正文共:6724 字 19 图
预计阅读时间: 17 分钟
趋势显示的二维散点图
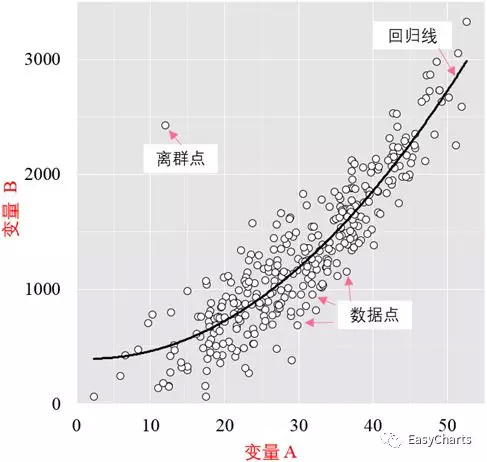
散点图(Scatter Graph, PointGraph, X-Y Plot, Scatter Chart或者 Scattergram)是科研绘图中最常见的图形类型之一,通常用于显示和比较数值。散点图是使用一系列的散点在直角坐标系中展示变量的数值分布。在二维散点图中,可以通过观察两个变量的数据分析,发现两者的关系与相关性,如图3-1-1所示。散点图可以提供三类关键信息:(1)变量之间是否存在数量关联趋势;(2)如果存在关联趋势,是线性还是非线性的;(3)观察是否有存在离群值,从而分析这些离群值对建模分析的影响。
 X
X
图 4-1-1 二维散点图
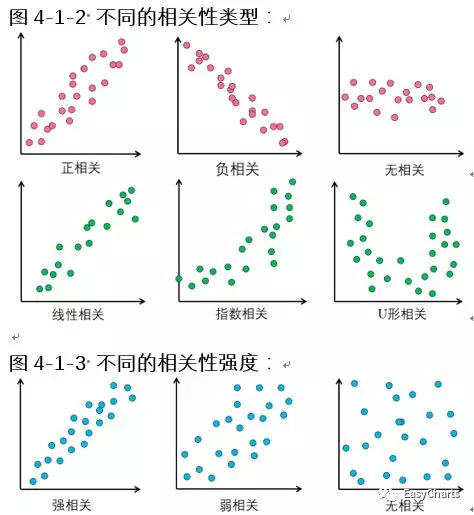
通过观察散点图上数据点的分布情况,我们可以推断出变量间的相关性。如果变量之间不存在相互关系,那么在散点图上就会表现为随机分布的离散的点,如果存在某种相关性,那么大部分的数据点就会相对密集并以某种趋势呈现。数据的相关关系主要分为:正相关(两个变量值同时增长)、负相关(一个变量值增加另一个变量值下降)、不相关、线性相关、指数相关等,表现在散点图上的大致分布如右图所示。那些离点集群较远的点我们称为离群点或者异常点(Outliers)。
 X
X
作为自变量的因素与作为因变量的预测对象是否有关,相关程度如何,以及判断这种相关程度的把握性多大,就成为进行回归分析必须要解决的问题。进行相关分析,一般要求出相关关系,以相关系数的大小来判断自变量和因变量的相关的程度:强相关、弱相关和无相关等。
 X
X
式中,Cov(X, Y)为X,Y的协方差,D(X)、D(Y)分别为X、Y的方差。散点图经常与回归线(Lineof Best Fit,就是最准确地贯穿所有点的线)结合使用,归纳分析现有数据实现曲线拟合,以进行预测分析。对于那些变量之间存在密切关系,但是这些关系又不像数学公式和物理公式那样能够精确表达的,散点图是一种很好的图形工具。但是在分析过程中需要注意,这两个变量之间的相关性并不等同于确定的因果关系,也可能需要考虑其他的影响因素。
回归分析构建检验因变量与一个或多个自变量的关系的数学模型。这些模型可以用于预测自变量的未观察值和/或未来值的响应。在简单情况下,从属变量y和独立变量x都是标量变量,给定对于i = 1,2,…, n的观察值(xi,yi),f是回归函数,ei是具有共同方差,σ2的零均值独立随机误差。回归分析的目的是构建f的模型,并基于噪声数据进行估计。
1 参数回归模型
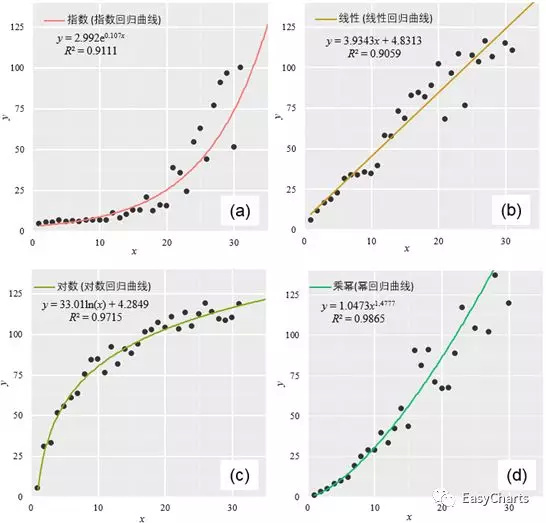
参数回归模型假定f的形式是已知的。曲线拟合(Curvefitting)是指选择适当的曲线类型来拟合观测数据,并用拟合的曲线方程分析两变量间的关系。绘图软件一般使用最小二乘法(Leastsquare method)实现拟合曲线的计算求取。回归分析(Regression analysis)是对具有因果关系的影响因素(自变量)和预测对象(因变量)所进行的数理统计分析处理。只有当变量与因变量确实存在某种关系时,建立的回归方程才有意义。按照自变量的多少,可分为一元回归分析和多元回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。比较常用的是多项式回归、线性回归和指数回归模型:
1. 指数回归模型:y=aebx,如图3-1-4(a);
2.线性回归模型:y=ax+b,如图3-1-4(b);
3. 对数回归模型:y=lnx+b,如图3-1-4(c);
4. 幂回归模型:y=axb,如图3-1-4(d);
5. 多项式回归模型:y=a1x+a2x2+···+anxn+b,其中n表示多项式的最高次项,如图3-1-1,回归曲线函数为:y = 1.0088x2- 3.9231x + 399.02,R² = 0.818,如图3-1-4(e);
 X
X
 X
X
 X
X
2 参数回归模型
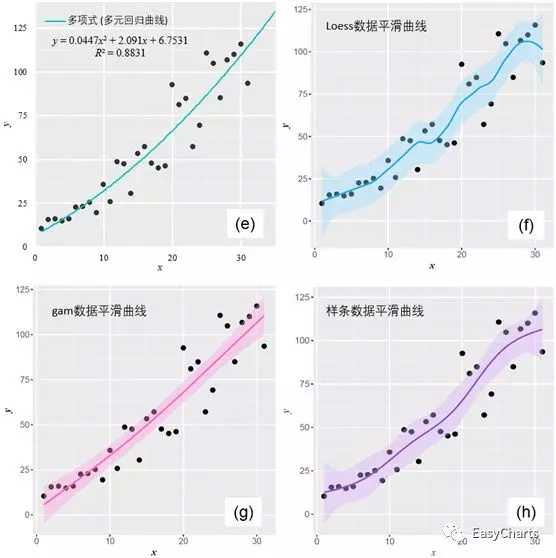
非参数回归模型不采用预定义形式。相反,它对f的定性性质做出假设。例如,可以愿意假设f是“平滑的”,其不会减少到具有有限数量的参数的特定形式。因此,非参数方法通常更灵活。它们可以揭示数据中可能被遗漏的结构。数据平滑(Data smooth)通过建立近似函数尝试抓住数据中的主要模式,去除噪音、结构细节或瞬时现象,来平滑一个数据集。在平滑过程中,信号数据点被修改,由噪音产生的单独数据点被降低,低于毗邻数据点的点被提升,从而得到一个更平滑的信号。平滑可以两种重要形式用于数据分析:1、若平滑的假设是合理的,可以从数据中获得更多信息;2、提供灵活而且稳健的分析。数据平滑的方法主要有:loess局部加权回归(locallyweighted scatterplot smoothing,LOWESS或LOESS)、gam广义可加模型(Generalisedadditive model)、Savitzky-Golay光滑、样条光滑(SmoothingSpline)
1. Loess数据平滑,主要思想是取一定比例的局部数据,在这部分子集中拟合多项式回归曲线,这样就可以观察到数据在局部展现出来的规律和趋势。曲线的光滑程度与选取数据比例有关:比例越少,拟合越不光滑,反之越光滑,如图3-1-4(f)所示;
2. gam数据平滑,在R语言中调用mgcv包拟合数据得到广义可加模型。广义可加模型的拟合是通过一个迭代过程(向后拟合算法)对每个预测变量进行样条平滑。其算法要在拟合误差和自由度之间进行权衡最终达到最优,如图3-1-4(g)所示;
3. 样条数据平滑,如图3-1-4(h)所示;
拟合的数值和实际数值就是残差(residual)。残差分析(residual analysis)就是通过残差所提供的信息,分析出数据的可靠性、周期性或其它干扰。用于分析模型的假定正确与否的方法。所谓残差是指观测值与预测值(拟合值)之间的差,即是实际观察值与回归估计值的差。
在回归分析中,测定值与按回归方程预测的值之差,以δ表示。残差δ遵从正态分布N(0,σ2)。(δ-残差的均值)/残差的标准差,称为标准化残差,以δ*表示。δ*遵从标准正态分布N(0,1)。实验点的标准化残差落在(-2,2)区间以外的概率≤0.05。若某一实验点的标准化残差落在(-2,2)区间以外,可在95%置信度将其判为异常实验点,不参与回归线拟合。
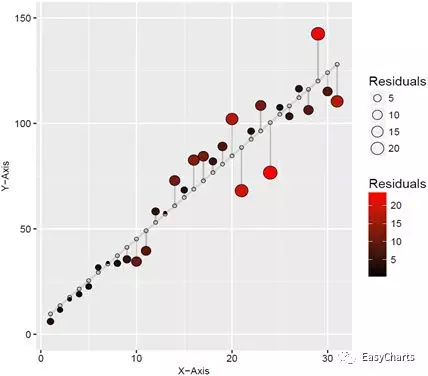
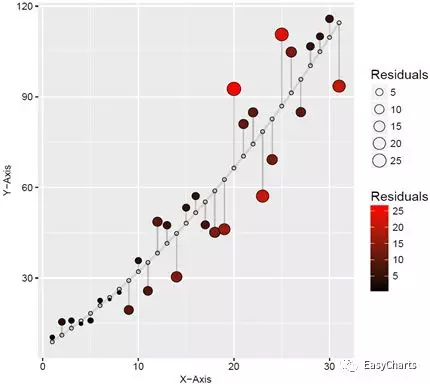
图3-1-5为使用R绘制的残差图,分别对应图3-1-4(b)线性拟合和(e)多项式拟合。采用黑色到红色渐变颜色和气泡面积大小两个视觉暗示对应残差的绝对值大小,用于实际数据点的表示;而拟合数据点则用小空心圆圈表示,并放置在灰色的拟合曲线上。并用直线连接实际数据点和拟合数据点。残差的绝对值越大,颜色越红、气泡也越大,连接直线越长,这样可以很清晰地观察数据的拟合效果。
 X
X
 X
X
图4-1-5残差分析图
图片类型散点图
图片类型散点图,就是使用图片置换数据点¡,有时候可以更加形象化地表达数据内容。一般来说,数据信息为(x,y, image)或者(x, y, z, image),其中image为数据点对应的图片,x和y分别定义直角坐标系中的数据点位置,z也可以定义数据点所展示的图片面积大小,类似于气泡图,如图3-1-6所示的梅丽尔·斯特里普的艺术人生。
梅丽尔·斯特里普是史上获得奥斯卡提名最多的演员,达到了难以置信的17次,更是3次捧得小金人,仅次于凯特林·赫本,和杰克·尼克儿森,英格丽·褒曼等并驾齐驱.在她N年的电影生涯中演过的角色不计其数,而且跨度很大。Vulture把这些角色按照从冷酷(cold)到温情(warm),从严肃(serious)和随性(frivolous)分类,绘制成了散点图。29个角色尽收眼底,看起来温情的比较多,严肃的也稍稍多过随性的。
 X
X
分布显示的二维散点图
1 单数据系列
1.1. Q-Q图和P-P图
关于统计分布的检验有很多种,例如KS检验、卡方检验等,从图形的角度来说,我们也可以使用QQ图或PP图来检查数据是否服从某种分布。P-P图(或Q-Q图)可检验的分布包括:贝塔分布(Beta)、T分布(Studentt)、卡方分布(Chi-square)、伽马分布(Gamma)、正态分布(Normal)、均匀分布(Uniform)、帕累托分布(Pareto)、Logistic分布(Logistic)等(http://www.cdadata.com/9232)。
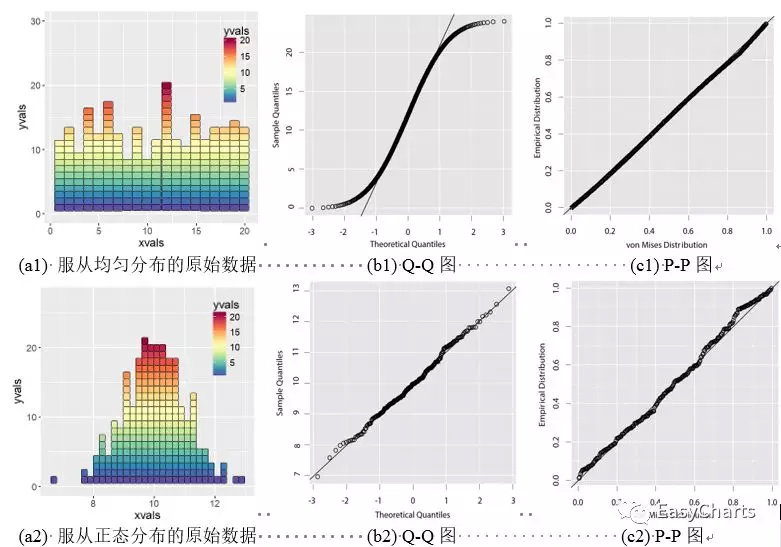
(1)Q-Q图(Quantile-QuantilePlot)是一种通过画出分位数来比较两个概率分布的图形方法。首先选定区间长度,点(x,y)对应于第一个分布(x轴)的分位数和第二个分布(y轴)相同的分位数。因此画出的是一条含参数的曲线,参数为区间个数。对应于正态分布的Q-Q图,就是由标准正态分布的分位数为横坐标,样本值为纵坐标的散点图。要利用Q-Q图鉴别样本数据是否近似于正态分布,只需看Q-Q图上的点是否近似地在一条直线附近,而且该直线的斜率为标准差,截距为均值,如图3-1-6(b2)所示。原始数据服从正态分布如图3-1-6(a2)所示,且标准差为1.0,均值为10.0。
QQ图的用途不仅在检查数据是否服从某种特定理论分布,它也可以推广到检查数据是否来自某个位置参数分布族。如果被比较的两个分布比较相似,则其Q-Q图近似地位于y = x上。如果两个分布线性相关,则Q-Q图上的点近似地落在一条直线上,但并不一定是y = x这条线。Q-Q图可以比较概率分布的形状,从图形上显示两个分布的位置,尺度和偏度等性质是否相似或不同。一般来说,当比较两组样本时,Q-Q图是一种比直方图更加有效的方法,但是理解Q-Q图需要更多的背景知识。
(2)P-P图 (Probability–Probability Plot 或 Percent–Percent Plot)是根据变量的累积比例与指定分布的累积比例之间的关系所绘制的图形。通过P-P图可以检验数据是否符合指定的分布。当数据符合指定分布时,P-P图中各点近似呈一条直线。如果P-P图中各点不呈直线,但有一定规律,可以对变量数据进行转换,使转换后的数据更接近指定分布。P-P图和Q-Q图的用途完全相同,只是检验方法存在差异。
 X
X
图4-1-8 Q-Q图和P-P图的对比分析
1.2. 分类图
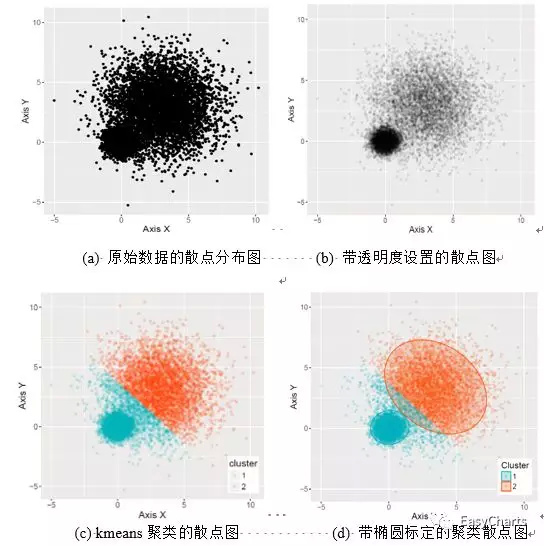
散点图通常用于显示和比较数值,不光可以显示趋势,还能显示数据集群的形状,以及在数据云团中各数据点的关系。这类散点图很适合用于聚类分析中,根据二维特征对数据进行类别区分。常用的聚类分析方法包括kmeans、FCM、KFCM、DBSCAN、MeanShift等聚类方法。Python的scikit-learn包中专门对多种聚类算法(clustering)进行实现与对比(http://scikit-learn.org/stable/modules/clustering.html#clustering)。同时也推荐大家一本关于R语言聚类算法的书籍:Alboukadel Kassambara. Practical Guide to Cluster Analysis inR,里面有队各种聚类算法的详细说明。对于高密度的散点图可以利用数据点的透明度观察数据的形状和密度,如图3-1-7所示。
 X
X
图4-1-9 高密度散点图
2 多数据系列
多数据系列的散点图需要使用不同的颜色填充(Fill)和数据点形状(Shape)两个视觉特征,表示数据系列。如图3-1-8所示,图(a)只使用不同的颜色填充区分数据系列,图(b)就是使用不同颜色填充和不同形状两个视觉特征,同时区分数据系列,即使在黑白印刷时也能保证读者清晰地区分数据系列。R语言ggplot2包可供选择的形状(shape)如图3-1-9所示,总共20种不同类型的形状,而Origin软件中可供选择的形状更多。Excel、Origin、Python等软件中也存在不同的形状,最常用就是圆形○、菱形◇、方形□、三角形△等。
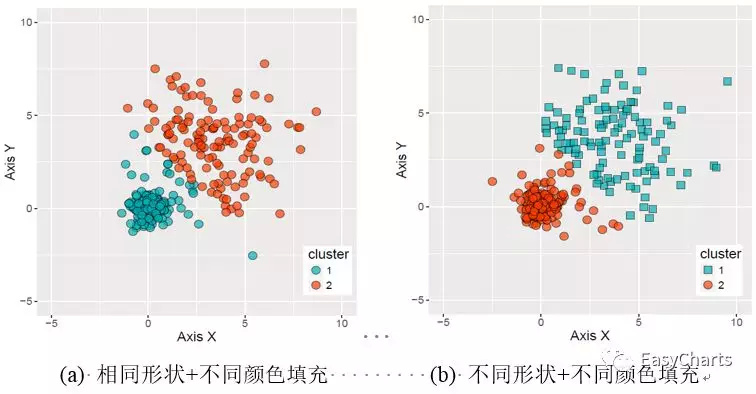 X
X
图4-1-10 多数据系列散点图
气泡图
气泡图是一种多变量图表,是散点图的变体,也可以认为是散点图和百分比区域图的组合。气泡图最基本的用法是使用三个值来确定每个数据序列,和散点图一样,气泡图将两个维度的数据值分别映射为笛卡尔坐标系上的坐标点,其中 X 和Y 轴分别代表不同的两个维度的数据,但是不同于散点图的是,每一个气泡的面积代表第三个维度的数据。气泡图通过气泡的位置以及面积大小,可分析数据之间的相关性。
需要注意的是圆圈状气泡的大小是映射到面积(CircleArea)而不是半径(Circle Radius)或者直径(CircleDiameter)绘制的。因为如果是基于半径或者直径的话,圆的大小不仅会呈指数级变化,而且还会导致视觉误差。
Circle Area=π × (CircleDiameter/2)2
CircleDiameter=(SQRT(Area/π))×2
如图3-1-9(a)所示只使用面积大小(1个视觉特征)来表示气泡图,为了避免数据的重叠遮挡,一般设置气泡的透明度。添加填充颜色渐变的气泡图(2个视觉特征),如图(b)所示,第三维变量“disp”不仅映射到气泡大小,而且还映射到填充颜色,这样能使读者更加清晰地观察数据变化关系。在图(b)气泡图的基础上添加数据标签(第三维变量“disp”,即气泡的面积大小),如图(c)所示;但是需要注意不要出现太严重的数据标签的重叠(overlap)。图(d)只是在图(b)的基础上把圆圈状的气泡换成方块状,给人的视觉感受与图(b)截然不同。图(b)和图(d)并不能判断谁更好看,“萝卜白菜,各有所爱”,你喜欢使用哪种类型,就可以绘制哪种类型。
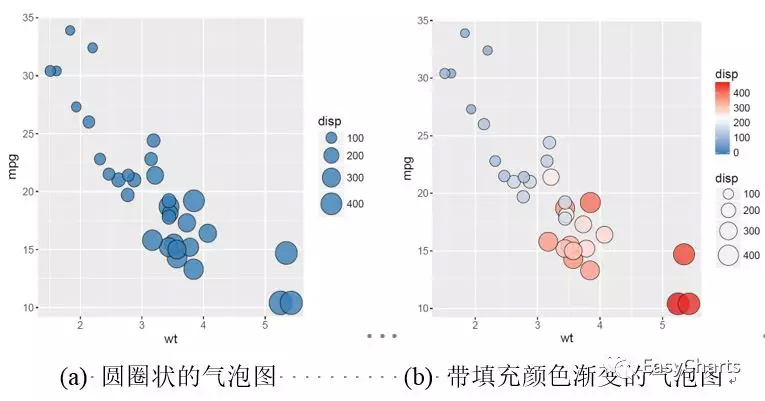 X
X
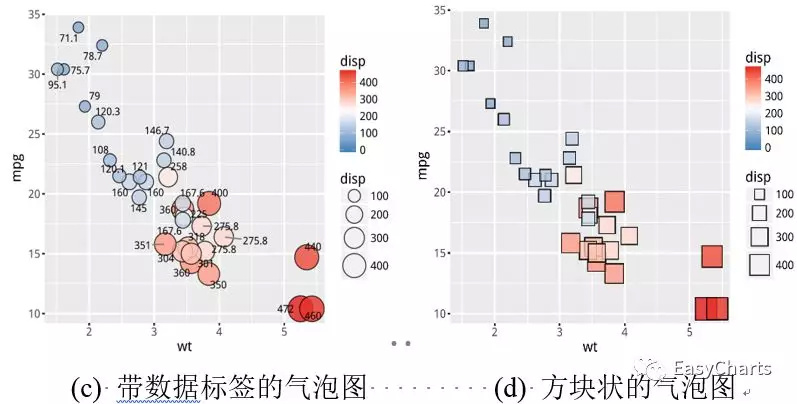 X
X
4-1-12 多数据系列散点图
泡图的数据大小容量有限,气泡太多会使图表难以阅读。静态的气泡图最好只表达3个维度的数据:X 和Y 轴分别代表不同的两个维度的数据;同时使用气泡的面积和颜色,或者只使用气泡面积,代表第三个维度的数据。
对于多数据系列气泡图(第4个维度为数据类别),虽然可以使用不同的颜色区分不同类别,但是推荐使用后面章节讲解的Trellis / Facet Grid图展示数据。使用交互可视化的气泡图,可以通鼠标点击或者悬浮时显示气泡信息,或者添加选项控件用于重组或者过滤分组类别,但是交互可视化的方法制作的图表几乎不应用在学术论文图表中。
对于时间维度的气泡图可以结合动画来表现数据随着时间的变化情况。HansRosling把气泡图用得神乎其技,他是瑞典卡罗琳学院全球公共卫生专业教授。有关他利用数据可视化显示200多个国家200年来的人均寿命和经济发展的TED视频非常火(http://www.gapminder.org/answers/how-does-income-relate-to-life-expectancy/)
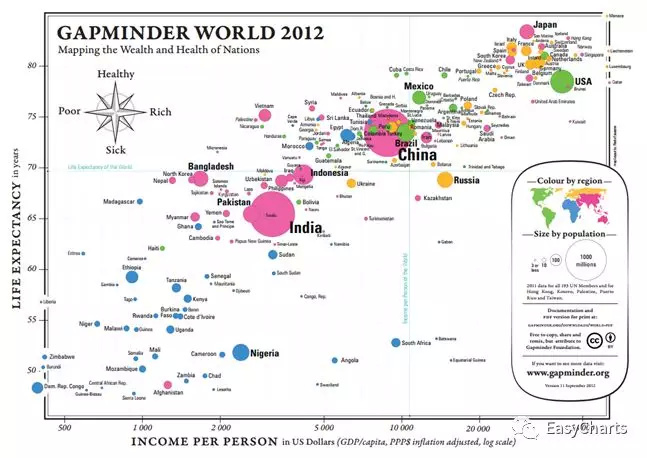 X
X
图4-1-13 不同国家的人均收入气泡图
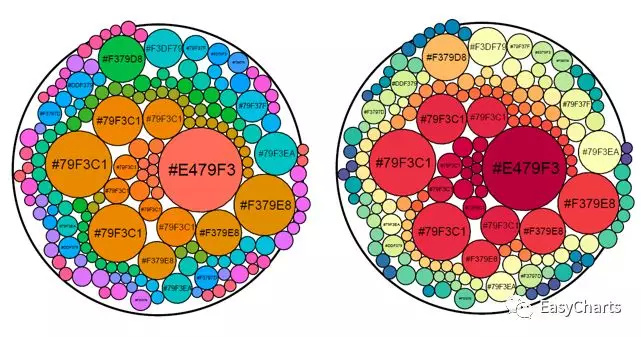
ClusteredForce LayoutAlso called: Grouped bubble chart, clustered bubble chart. Nested circles allow to representhierarchies and compare values. This visualization is particularly effective toshow the proportion between elements through their areas and their positioninside a hierarchical structure.
 X
X
欢迎大家加入QQ群一起探讨学习
 X
X
 X
X

