'''
研究二手房价的影响因素,建立房价预测模型,数据存放在“sndHsPr.csv”中。
分析思路:
在对房价的影响因素进行模型研究之前,首先对各变量进行描述性分析,以初步判断房价的影响因素,进而建立房价预测模型
变量说明如下:
dist-所在区
roomnum-室的数量
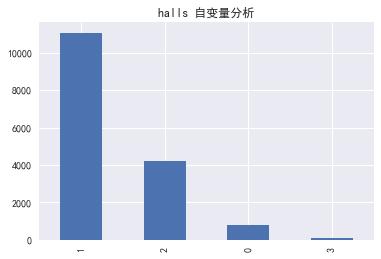
halls-厅的数量
AREA-房屋面积
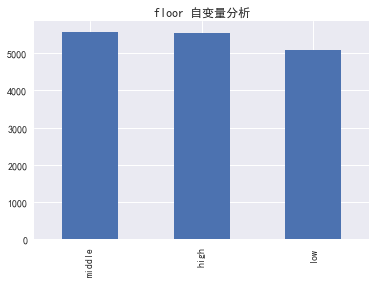
floor-楼层
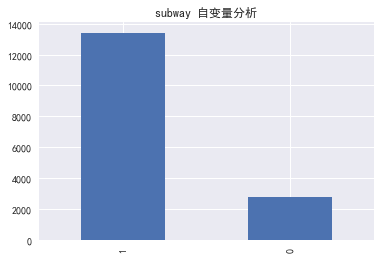
subway-是否临近地铁
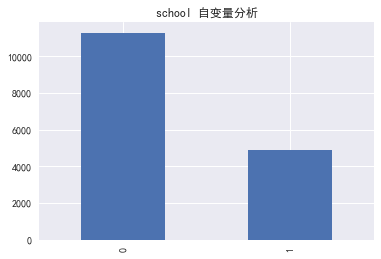
school-是否学区房
price-平米单价
步骤如下:
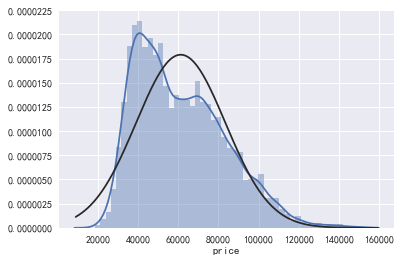
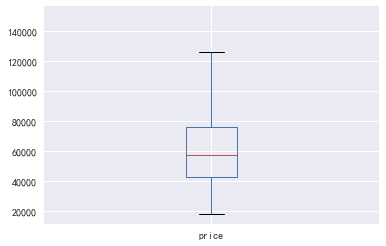
(一) 因变量分析:单位面积房价分析
(二) 自变量分析:
2.1 自变量自身分布分析
2.2 自变量对因变量影响分析
(三)建立房价预测模型
3.1 线性回归模型
3.2 对因变量取对数的线性模型
3.3 考虑交互项的对数线性
(四)预测: 假设有一家三口,父母为了能让孩子在东城区上学,想买一套邻近地铁的两居室,面积是70平方米,中层楼层,那么房价大约是多少呢?
'''
import pandas as pd
import os
os.chdir(r'D:\Learningfile\天善学院\280_Ben_八大直播八大案例配套课件\提交-第四讲:统计建模与分析报告-二手房价格分析报告\作业')
data=pd.read_csv('sndHsPr.csv')
# In[]
#(一) 因变量分析:单位面积房价分析
data.describe(include='all')
# Histograph
get_ipython().magic('matplotlib inline')
import seaborn as sns
from scipy import stats
sns.distplot(data.price,kde=True,fit=stats.norm)
# In[]
data.price.plot(kind='box')
# In[]
#(二) 自变量分析:
# 2.1 自变量自身分布分析
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
column=['dist','roomnum','halls','floor','subway','school']
for i in column:
data[i].value_counts().plot(kind='bar')
plt.title('%s 自变量分析' % i)
plt.show()
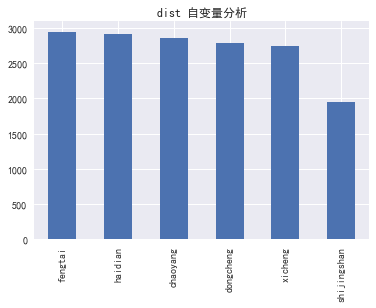
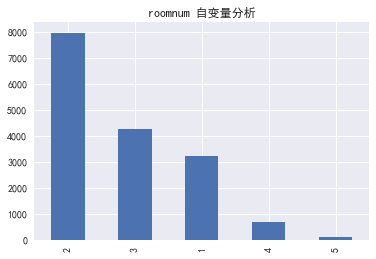
# In[]
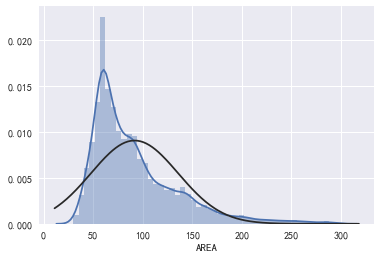
print('AREA自变量分析')
sns.distplot(data['AREA'],kde=True,fit=stats.norm)
plt.show()
# In[]
# 2.2 自变量对因变量影响分析
from scipy import stats
import statsmodels.api as sm
from statsmodels.formula.api import ols
for i in column:
print(sm.stats.anova_lm(ols('price~C(data[i])',data=data).fit()),'\n')
#######################################################
df sum_sq mean_sq F PR(>F)
C(data[i]) 5.0 4.215655e+12 8.431310e+11 3557.727873 0.0
Residual 16204.0 3.840118e+12 2.369858e+08 NaN NaN
df sum_sq mean_sq F PR(>F)
C(data[i]) 4.0 6.703058e+09 1.675764e+09 3.373776 0.009113
Residual 16205.0 8.049070e+12 4.967029e+08 NaN NaN
df sum_sq mean_sq F PR(>F)
C(data[i]) 3.0 2.917226e+10 9.724088e+09 19.63329 1.063322e-12
Residual 16206.0 8.026601e+12 4.952857e+08 NaN NaN
df sum_sq mean_sq F PR(>F)
C(data[i]) 2.0 1.999790e+10 9.998948e+09 20.166437 1.789401e-09
Residual 16207.0 8.035775e+12 4.958212e+08 NaN NaN
df sum_sq mean_sq F PR(>F)
C(data[i]) 1.0 5.248249e+11 5.248249e+11 1129.520799 1.933784e-239
Residual 16208.0 7.530948e+12 4.646439e+08 NaN NaN
df sum_sq mean_sq F PR(>F)
C(data[i]) 1.0 2.282627e+12 2.282627e+12 6408.431518 0.0
Residual 16208.0 5.773146e+12 3.561912e+08 NaN NaN
##########################################################
# In[]
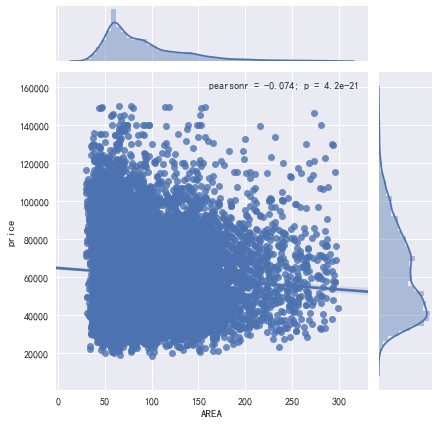
print('AREA对price影响分析')
sns.jointplot('AREA','price',data,kind='reg')
plt.show()
####################################################
########################################
# In[]
'''
(三)建立房价预测模型
3.1 线性回归模型
'''
'''forward select'''
def forward_select(data, response):
remaining = set(data.columns)
remaining.remove(response)
selected = []
current_score, best_new_score = float('inf'), float('inf')
while remaining:
aic_with_candidates=[]
for candidate in remaining:
formula = "{} ~ {}".format(
response,' + '.join(selected + [candidate]))
aic = ols(formula=formula, data=data).fit().aic
aic_with_candidates.append((aic, candidate))
aic_with_candidates.sort(reverse=True)
best_new_score, best_candidate=aic_with_candidates.pop()
if current_score > best_new_score:
remaining.remove(best_candidate)
selected.append(best_candidate)
current_score = best_new_score
print ('aic is {},continuing!'.format(current_score))
else:
print ('forward selection over!')
break
formula = "{} ~ {} ".format(response,' + '.join(selected))
print('final formula is {}'.format(formula))
model = ols(formula=formula, data=data).fit()
return(model)
data=data[['price','dist','roomnum','halls','floor','subway','school','AREA']]
data_dummy=pd.get_dummies(data)
lm=forward_select(data_dummy,'price')
print(lm.rsquared)
##################################
final formula is price ~ school + dist_xicheng + dist_dongcheng + dist_haidian + dist_chaoyang + subway + halls + AREA + floor_high + roomnum + dist_fengtai + floor_low
0.595909133228
##################################
# In[]
# 3.2 对因变量取对数的线性模型
import numpy as np
data_dummy_ln=data_dummy.copy()
data_dummy_ln['price_ln']=data_dummy_ln['price'].apply(lambda x:np.log(x))
data_dummy_ln.drop(['price'],axis=1,inplace=True)
lm_ln=forward_select(data_dummy_ln,'price_ln')
print(lm_ln.rsquared)
############################################
final formula is price_ln ~ school + dist_xicheng + dist_dongcheng + dist_haidian + dist_chaoyang + subway + halls + AREA + floor_high + dist_shijingshan + roomnum + floor_low
0.615424508234
#############################################
# In[]
# 3.3 考虑交互项的对数线性
data_dummy_ln['sub_sch']=data_dummy_ln['subway']+data_dummy_ln['school']
lm_ln2=forward_select(data_dummy_ln,'price_ln')
print(lm_ln2.rsquared)
##############################################
final formula is price_ln ~ sub_sch + dist_xicheng + dist_dongcheng + dist_haidian + dist_chaoyang + halls + AREA + floor_high + dist_fengtai + school + roomnum + floor_low
0.615424508234
##############################################
# In[]
#(四)预测: 假设有一家三口,父母为了能让孩子在东城区上学,想买一套邻近地铁的两居室,面积是70平方米,中层楼层,那么房价大约是多少呢?
list=[{"roomnum":3,"halls":0,"AREA":70,"subway":1,"school":1,"dist_chaoyang":0,"dist_dongcheng":1,\
"dist_fengtai":0,"dist_haidian":0,"dist_shijingshan":0,"dist_xicheng":0,"floor_high":0,\
"floor_low":0,"floor_middle":1,"sub_sch":2,"price_ln":0}]
data2=pd.DataFrame(list)
np.exp(lm_ln2.predict(data2))
#############################################
0 72906.932096
dtype: float64
