# coding: utf-8
# In[2]:
import numpy as np
import pandas as pd
import seaborn as sns
from scipy import stats
import statsmodels.api as sm
from statsmodels.formula.api import ols
from matplotlib import pyplot as plt
pd.set_option('display.max_columns', None)
import warnings
warnings.filterwarnings('ignore')
get_ipython().magic('matplotlib inline')
# In[3]:
sndHsPr = pd.read_csv(r'sndHsPr.csv')
sndHsPr.head()
sndHsPr = pd.read_csv(r'sndHsPr.csv')
sndHsPr.head()
# # 因变量分析:单位面积房价分析
# In[3]:
sndHsPr['price'].describe()

# In[4]:
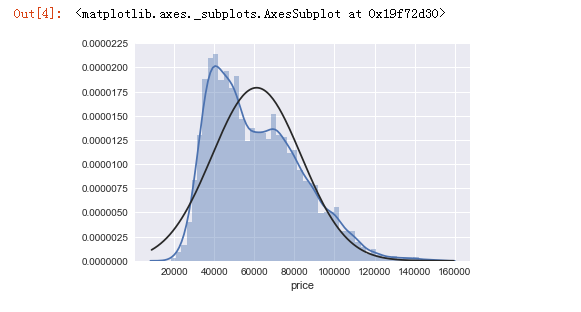
sns.distplot(sndHsPr['price'], kde=True, fit=stats.norm)
# In[5]:
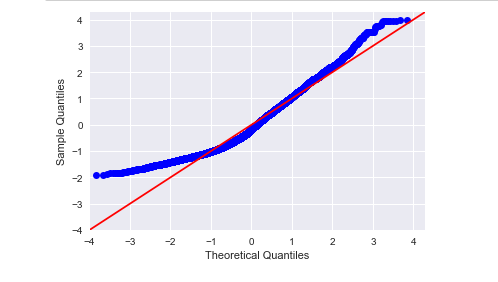
fig = sm.qqplot(sndHsPr['price'], fit=True, line='45')
fig.show()
# In[6]:
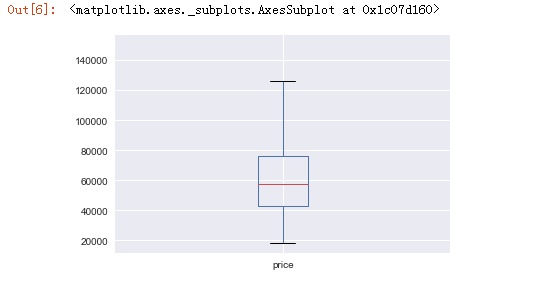
sndHsPr['price'].plot(kind='box')
# # 自变量分析
# ## 自变量自身分布分析
# In[7]:
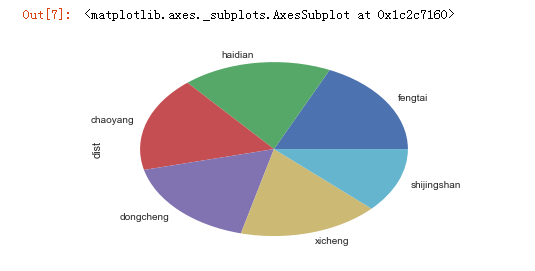
sndHsPr['dist'].value_counts().plot(kind='pie')
# In[8]:
sndHsPr['roomnum'].value_counts().plot(kind='bar')
# In[9]:
sndHsPr['halls'].value_counts().plot(kind='bar')
# In[10]:
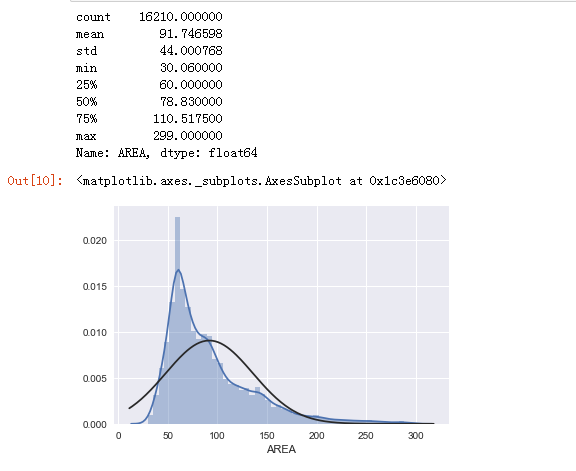
print(sndHsPr['AREA'].describe())
sns.distplot(sndHsPr['AREA'], kde=True, fit=stats.norm)
# In[11]:
sndHsPr['floor'].value_counts().plot(kind='bar')
# In[12]:
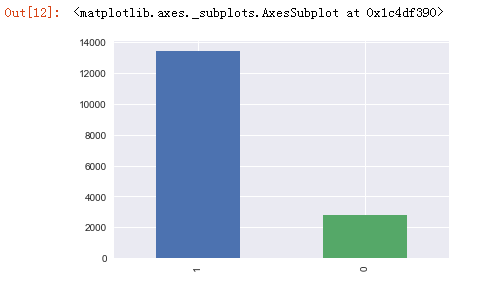
sndHsPr['subway'].value_counts().plot(kind='bar')
# In[13]:
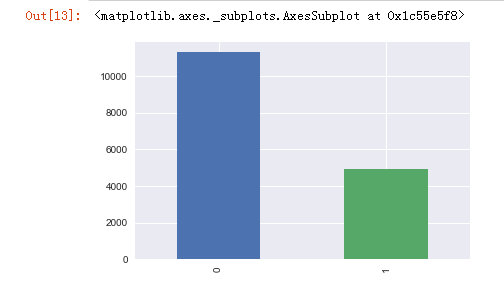
sndHsPr['school'].value_counts().plot(kind='bar')
# ## 自变量对因变量影响分析
# In[14]:
def anova_analyze(x):
# print(sndHsPr.groupby(x)[['price']].describe().T)
print("="*50)
anova_res = sm.stats.anova_lm(ols('price ~ C(%s)'%x,data=sndHsPr).fit())
print(anova_res)
print("="*50)
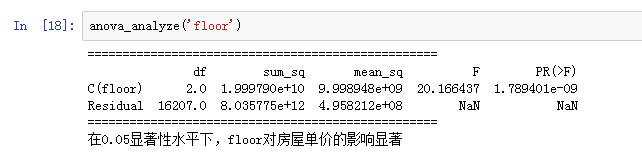
if anova_res.loc['C(%s)'%x,'PR(>F)']<0.05:
print( '在0.05显著性水平下,%s对房屋单价的影响显著'%x)
else:
print( '在0.05显著性水平下,%s对房屋单价的影响不显著'%x)
# In[15]:
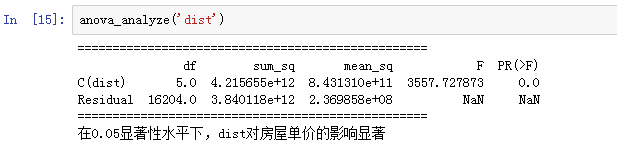
anova_analyze('dist')
# In[16]:
anova_analyze('roomnum')

# In[17]:
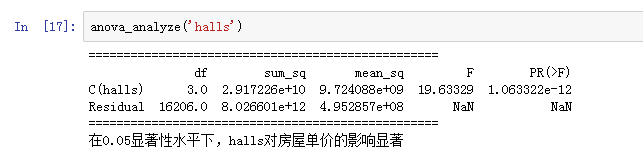
anova_analyze('halls')
# In[18]:
anova_analyze('floor')
# In[19]:
# print(sndHsPr['price'].groupby(sndHsPr['school']).describe().T)
val_0= sndHsPr[sndHsPr['school'] == 0]['price'].dropna()
val_1 = sndHsPr[sndHsPr['school'] == 1]['price'].dropna()
leveneTestRes = stats.levene(val_0, val_1, center='median')
print("="*50)
print('w-value=%6.4f, p-value=%6.4f' %leveneTestRes)
print("="*50)
print(stats.stats.ttest_ind(val_0, val_1, equal_var=True))
print( '在0.05显著性水平下,school对房屋单价的影响显著')

# In[20]:
# print(sndHsPr['price'].groupby(sndHsPr['subway']).describe().T)/
val_0= sndHsPr[sndHsPr['subway'] == 0]['price'].dropna()
val_1 = sndHsPr[sndHsPr['subway'] == 1]['price'].dropna()
leveneTestRes = stats.levene(val_0, val_1, center='median')
print("="*50)
print('w-value=%6.4f, p-value=%6.4f' %leveneTestRes)
print("="*50)
print(stats.stats.ttest_ind(val_0, val_1, equal_var=True))
print( '在0.05显著性水平下,subway对房屋单价的影响显著')

# In[21]:
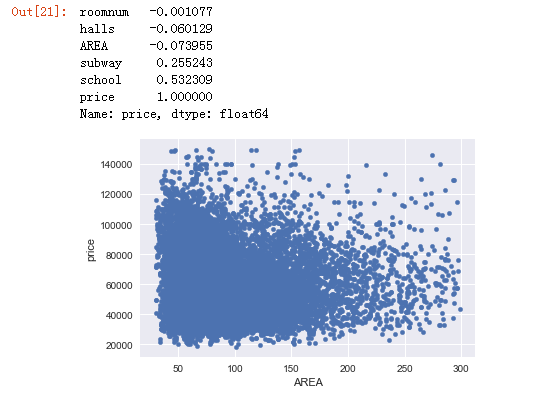
sndHsPr.plot(x='AREA', y='price', kind='scatter')
sndHsPr.corr(method='pearson')['price']
# # 建立房价预测模型
# In[22]:
'''forward select'''
def forward_select(data, response):
remaining = set(data.columns)
remaining.remove(response)
selected = []
current_score, best_new_score = float('inf'), float('inf')
while remaining:
aic_with_candidates=[]
for candidate in remaining:
formula = "{} ~ {}".format(
response,' + '.join(selected + [candidate]))
aic = ols(formula=formula, data=data).fit().aic
aic_with_candidates.append((aic, candidate))
aic_with_candidates.sort(reverse=True)
best_new_score, best_candidate=aic_with_candidates.pop()
if current_score > best_new_score:
remaining.remove(best_candidate)
selected.append(best_candidate)
current_score = best_new_score
print ('aic is {},continuing!'.format(current_score))
else:
print ('forward selection over!')
break
formula = "{} ~ {} ".format(response,' + '.join(selected))
print('final formula is {}'.format(formula))
model = ols(formula=formula, data=data).fit()
return(model)
# ## 线性回归模型
# In[23]:
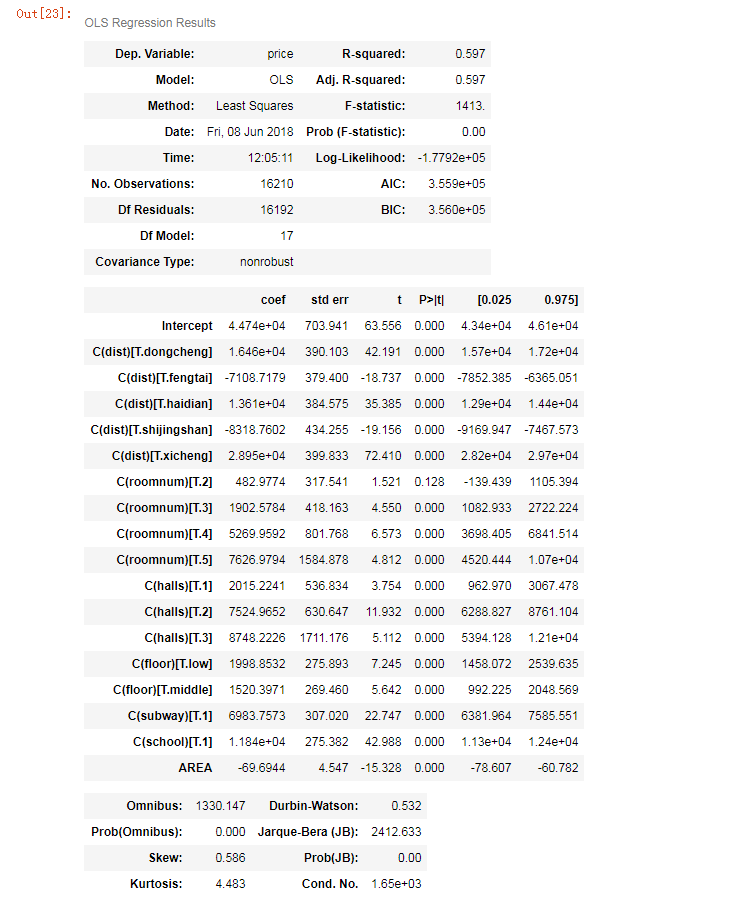
lm_m = ols('price ~ C(dist) + C(roomnum) + C(halls) + AREA + C(floor) + C(subway) + C(school)',
data=sndHsPr).fit()
lm_m.summary()
# In[24]:
data_for_select = sndHsPr
lm_m = forward_select(data=data_for_select, response='price')
print(lm_m.rsquared)

# ## 对因变量取对数的线性模型
# In[25]:
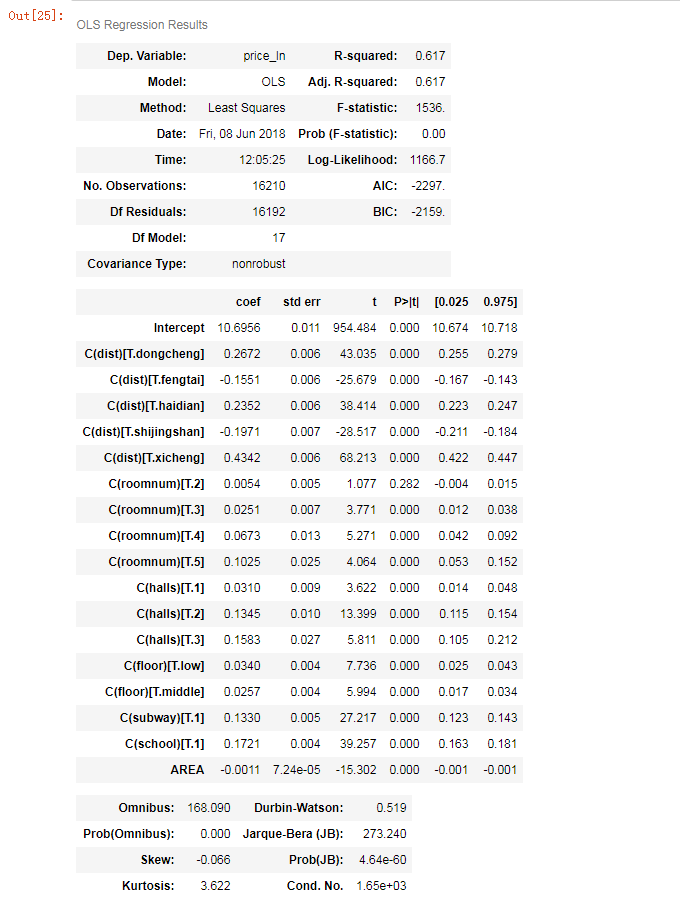
sndHsPr['price_ln'] = np.log(sndHsPr['price'])
lm_m = ols('price_ln ~ C(dist) + C(roomnum) + C(halls) + AREA + C(floor) + C(subway) + C(school)',
data=sndHsPr).fit()
lm_m.summary()
# # 预测: 假设有一家三口,父母为了能让孩子在东城区上学,想买一套邻近地铁的两居室,面积是70平方米,中层楼层,那么房价大约是多少呢?
# In[26]:
lm_m.predict(pd.DataFrame([['dongcheng',2,0,70.0,'middle',1,1],],columns = ['dist', 'roomnum', 'halls', 'AREA', 'floor', 'subway', 'school']))

