作者介绍:宋天龙(TonySong),资深大数据技术专家,历任软通动力集团大数据研究院数据总监、Webtrekk(德国最大的网站数据分析服务提供商)中国区技术和咨询负责人、国美在线大数据中心经理。
本文来自《Python数据分析与数据化运营》配套书籍第5章节内容,机械工业出版社华章授权发布,未经允许,禁止转载!
此书包含 50个数据工作流知识点,14个数据分析和挖掘主题,8个综合性运营案例。涵盖了会员、商品、流量、内容4大数据化运营主题,360°把脉运营问题并贴合数据场景落地。
书籍购买链接:https://item.jd.com/12254905.html
课程学习链接:网站数据分析场景和方法——效果预测、结论定义、数据探究和业务执行https://edu.hellobi.com/course/221
往期回顾:Python数据分析与数据化运营:会员数据化运营1-概述与关键指标
Python数据分析与数据化运营:会员数据化运营2-应用场景与分析模型
在做会员数据化运营分析时,有一些小技巧和小方法,将在本节中简单介绍。
5.5.1 使用留存分析分析新用户质量
用户留存指的是新会员/用户在经过一定时间之后,仍然具有访问、登录、使用或转化等特定属性和行为,留存用户占当时新用户的比例就是留存率。留存率按照不同的周期分为三类,以登录行为认定的留存为例:
第一种 日留存,日留存又可以细分为以下几种:
- 次日留存率:(当天新增的用户中,第2天还登录的用户数)/第一天新增总用户数
- 第3日留存率:(第一天新增用户中,第3天还有登录的用户数)/第一天新增总用户数
- 第7日留存率:(第一天新增用户中,第7天还有登录的用户数)/第一天新增总用户数
- 第14日留存率:(第一天新增用户中,第14天还有登录的用户数)/第一天新增总用户数
- 第30日留存率:(第一天新增用户中,第30天还有登录的用户数)/第一天新增总用户数
第二种 周留存,以周度为单位的留存率,指的是每个周相对于第一个周的新增用户中,仍然还有登录的用户数。
第三种 月留存,以月度为单位的留存率,指的是每个月相对于第一个周的新增用户中,仍然还有登录的用户数。
留存率是针对新用户的,其结果是一个矩阵式半面报告(只有一半有数据),每个数据记录行是日期、列为对应的不同时间周期下的留存率。正常情况下,留存率会随着时间周期的推移而逐渐降低,例如图5-1
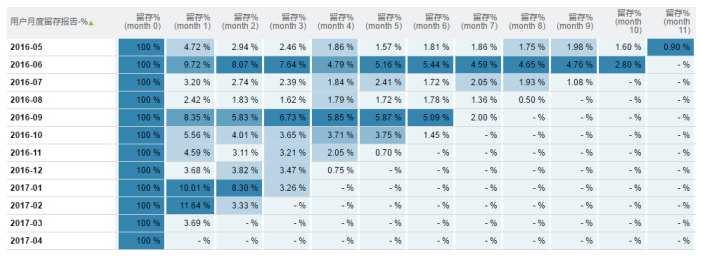
图5-1月度留存报告
在应用留存分析时,需要注意以下几个问题:
- 区别应用不同留存周期。日留存用来做短期结果、周留存用来看中期效果、月留存用来看长期效果。
- 在留存中注意观察和分析衰减比率,正常情况下的留存会随着时间逐渐衰减,这种衰减趋势可能呈线性、指数性甚至二项式等不同趋势,通过衰减数据可以得到衰减模型,这些模型可以用来做衰减异常检测,用来发现哪些时间的衰减存在异常(通常是过渡衰减)。
- 注意分析运营活动对于留存的影响,在没有较大的运营活动时,留存的衰减会存在一定规律;但当运营采取一定活动时可能会导致留存率的提升,而这种提升应该是预期内的。如果留存中没有反映出提升趋势,需要多方面总结运营活动效果。
5.5.2 使用AARRR做APP用户生命周期分析
AARRR是Acquisition、Activation、Retention、Revenue、Refer五个单词的缩写,分别对应用户生命周期中的5个环节:获取用户、提高活跃度、提高留存率、获取收入、自传播。
获取用户:获取用户是第一步,解决的是从哪里能带来更多的用户和会员。该部分的数据评估维度一般包括两个层次:用户数量和用户质量。
- 用户数量:用户数量是获得用户的数量,关于用户数量的统计有多种维度和方法。例如以设备唯一ID作为唯一用户标识;以匿名Cookid作为唯一用户识别标志;以用户实名ID作为唯一用户标志,例如会员ID、电子邮件、手机号等。
- 用户质量:用户质量的评估会涉及到多个方面,例如访问频率、启动次数、浏览深度、停留时间、目标转化率、付费转化率、收入等单维度指标以及活跃度、价值度等复合模型指标。
提高活跃度:提升活跃度是将用户引入后持续关注的问题。分析活跃的数据评估维度包括每日/每周/每月活跃用户数三种,关于该部分内容请见“5.2.3 会员活跃度指标”。在做活跃度对比时,除了企业内部基于不同时间的对比,还需要横向跟行业内的其他企业做标杆对比,这样才能了解企业活跃度在行业内的水平。
提高留存率:提升留存率意味着会有更多的客户沉淀下来。有关留存率的具体问题,请见“5.5.1 使用留存分析分析新客户质量”。
获取收入:获取收入是运营的根据目标。有关收入的数据支撑,一般会通过以下几个指标来做分析:
- 付费用户数/比例:产生收入的用户数及其占整体的比例
- ARPU:平均每用户收入,衡量每个用户的付费能力
- 新增付费用户:新产生的付费用户数
- 付费转化周期:用户从免费到付费的转化时间,时间越短越好
- 重复消费比例:具有2次及以上消费的用户比例
- 消费金额在特定金额以上的客户:通常用来分析VIP客户或大客户,例如消费金额在10000以上
- 消费分级:根据不同的消费数据做消费分级,用来整体划分会员群体
自传播:如果用户使用产品时体验良好,那么可能会产生传播效应,把产品推荐给其他朋友、亲戚等使用。自传播主要分为两个方面:
- 产品引导传播:这种一般是在产品内部有推送信息提示用户做产品传播,可能同步需要配合不同的激励措施以达到推动传播的效果。
- 用户主动传播:用户自发的将相关产品应用截图、数据、产品等分项到社交圈。
对这两种传播都需要在产品应用内部为不同的用户和传播场景做标记,以便于下一步分析,常用标记数据包括:分享内容、主动传播/被动传播、激励措施等。
上述所有的数据采集一般通过三种方式配合实现:
- APP行为检测:对于APP产品应用内部的用户行为,通过埋点的方式将不同用户行为记录下来。
- APP交易检测:一般的APP内部也可以做交易检测,但更多(以及更准确)的还是通过企业内部的销售系统做数据收集。
- APP外部检测:主要用来检测用户在APP之外的信息,例如分享、评论、转发等。
5.5.3 借助动态数据流关注会员状态的轮转
在做会员状态分析时,通常得到的是某个时间点状态。但是在不同时间周期下,会员的状态会发生改变。基于动态的时间周期,可以有效分析用户的状态轮转变化,可以从整个周期的视角发现会员状态的全貌。
例如,通过价值度模型定义好不同的价值度群体标准,然后每个客户都有一个价值度标签,基于一个时间节点开始,向后可以分析所有用户在不同时间周期下的价值度的变迁和轮转情况,效果如图5-2的桑基图所示:
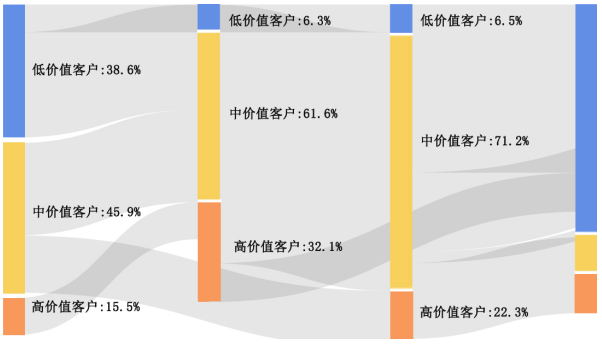
图5-2用户活跃度状态轮转
在上述桑基图中,可以看到不同价值度之下用户的状态变化,同时可以结合动态时间轴做特定时间周期的分析。这种分析相对于柱形图或趋势图的数据统计,可以明显看到不同状态的用户轮转变换的比例和大小,而不仅是一个结果值,这种中间的转换状态才是动态分析的重点。
5.5.4 使用协同过滤算法为新会员分析推送个性化信息
在针对新会员的运营过程中,由于新会员的数据量少,因此无法根据其历史数据针对性的提供个性化、精准化的运营活动。此时,除了可以采用TOP榜(例如TOP浏览商品、TOP销售商品等)的固定推送机制外,还可以基于相似会员的喜好来做推荐。
基于相似会员的信息挖掘有很多种方法,在此介绍基于用户的协同过滤算法。协同过滤(Collaborative Filtering,CF))是利用集体智慧的一个典型方法,常被用于分辨特定对象(通常是人)可能感兴趣的项目(项目可能是商品、资讯、书籍、音乐、帖子等),这些感兴趣的内容来源于其他类似人群的兴趣和爱好,然后被作为推荐内容推荐给特定对象。基于用户的协同过滤是利用的人群的相似度为基础做推荐。
协同过滤主要解决的问题是当客户进入某个领域后,什么内容或项目是他/她可能感兴趣的东西,然后以用户的兴趣为出发点推荐他/她可能感兴趣的内容,以此来提高用户体验、用户交互频率提升、订单转化效果、销售利润提升等。
协同过滤目前主要用于电子商务网站、兴趣部落网站、知识性网站、话题型网站、社交性网站的个性化项目推荐。协同过滤推荐的场景通常发生在,当客户对内容进行打分的前提下,例如内容评分、综合评价等。
举例:图5-3是基于用户的协同过滤机制。假设用户 A 喜欢物品 A、C,用户 B 喜欢物品 B,用户 C 喜欢物品 A 、C、 D;从用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似,因此可以物品D推荐给用户A。
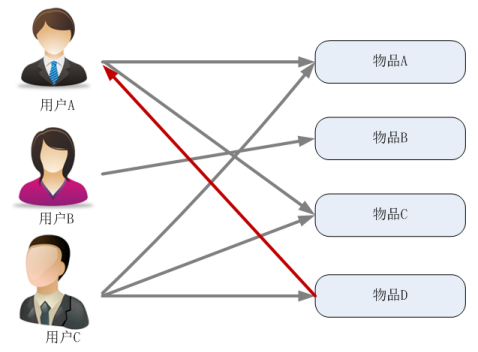
图5-3基于用户的协同过滤算法
使用基于用户的协同过滤算法时,主要步骤如下:
步骤1 收集用户数据。一般情况下对会员数据的采集包括属性、行为等多个方面,例如性别、年龄、地域、订单量、购买商品、广告渠道来源、订单金额等。
步骤2 会员相似度计算。以新会员为目标对象,计算其他所有会员跟新会员的相似度并获得相似度得分。关于相似度的算法有很多种,例如:
- 基于几何距离的“相似度”算法:欧式距离、曼哈顿距离、切比雪夫距离等
- 基于非几何距离的“相似度”算法:余弦距离、汉明距离、杰卡德相似系数、相关系数等
步骤3 将其他所有会员跟目标新会员的相似性得分按倒序排序,得分最高者为最相似的会员。但是实际情况是我们会选择有K个最相似的用户,使用类似于K近邻的方法。例如,选择最相似的5个会员。
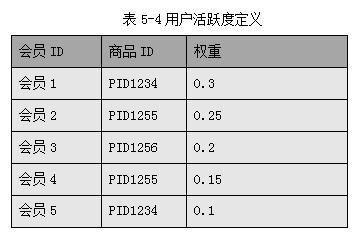
步骤4 选择最相似K个会员的目标推荐信息。在选择目标信息的过程中,对于不同会员的信息统计有多种方法,例如普通计数、加权汇总等,一般使用加权汇总的方式。例如选择最相似的5个会员最经常浏览的商品(假设是针对商品浏览做推荐),他们各自最经常浏览的商品列表如下:
- 会员1:PID1234
- 会员2:PID1255
- 会员3:PID1256
- 会员4:PID1255
- 会员5:PID1234
同时,我们会有一个针对不同相似度会员的权重表,用来将相似度排名和会员的数量结合起来,形成如表5-4数据:
基于表5-4结果对商品ID做汇总统计,得到如下结果;
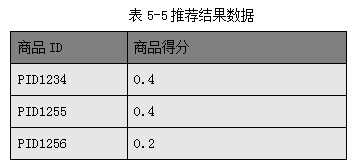
基于上述结果,可为该新会员推荐商品ID为PID1234或PID1255商品。
提示:协同过滤属于个性化推荐算法的一种,并不是个性化推荐的全部,除了协同过滤算法外,还有多种算法可以在不同场景下满足不同的推荐需求,例如关联算法、KNN、TOPN、深度学习等算法。另外,推荐算法也只是推荐系统中的一部分,除了推荐算法模块外,还可能包括实时数据接入和流处理、DMP数据管理、用户行为建模和画像标签库、项目标签库、冷启动场景规则、异常场景规则、强制人工干预规则、模型和数据修正模块、场景引擎模块、投放引擎模块、机器学习算法库和挖掘模块、推荐规则模块、推荐效果分析模块等。
