作者:Tirthajyoti Sarkar
来源:codementor
参与:Cynthia、大伟、周剑
翻译:本文为天善智能编译,未经容许,禁止转载
利用Python库,管道特性以及正则化建立简单且强效的非线性数据模型。
非线性数据模型是数据科学及分析领域的一项日常作业。在自然过程中,鲜少出现不同变量下的线性结果。因此,我们需要一个简单而强效的研究方法来将数据组与一系列的变量快速匹配,并假设数据组为复杂的非线性功能。这必将成为数据科学家与机器学习工程师的常用工具。
以下是几个需要思考的相关问题:
·我应该如何决定尝试使用的多项式的顺序? 我是否需要包含用于多变量回归的交叉耦合项?是否有可以将过程自动化的简单方法?
·我如何确保不会过度拟合数据?
·我的机器学习模型是否强大到足以对抗测量中的噪点?
·我的模型是否能够轻松地扩展到更高维且更庞大的数据集中?
如何决定多项式次序及相关的困境
“我能绘制数据图并快速浏览吗?”
只有数据清晰可见(其特征降维为一维或二维)的时候你才能这么做。当特征降维达到三维或以上时,事情就变得困难许多。而且当交叉耦合项影响到结果的时候,这么做将是纯粹的浪费时间。以平面图为例,在高维度交互式数据集面前,如果你试图一次将一个输入变量对应所有结果,你的结论将会大错特错。而且,也没有同时将两个以上的变量可视化的捷径。所以,我们必须将某种机器学习技术作为多维数据集的过滤手段。
实际上,能够完美解决问题的方法有许多:
线性回归应该是首当其冲的工具。在你尖叫:“可它们是高度非线性数据集……”之前,让我们不要忘了线性回归中的“线性”指的是回归系数,而不是特征的级数。特征(或者说独立变量)可以是任何级数甚至是超越函数,比如指数函数、对数函数、正弦函数。而且出乎意料的,许多自然现象都可以建成(粗略的)线性模型。
所以,比方说,当我们得到一组有单一输出和三个特征的数据集的时候,图表就无法派上用场。
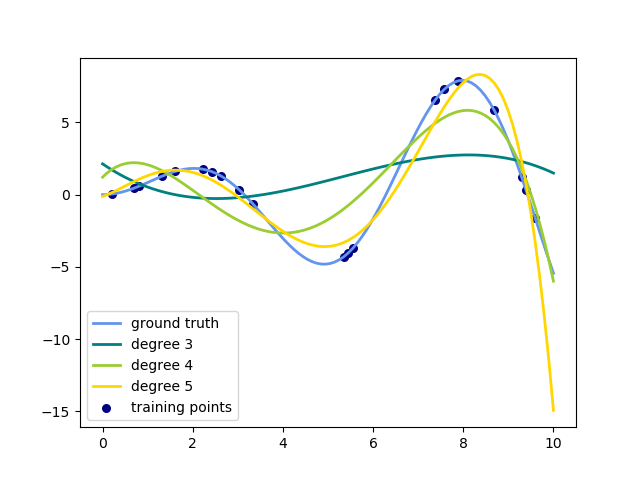
因此我们决定用一个带高维度多项式的线性模型来匹配数据集。问题马上又出现了:
·如何决定多项式的必要性?
·当我们依次尝试一维、二维、三维...... 的时候应该在哪里停止?
·当我们只需要_X_1², _X_2³ 或者 _X_1._X_2 和 _X_1².X3的时候,怎么判定哪些交叉耦合项是重要的?
·最后,难道我们必须得把所有的公式手动输入数据集吗?
Python 机器学习库——酷炫的好帮手
幸运的是,scikit-learn,一个酷炫的机器学习库,为上面的所有问题提供了许多现成的解决方案,而且简单又稳定。
我们从用scikit-learn输入一些关联的类开始:
# Import function to create training and test set splits
from sklearn.cross_validation import train_test_split
# Import function to automatically create polynomial features!
from sklearn.preprocessing import PolynomialFeatures
# Import Linear Regression and a regularized regression function
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LassoCV
# Finally, import function to make a machine learning pipeline
from sklearn.pipeline import make_pipeline
让我们快速地解说一下其中的概念:
Train/Test split:这意味着从我们现有的一个数据集创建出两个数据集来。其中之一(Training set)将被用来测试模型的准确性和坚固性。对于任何机器学习目标这都是必要的,以防止我们创造出一个我们认为高度精确的模型(因为它已经‘看透了’我们的全部数据且能完美契合),但在处理现实世界中的“新数据”时表现糟糕。而Test set的准确性比 Training set的准确性更加重要。
Automatic polynomial feature generation:Scikit-learn 提供了一个从一系列线性特征中简洁地整理出多项式特征的方法。你所要做的只有将线性特征归入一个列表并设定你想要的最大维度。它还能让你选择调整所有的交叉耦合项,或是单独调试多项式维度。
Regularized regression:规范化的重要性并不能被过分定义为整个机器学习的核心。在线性回归环境中,基本的要点是通过惩罚模式系数来防止它们过拟合数据,如:使模型对数据中的噪点过于敏感。常用的规范方式有两种,而我们使用的那一种叫作LASSO。
Machine learning pipeline:机器学习项目(几乎)从来不是单模型的。最常用的形式也包含了数据生成/输入、数据清理和转换、模型拟合、交叉验证、模型精度测试和最终部署。Scikit-learn提供了一个能够将复数的模型和数据预处理类打包的管道特征,将你的所有原始数据变为有用的模型。
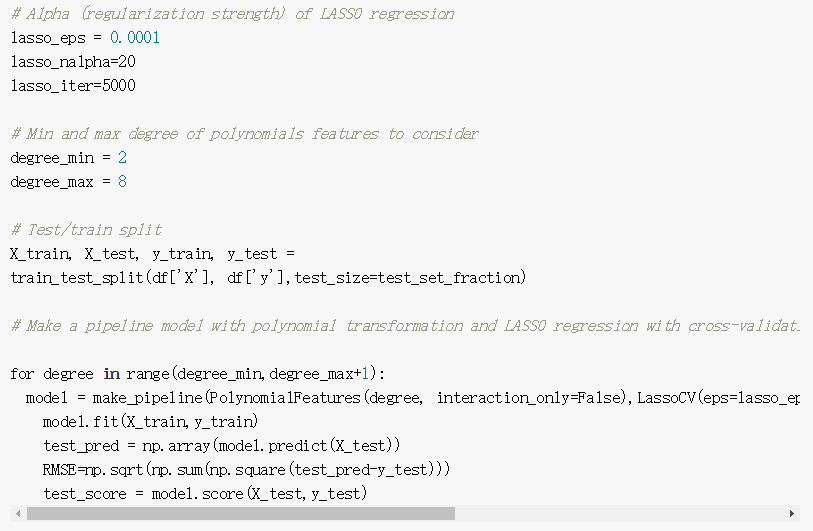
图片:一个锅炉钢板的代码快照
总结:
简而言之,我们讨论了将多元回归模型适用于具有高度非线性和相互耦合的条件的数据集的一种方法,且将噪点的存在纳入考虑。我们也看到了如何利用Python机器学习库来生成多项式特征,使数据归一化,拟合模型,使系数不太大,从而维持偏见方差的权衡,并绘制回归分数,判断模型的准确性和鲁棒性。
文章来源:
https://www.codementor.io/tirthajyotisarkar/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-hfgyw7i4f?from=singlemessage

