1、Partition(分区)
为了使得kafka吞吐量线性提高,物理上把topic分成一个或者多个分区(一般小于等于集群的个数),每一个分区是一个有序的队列。且每一个分区在物理上都对应着一个文件夹,该文件夹下存储这个分区所有消息和索引文件。主题是发布记录的类别或名称,Kafka中的主题总是有多个订阅者。也就是说,一个主题可以有0个、1个或多个订阅到它的Consumer。
对于每个主题,Kafka集群维护一个分区日志,如下所示:
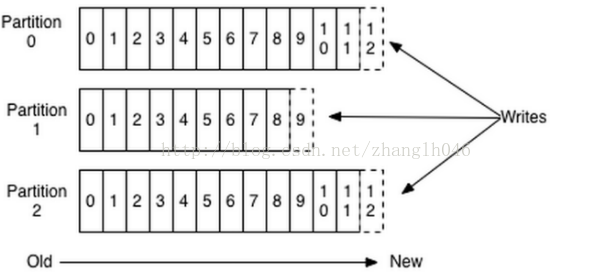
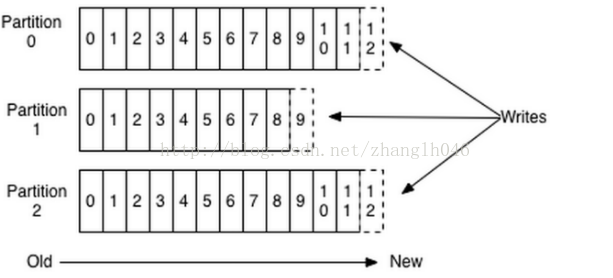
每个分区都是一个有序的、不可变的记录序列,并不断地追加到一个结构化的提交日志中。分区中的记录都被分配了一个名为offset 的连续id号,该offset惟一地标识分区中的每个记录。Kafka集群可以按照可配置的保留期保存所有已发布的记录(无论它们是否被消费)。例如保留策略被设置为1天,那么在记录发布后的1天内,可以使用它,然后将其丢弃以释放空间。Kafka在数据大小方面的性能实际上是持续的,因此长时间存储数据不是问题。
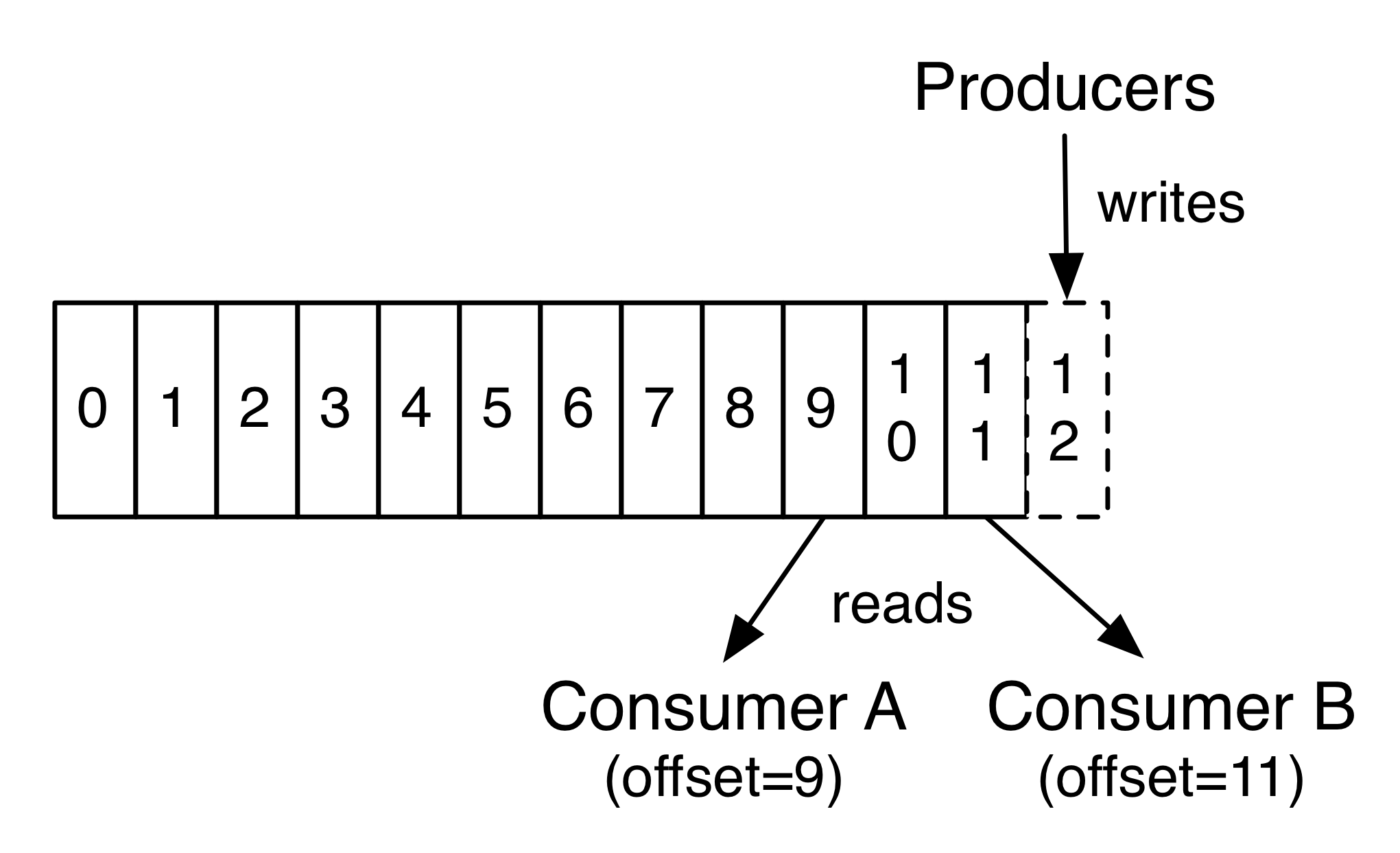
每写一条记录,会产生一个新的连续的offset,如上图。Consumer消费记录时,会根据指定的offset从分区中重复读取记录。
2、Replicas(副本)
假设没有Replicas,一旦某一个Broker宕机,则所有的Partition数据都不可被消费,所以需要对分区备份。其中一个宕机后其它Replica必须要能继续服务并且即不能造成数据重复也不能造成数据丢失。副本之间有一个Leader,只有Leader负责数据读写,Follower只向Leader顺序获取数据,系统更加简单且高效,保证数据的一致性和有序性,避免Replication实现的复杂性和出现异常的几率。
每一个分区根据副本因子,会有N个副本(通常设置为3)。比如在broker1上有一个topic,分区为topic-1, 复制因子为2,那么在两个broker的数据目录里,就都有一个topic-1,其中一个是leader,一个replicas。同一个Partition可能会有多个Replica,而这时需要在这些Replication之间选出一个Leader,Producer和Consumer只与这个Leader交互,其它Replica作为Follower从Leader中复制数据。
