看下面内容前,我假设你已经学习了前面的:如何用最通俗易懂的方式理解假设检验。并了解了假设检验的基本步骤:

下面我们通过一个案例来聊聊假设检验的第1种类型:单样本检验。
“超级引擎”是一家专门生产汽车引擎的公司,根据政府发布的新排放标准要求,引擎排放平均值要低于20ppm。(ppm是英文百万分之一的缩写,这里我们只要理解为是按照环保要求汽车尾气中碳氢化合物要低于20ppm)
这家公司制造出10台引擎供测试使用,每一台的排放水平如下:

怎么知道,公司生产的引擎是否符合政府规定呢?如果你是这家公司的数据分析师,该怎么办呢?
1.描述统计分析
当我们开展调查研究并计算统计结果时,我们会在报告的第一部分进行描述统计分析,例如平均值和标准差。描述统计量是研究的核心。告诉我们研究中发生的情况,应该始终报告出来。
下面图片我们看下这10台引擎的描述统计分析。

上面图片代码的解释如下:
第一步,我们导入常用的包数据分析包导入
第二步,我们将样本数据存放到pandas的一维数组中
第三步,使用mean方法得到样本平均值是17.17
使用std方法得到样本的标准差是2.98
这里要注意的是pandas计算的标准差公式中,默认除以的是n-1,也就是计算出的是样本标准差,用途是用样本标准差估计出总体标准差。
2.推论统计分析
推论统计分析报告中包括假设检验。
假设检验第1步:问题是什么?
第一步,我们要明确问题是什么:公司引擎排放是否满足新标准。
根据这个问题我提出来下面两个互为相反的假设。
零假设:公司引擎排放不满足标准,也就是平均值>=20。这里的20是政府规定新标准的最低可能值。
零假设总是表述为研究没有改变,没有效果,不起作用等,这里就是不满足标准。
备选假设:满足标准,也就是平均值<20
现在零假设和备选假设帮助我们理清楚了问题是什么。

假设检验根据检验类型的不同,后面计算的方法也不同。常见的假设检验有下面图片中的3种类型。

1)单样本检验
检验单个样本的平均值是否等于目标值,例如某大学的学生平均身高是否大于全国平均身高167.1cm?
这里的某大学的学生身高就是单个样本,目标值就是全国平均身高。还有我们的汽车引擎例子,公司的汽车引擎排放单个样本,目标值就是政府的新标准。
所以汽车引擎的检验类型是单样本检验。
这是单个样本的检验。当有多个样本时,样本又分为独立样本和相关样本。所以对应的又分为独立样本检验和相关样本检验。
2)相关样本配对检验
例如,为了检测减肥药是否起作用,随机抽样出20名测试对象,记录每个人服药前和服药后的体重。
这里服药前的体重是第一个样本数据,服药后的体重是第二个样本数据。但是这两组数据来自同一批测试对象。所以是相关样本。
为什么使用相关样本呢?
相关样本可以控制个体差异。也就是说,如果给某人带来某种处理措施。下次再对同样的人实施同一处理措施,这个人还会出现相同的差异。这样我们判断在同一条件下,两种不同处理措施的效果,因为我们控制了个体差异。然后就可以使用更少的受试者,成本更低,花费更少,通常开支也更少。
相关样本的缺点:就是有残留效应。例如我发明了一种新的闯关游戏教学方法,我想知道该方法对提高学习成绩是否有效。
如果使用同一组学生来检验这一新的教学方法。第一节课用一种方式教他们数据分析,第二节课再用另一种方式教他们数据分析。
因为学生已经在第一节课学过数据分析的相关知识,那我们就不知道第二节课的结果是因为教学方式有效,还是学生已经学过相关的数据分析知识。
也就是说,第二次的测量结果会受到第一次处理措施的影响。
这时候就可以用两个独立样本。
3)独立双样本检验
独立样本的优点是没有残留效应,弥补了相关样本的不足。因此,我们可以对一个组实施一种处理措施,并对另一组实施另一种处理措施。
独立样本的缺点是:
对于独立样本,我们需要更多的实验数据,因为我们需要随机地选择两组实验数据来接受两种处理措施。我们需要更大的样本大小来尽量控制个体差异。意味着更加耗时间,通常开支也更多。
所以独立样本和相关样本的优点和缺点是互补的。配对检验和双样本检验的方法我们会在后面课程中通过具体案例来讲解。
我们先来看单样本检验的案例:汽车引擎。
分布类型
我们需要知道数据集的分布是哪种类型。

分布是指数据在统计图中的形状。将多个样本平均值的分布可视化,叫做抽样分布。在抽样分布中,我们还要判断抽样分布是哪种?因为抽样分布的类型,决定了后面计算p值的不同。
我们在之前的课程《抽样分布》中有讲过。当样本大小大于30时,符合中心极限定律,所以样本平均值值分布是正态分布。当抽样分布是正态分布时,横轴是样本平均值从小到大。中间位置是总体平均值。
但是,如果样本容量n小于30,同时总体分布近似正态分布时,抽样分布符合t分布。t分布和正态分布很像,随着样本大小n变大,t分布趋近于正态分布。
小样本数据集没有近似正态分布时,抽样分布符合其他分布。其他分布的类型我们会在其他课程中用到的时候讲到。
现在我们只需要关注抽样分布是正态分布,和t分布时需要满足那些前提条件就可以。
在我们这个汽车引擎案例中,样本大小是10(小于30),属于小样本。那小样本的抽样分布是否满足t分布呢?因为t分布还要求总体近似正态分布,
由于我们没有办法知道总体的分布,只能通过样本数据集的分布来看是否近似正态分布。
所以我们现在的问题是要用某种技术手段看下样本数据集的分布长什么样。
在学技术的过程中,我们经常会遇到很多新的问题。但恰好这个世界上有个神器叫做搜索引擎,任何问题只要在搜索引擎中搜一下,答案自然就出来了。
其实,技术能力的差异本质上是学习能力的差异,会主动利用搜索引擎解决问题的人的成长就是比那些伸手党成长的快,这也是造成虽然学的是同一门技术,但是工作几年看看,不同的人薪水差别是很大的。
借助我们这个如何查看数据集的问题,我们学习下如何使用搜索引擎找到答案。在搜索引擎中输入你找问题的关键词,我们就可以看到下面图片中的搜索结果。
在搜索引擎结果页面第一个网址里面就是解决方案。
查看数据集的分布,我们这里使用了python高级绘图包Seaborn的distplot方法。这个方法可以直接得到数据集的直方图和拟合曲线。
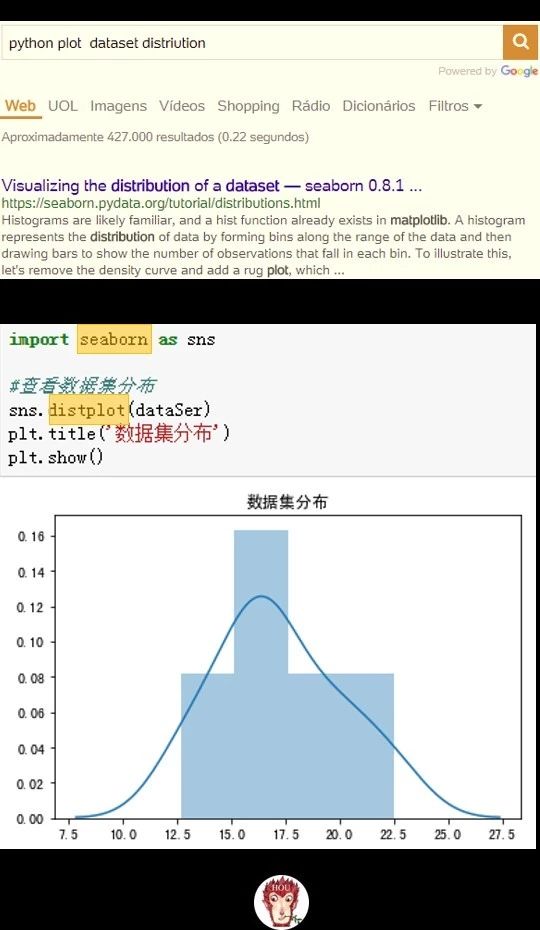
通过观察上面数据集分布图,数据集近似正态分布,满足t分布的使用条件,所以抽样分布是t分布,自由度df=n-1=10-1=9。
检验方向
在确定检验类型中时,还需要明白一件事:所构建的是单尾检验还是双尾检验(two tailed)。
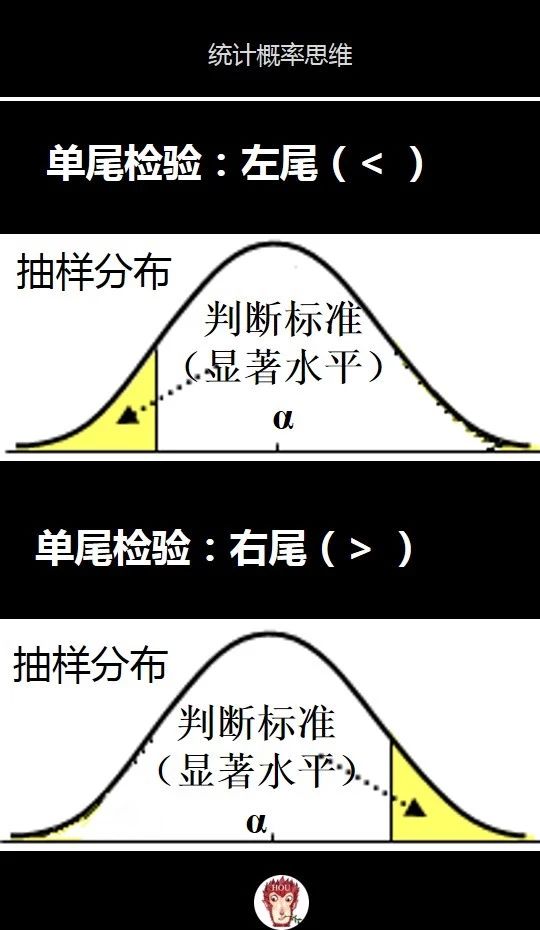
1)单尾检验
检验的判断标准落在抽样分布的哪一侧,决定了是左尾检验还是右尾检验。具体用哪一侧则取决于备选假设。
如果备选假设包含一个<符号,则使用左尾,判断标准对应在抽样分布中的左边黄色区域。
如果备选假设包含一个>符号,则使用右尾,判断标准对应在抽样分布中的右边黄色区域。
例如我们这个汽车引擎案例里的备选假设是公司引擎排放满足标准,也就是平均值u<20,备选假设里面包含一个小于符合,所以属于左尾检验。
下面图片我们再看下双尾检验
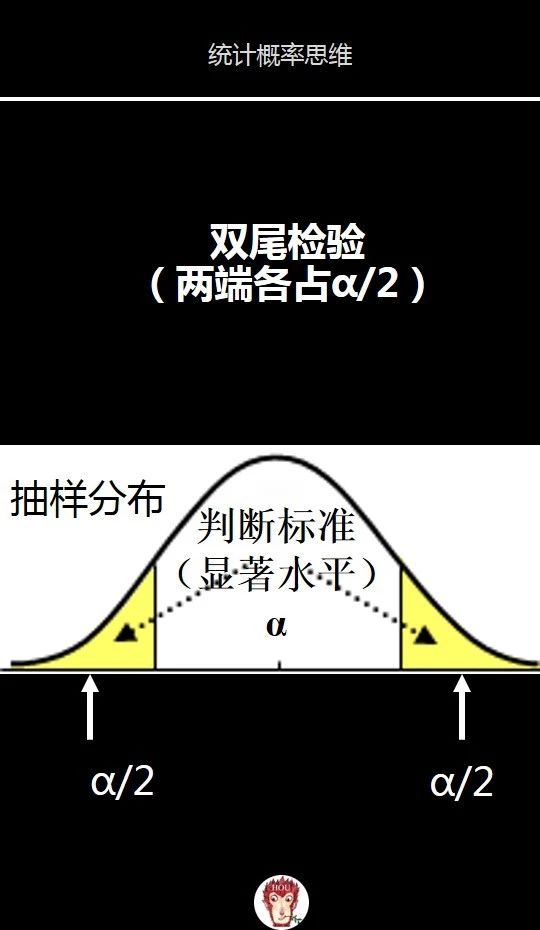
双尾检验是将判断标准一分为二位于抽样分布的两侧,根据图中黄色区域对称性,左侧和右侧各占一半的判断标准,也就是α/2
判断是否需要使用双尾检验的方法是:查看备选假设。
如果备选假设包含一个不等号,则需要使用双尾检验,这是因为你要找出参数的变化,而不是增减。
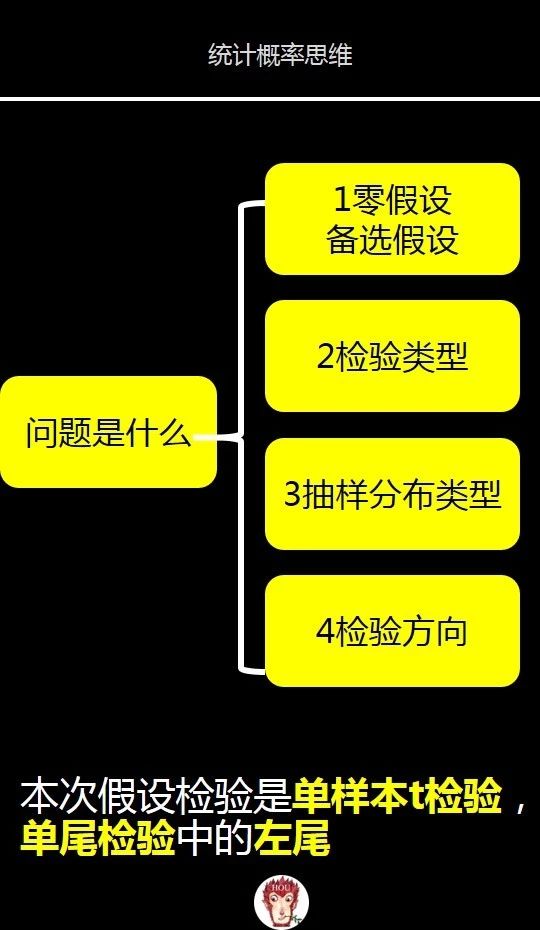
总结:问题是什么?
在假设第一步问题是什么,我们做了4件事情来明确问题。
第1件事情是提出零假设和备选假设。
零假设H0:公司引擎排放不满足标准,也就是平均值u>=20。这里的20是政府规定新标准的最低可能值。
备选假设H1:公司引擎排放满足标准,也就是平均值u<20
第2件事情是确定检验类型。
因为我们的汽车引擎案例里里只有1个样本,所以选择单样本检验。
第3件事情是抽样分布类型。
在我们这个汽车引擎案例中,抽样分布是t分布。
第4件事情检验方向
因为备选假设是公司引擎排放满足标准,也就是平均值u<20,所以我们使用单尾检验中的左尾检验
综合以上分析,本次假设检验是单样本t检验,单尾检验中的左尾。
假设检验第2步:证据是什么?
有人说:统计学就是个p。此p可不像彼屁,可以一放了之。
作为假设检验的核心工具,它经常决定着一个发现的价值,一篇论文的成败。
你一定忘不了做课题时为p欢喜为p忧的经历:得到p小于5%时欣喜若狂,得到p大于5%时灰心伤气。
但是,你真的懂p值吗?它到底是什么?
随便翻开一本统计学课本,我们会看到这样的定义:
p值是在假定原假设为真时,得到与样本同样或者更极端结果的概率。
你的反应多半会是:说人话。
在假设检验的第2步证据是什么,就是要计算p值。用更直白的话来说,p值就是,在零假设成立前提下,得到样本平均值的概率是多少?

当抽样分布是t分布时,计算p值步骤也很简单:
1)计算出标准误差
标准误差=样本标准差除以样本大小n的开方。这里的样本标准差是用来估计总体标准差的。
2)计算t值
t=(样本平均值-总体平均值)/标准误差
t值表示在抽样分布是t分布中,样本平均值距离总体平均值多少个标准误差3)
根据t值,查找t表格,就得到概率p值

不要为这几个公式烦恼,你只需要理解p值是怎么来的就可以,关于计算有很方便的工具一秒就能算出来。
下面我们用python快速计算出p值。
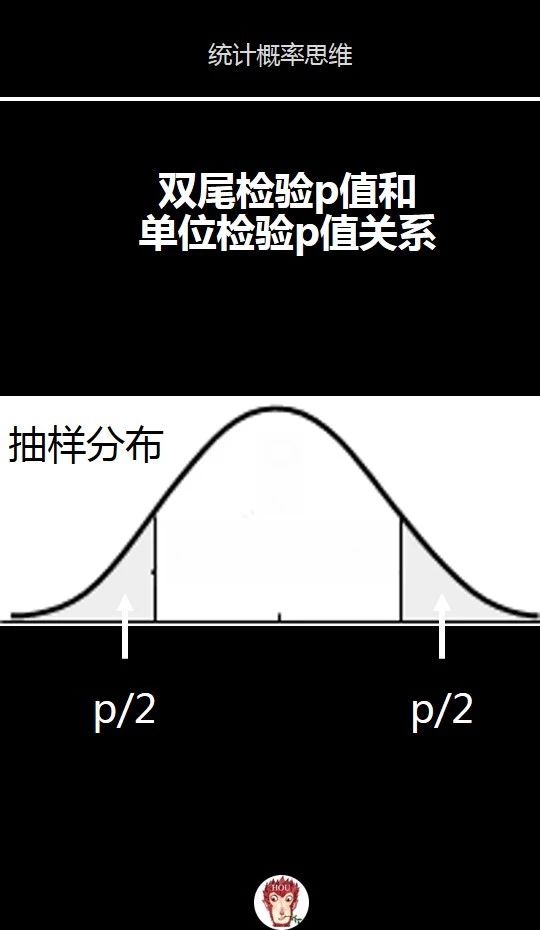
对于连续分布,概率是图中的面积。双尾检验的P值是上面图片中抽样分布中的灰色区域的面积。当抽样分布是t分布时,根据t分布的对称性,左尾和右尾,也就是图中两块灰色区域的面积相等各占p的一半,也就是p/2。
所以当我们求出双尾检验的p值后,自然可以得到左尾和右尾的p值是双尾检验p值的一半。
这也是很多计算p值的工具不提供单尾检验的p值,只提供双尾检验的p值。因为只要得到双尾检验的p值,单位检验的p值也就得到了,那就是双尾检验p值的一半。
前面我们已经计算出双尾检验的p值,除以2,就是单位检验的p值。
下面图片我们利用python的统计包可以自动算出t值和p值。
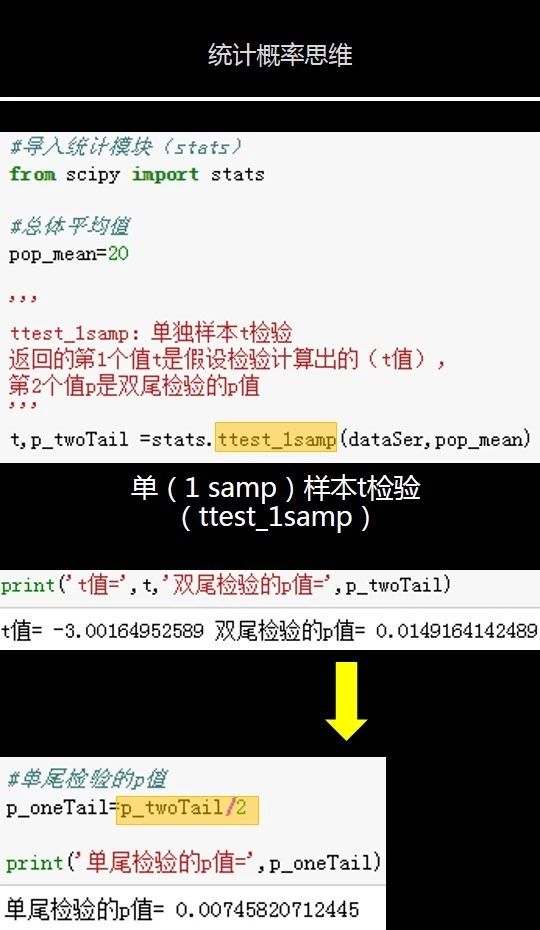
上图片代码的解释:
不同的检验方法在python的统计模块scipy中都有对应的方法。
单样本t检验对应的方法是ttest_1samp,从名字中我们也可以看出1samp是指单样本,ttest是指t检验。
我们给这个方法传入样本数据,和总体平均值。这个方法返回2个值,第1个值t是假设检验计算出的t值,第2个值p是双尾检验的p值。和我们刚才手动计算出的结果是一样的。但是这个方法更简单。
因为我们这个案例里的检验是左尾检验,所以用双尾检验的p值除以2,就可以得到单尾检验的p值,是0.0074。
这个p值表示什么意思呢?
P值表示在零假设成立的前提下,得到样本平均值的概率是多少。
在这个案例里就是假设汽车引擎满足排放标准20ppm,得到样本平均值的概率是0.0074。
单样本检验第3步:判断标准是什么?
需要建立判断标准来检验证据是否有效。在这个案例里我们给定判断标准,也就是显著水平 a=5%
这里我们是左尾检验,所以对应上面图片中的黄色区域面积。

假设检验第4步:做出结论
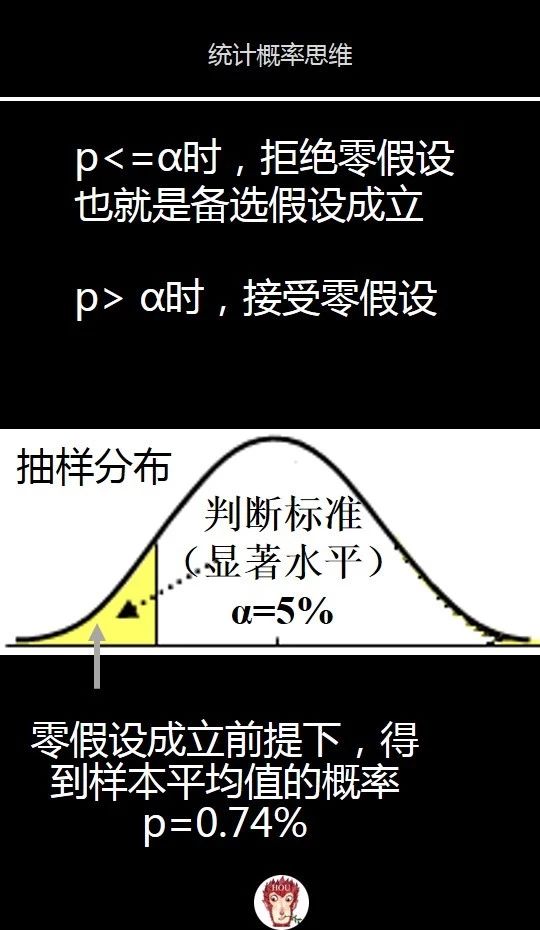
现在我们找到了证据也就是p’值,并有了判案用的标准也就是判断标准alpha。
现在我们要利用证据和判断标准做出结论,我们将样本证据计算出的p值与判断标准α比较下就可以了:
如果p< =α,那么零假设不成立,对应的就是备选假设成立。
也就是如果得到样本平均值的概率p值小于判断标准(5%),那么通常被视为不太可能发生,因为在零假设成立前提下,证据显示出的概率太小了,我们只能推翻零假设。所以当p<=显著水平α时,拒绝零假设。
对应的就是上面图片中p的面积区域小于黄色的判断标准区域。
简单来说,整个决策过程,是依据证据显示出的概率大小来判断的。
下面图片我们看下如何用python做出结论的代码。
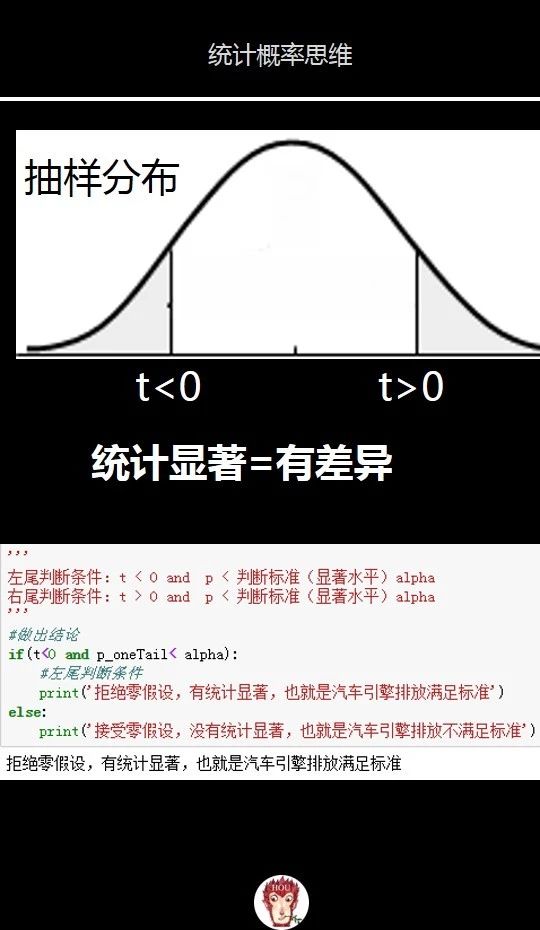
因为我们这里是左尾检验,所以在做出结论时,还要判断t值是否大于0。
如果t值小于0,表示计算出的t值是在抽样分布的左侧,也就是左尾。如果t值大于0,表示是在抽样分布的右侧,也就是右尾。
当我们拒绝零假设了,在统计上叫做统计显著(statistical significance)。
记住的是,统计显著不等于效果显著。统计显著只能说明两个总体之间或者两个不同版本之间有差异。但这个差异到底多大,我们还要看另一个指标,会在下次聊到,包括我们后面聊聊《如何做推论统计分析报告》。
你也可以在我的知乎live中找到全部课程《数据分析必懂的假设检验》。

推荐:他是如何用批判性思维改变命运的

