4. 查看对象的类型
对于未知类型的对象,在R中有3个函数可以查看对象的类型:class()、mode()、typeof()。
df <- data.frame(cl=letters[1:3],c2=1:3,c3=c(1,-1,3),stringsAsFactors = F)
sapply(df,mode)
sapply(df,class)
sapply(df,typeof)

5. 向量创建及向量化操作详解
(1)向量
• 向量是以一维数组的方法管理数据的一种对象类型。可以说向量是R语言中最基本的数据类型,很多算法函数都是以向量的形式输入的。
• 向量可以是字符型、逻辑值型(T、F)、数值型和复数型。
• 一个对象的长度是它含有元素的数量,可以用length( )函数来获取
w<-c(1,3,4,5,6,7)
length(w)
mode(w)
w1<-c("张三","李四","王五")
length(w1)
mode(w1)
w2<-c(T,F,T)
length(w2)
mode(w2)

• 在大多数情况下,使用长度大于1的向量。可以在R中使用c( )函数和相应的参数来创建一个向量
w4<-c(w,w1)
w4
mode(w4)
w5<-c(w1,w2)
w5
mode(w5)
w6 <- c(w,w2)
mode(w6)

• 一个向量的所有元素都必须属亍相同的模式。如果不是,R将强制执行类型转换。
(2)向量化
• R语言最强大的方面之一就是函数的向量化。这些函数可以直接对向量的每个元素进行操作。
rm(list=ls())
(w<-seq(1:10))
(x<-sqrt(w))
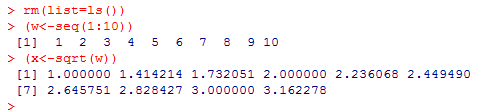
• 也可以利用R的这个特性进行向量的算术运算。
rm(list=ls())
(w1<-c(2,3,4))
(w2<-c(3.1,4.2,5.3))
(w<-w1+w2)

• 如果两个向量的长度不同,R将利用循环规则,该规则重复较短的向量元素,直到得到的向量长度不较长的向量的长度相同。
rm(list=ls())
(w1<-c(2,4,6,8))
(w2<-c(10,12))
(w<-w1+w2)
rm(list=ls())
(w1<-c(2,4,6,8))
(w2<-c(10,12,14))
(w<-w1+w2)

6. 常用序列创建及索引向量介绍
(1)等差序列的创建
seq( )产生等距间隔的数列,其基本形式为:
seq(from = 1, to = 1, by = ((to - from)/(length.out - 1)),
length.out = NULL, along.with = NULL, ...)

seq(1,-9)
seq(1,-9,length.out=5)
seq(1,-9,by=-2)
seq(1,by=2,length.out=10)

(2)重复序列的创建
rep( )是重复函数,它可以将某一向量重复若干次。其基本形式是rep(x,times,…)。其中x是预重复的序列,可以是任意的数据类型的向量或数值,times是重复的次数。例如:
rep(1:4,2)
rep(1:4,each=2)
rep(1:4, c(2,2,2,2))
rep(1:4, c(2,1,2,1))
rep(1:4, each = 2, len = 4)
rep(1:4, each = 2, len = 10)
rep(1:4, each = 2, times = 3)
rep(as.factor(c("银子1","银子2","银子3")),3)

(3)索引向量
通常,我们只要访问向量中的部分或个别元素。这就是所谓的索引,它用方括号[ ]来实现。(有人也称之为子集、下标或切片,这些术语所指相同。)R 系统非常灵活,提供如下多种索引方法:
• 给向量传入正数,它会返回此位置上的向量元素切片。它的第一个位置是 1( 而不像其他某些语言一样是0) 。
• 给向量传入负数,它会返回一个向量切片,它将包含除了这些位置以外的所有元素。
• 给向量传入一个逻辑向量,它会返回一个向量切片,里面只包含索引为 TRUE 的元素。
• 对于已命名的向量,给向量传入命名的字符向量,将会返回向量中包含这些名字的元素切片。
以下三个索引方法都将返回相同的值:
x <- rnorm(5)
x[c(1,3,5)]
x[c(-2,-4)]
x[c(TRUE,FALSE,TRUE,FALSE,TRUE)]
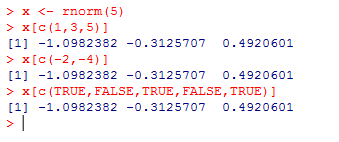
如果给每个元素命名,以下方法也将返回相同的值:
names(x) <- c("one", "two", "three", "four", "five")
x[c('one','three','five')]

混合使用正负值是丌允许的,会抛出一个错误:
x[c(1,-1)]


