玩动漫的,看最有创意的Up主的同学一定非常熟悉。我突发奇想学Python这么久了,为啥不用Python爬取B站中我关注的人,已经关注的人他们关注的人,看看全站里面热门的UP主都是是哪些。
要点:
- 爬取10万用户数据
- 数据存储
- 数据词云分析
1.准备阶段
写代码前先构思思路:既然我要爬取用户关注的用户,那我需要存储用户之间的关系,确定谁是主用户,谁是follower。
存储关系使用数据库最方便,也有利于后期的数据分析,我选择sqlite数据库,因为Python自带sqlite,sqlite在Python中使用起来也非常方便。
数据库中需要2个表,一个表存储用户的相互关注信息,另一个表存储用户的基本信息,在B站的用户体系中,一个用户的mid号是唯一的。
然后我还需要一个列表来存储所以已经爬取的用户,防止重复爬取,毕竟用户之间相互关注的现象也是存在的,列表中存用户的mid号就可以了。
2.新建数据库
先写建数据库的代码,数据库中放一个用户表,一个关系表:

3.爬取前5页的用户数据
我需要找到B站用户的关注列表的json接口,很快就找到了,地址是:
https://api.bilibili.com/x/relation/followings?vmid=2&pn=1&ps=20&order=desc&jsonp=jsonp&callback=__jp7
因为B站的隐私设置,一个人只能爬取其他人的前5页关注,共100人。
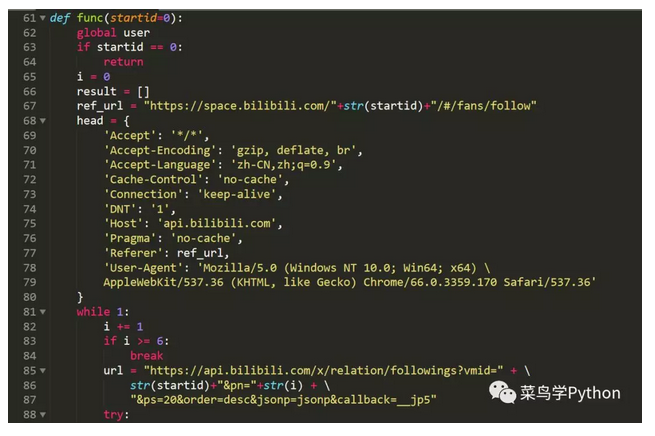
整个爬取页面的思路比较简单,首先设置header,用requests库进行API请求,获得关注的用户数据列表。
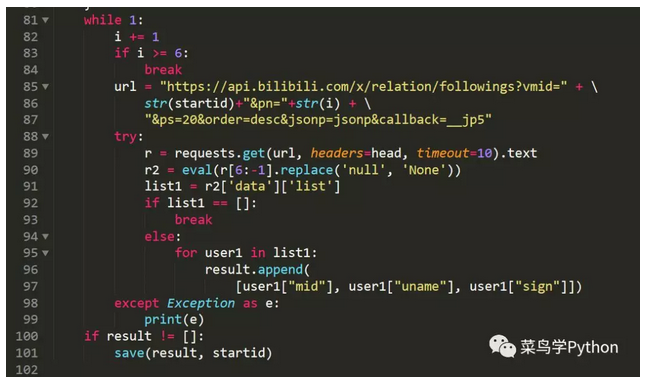
我们爬取前5页,每一页的数据进行简单的处理,然后转为字典数据进行获取mid,uname,sign3个维度的数据,最后save()函数存入db.
4.存入数据库
我们数据集里面一共有2个表,一个用户列表,用来存储所以的用户信息,一个是用户之间的关注信息。
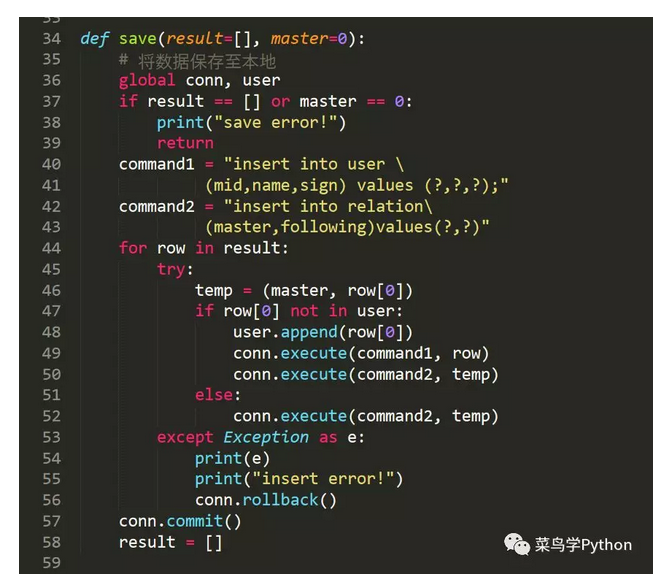
5.探秘是热门UP主
打算利用已经爬取到本地的数据进行词云的生成,来看一下这10万用户中共同的关注的哪些UP主出现的次数最多。
代码的思路主要是从数据库中获取用户的名字,重复的次数越多说明越多的用户关注,然后我使用fate的一张图片作为词云的mask图片,最后生成词云图片。
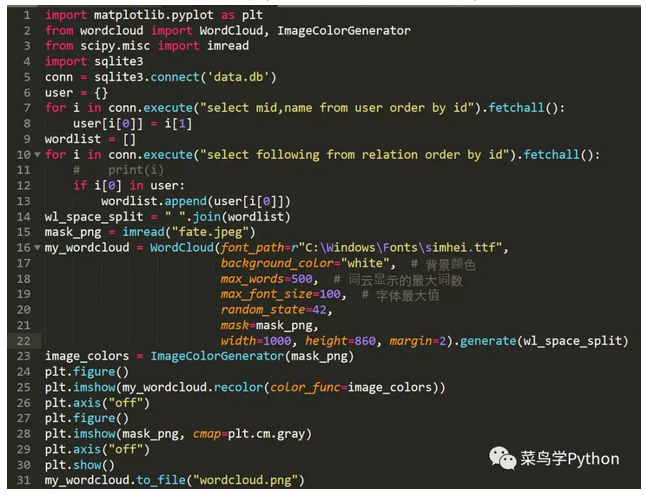
最后一起来看一下词云图

可以看出蕾丝,暴走漫画,木鱼水心,参透之C君,papi酱等B站大UP主都是热门关注。
