之前的一篇文章实践了微博这类短文本可以进行的分析,没有讲数据的来源。因此我打算记录一些爬虫方面的实践,毕竟爬虫是我很需要深入的部分,欢迎大家指教。这里讨论一下淘宝商品的评论的爬取。用的工具还是利器Python。
Python爬取简单页面还是比较套路的,要么直接爬取HTML页面,要么爬取对应的json页面,当然这里不考虑验证码需要登录等情况。淘宝的页面数据是异步加载的,所以要到相应的json文件里找对应的数据,评论数据都是装载在json里再经过JavaScript处理后显示到HTML页面里的。下面我们来实战一下华为荣耀畅玩7C这款手机在天猫旗舰店的评价,在淘宝上搜索荣耀畅玩7C定位到官方页面,之后按F12打开源码,定位到Network,因为默认F12的开发者选项的页面是对应Elements的,按F5刷新页面后在Network里对应找到相关的json文件,实际爬过一些小项目的人应该很熟悉上面的操作了。如下图:
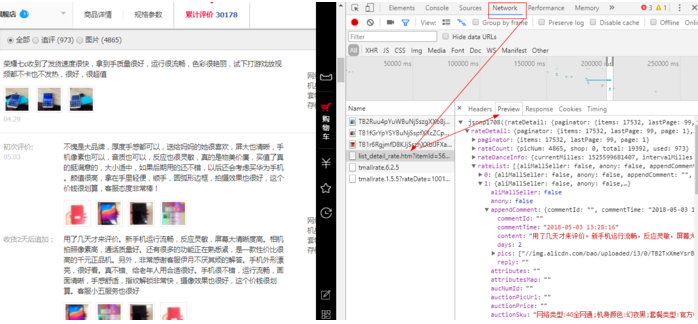
点击Headers可以看到对应的URL和请求方式(是get还是post)
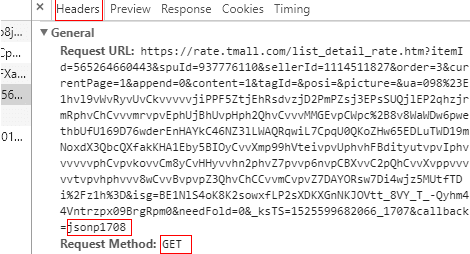
可以看到URL很长,里面封装了大量的参数,用这个url可以爬取评论的单个页面,但是要连续爬取各个页面的评论挺困难的,我研究了很久试了很多次callback参数的改变,效果不是很好,后来查网上的资料发现可以简化参数,将后面的参数削减掉,只保留几个必要的参数,变成:https://rate.taobao.com/feedRateList.htm?auctionNumId=商品id¤tPageNum=1,改变currentPageNum就好,于是开始完善代码,用requests获得数据后,用json将str类型的数据变成json数据,然后解析json数据,提取评论中自己关注的数据写入csv文件中,这里懒得用csv库了,直接当做文本文件进行读写。代码如下:
import requests
import json
import re
def getOneUrl(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return -1 # 页面没正常下下来
首先是比较套路的获取单个页面数据,就是调用了 requests.get(url)
def getOverViewComment():#评论概览
oc_url = "https://rate.tmall.com/listTagClouds.htm?" \
"itemId=565264660443&isAll=true&isInner=true"
ovtxt=getOneUrl(oc_url)
print(ovtxt)
#jsonp921({"tags":{"dimenSum":8,…… loudList":""}})
if ovtxt==-1:
return
#ov2=re.compile('\{.+\}').search(ovtxt) #json的部分
ovc = json.loads('{'+ovtxt+'}')
print(ovc["tags"]["rateSum"])
for tc in ovc['tags']['tagClouds']:
print(tc['tag'],tc)
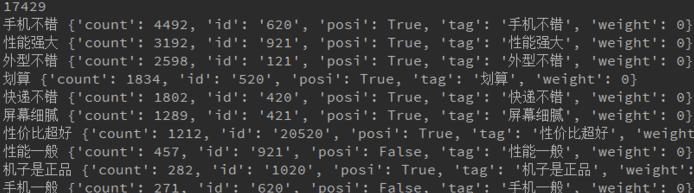
函数getOverViewComment()是获取荣耀畅玩7C的评论概览数据,对应HTML里的效果如下:

getOverViewComment()运行的输出如下:
下面的代码功能是获取和解析每个页面的评论数据,具体代码不难理解的。
def parseCommentJson(url, savep): # 解析每个页面的json数据
text = getOneUrl(url)
if text == -1:
print('页面没正常获取', url)
return -1
hc = json.loads(text.strip().strip('()')) # 除掉空格和首尾括号
if (hc['total'] == 0 or hc['comments'] == None):
return 0
print(hc['total'])
with open(savep, 'a+', encoding='utf-8') as wf:
for each_c in hc['comments']: #循环每条评论
wstr = '{name},{date},{ct},{sku}'.format(name=each_c['user']['nick'],
date=each_c['date'], ct=each_c['content'],
sku=each_c['auction']['sku'])
aplst = each_c['appendList']
addstr = ''
if aplst != []: # 有追评
for adict in aplst:
astr = ',{dac},{act}'.format(dac=str(adict['dayAfterConfirm']), act=adict['content'])
addstr = addstr+astr
wf.write(wstr+addstr+'\n')
def honorComment():
for i in range(1,101):#结束页面可以自由改,如果要全量爬就设大一些,每个页面大概有20条 30115/20
url='https://rate.taobao.com/feedRateList.htm?auctionNumId={cid}&' \
'currentPageNum={page}'.format(cid='565264660443',page=str(i))
savep='D:/FFOutput/honor7cComment_{page}.csv'.format(page=str(i)) #直接page=i 也是可以的
#page不迭代时,是写到同一个文件里,省得去合并了
if (parseCommentJson(url,savep)==0):
break #后面没有评论了
honorComment() #调用
代码也可以进行拓展,例如获取评论里的其他属性,我这里主要爬了用户名称、评价时间、评价内容、购买类型以及追评的数据。需要其他数据可以自己改一下代码,并不难。
最后的数据效果如下,我只爬了前100页的数据。

数据拿下来之后可以按照之前微博文本的分析思路进行分析,例如每天的评价数:评价数随时间变化的折线图、结合促销手段、其他手机的发布时间等数据去理解评价数随时间的变化,分析荣耀10发布是否对荣耀畅玩7C的销量有影响;各种类型售出的比例:大家是更喜欢3G内存版本还是4G内存版本,大家更喜欢哪种颜色;对于核心的评论文本,可以结合自然语言处理进行深入分析,例如情感分析,调用API或库分析情感,对有追评数据的分析前后的情感变化,做词云图进行可视化等等。
