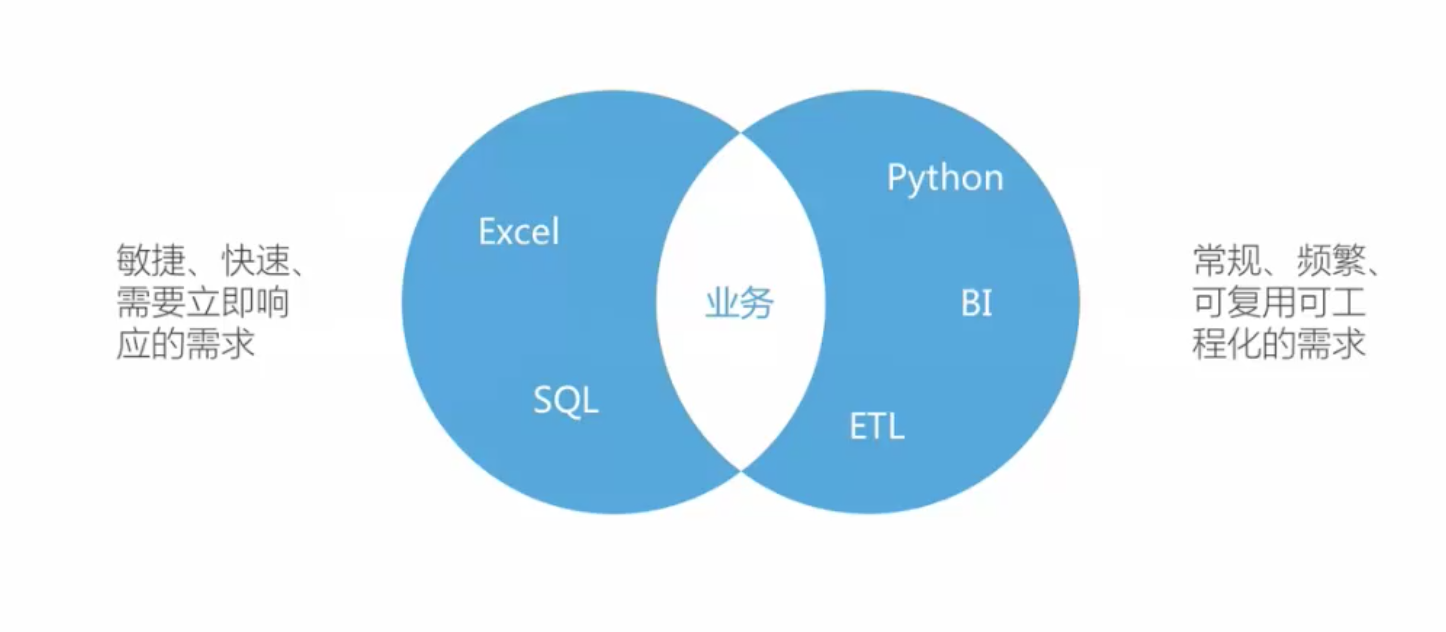
理解Excel的重要性(应用场景)
excel学习路径
excel的必知必会
- 保证新版本
- 培养好的数据表格习惯
- 主动性搜索
- 多联系
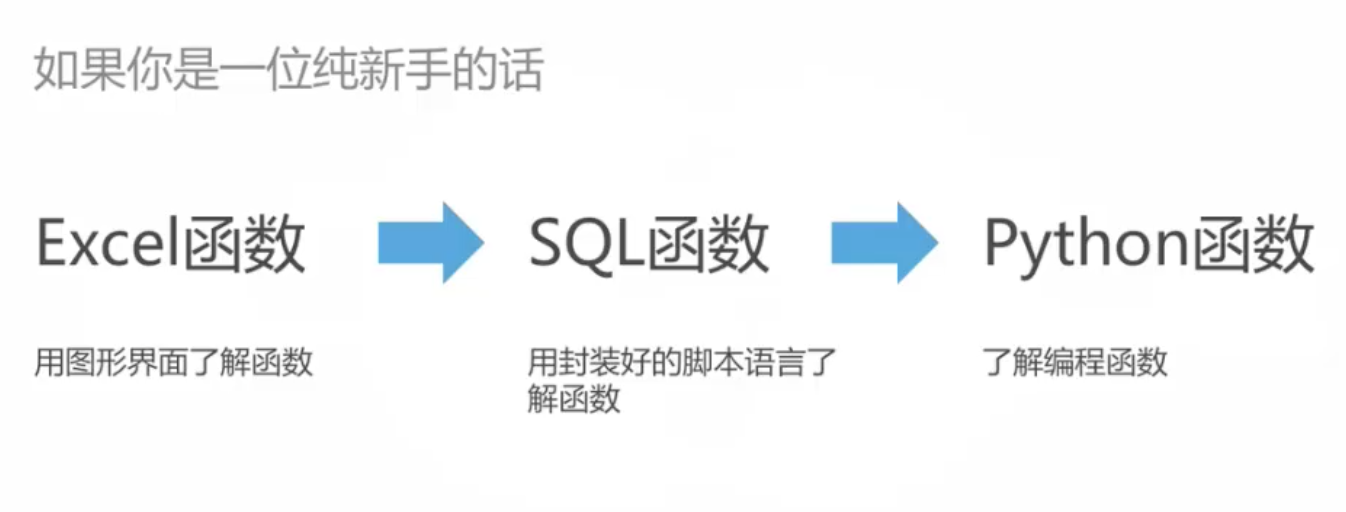
什么是函数
官方出品:函数的定义:给定一个数集A,假设其中的元素为x。现对A中的元素x施加对应法则f,记作f(x),得到另一数集B。假设B中的元素为y。则y与x之间的等量关系可以用y=f(x)表示。我们把这个关系式就叫函数关系式,简称函数。
函数概念含有三个要素:定义域A、值域C和对应法则f。其中核心是对应法则f,它是函数关系的本质特征。
文本清洗函数
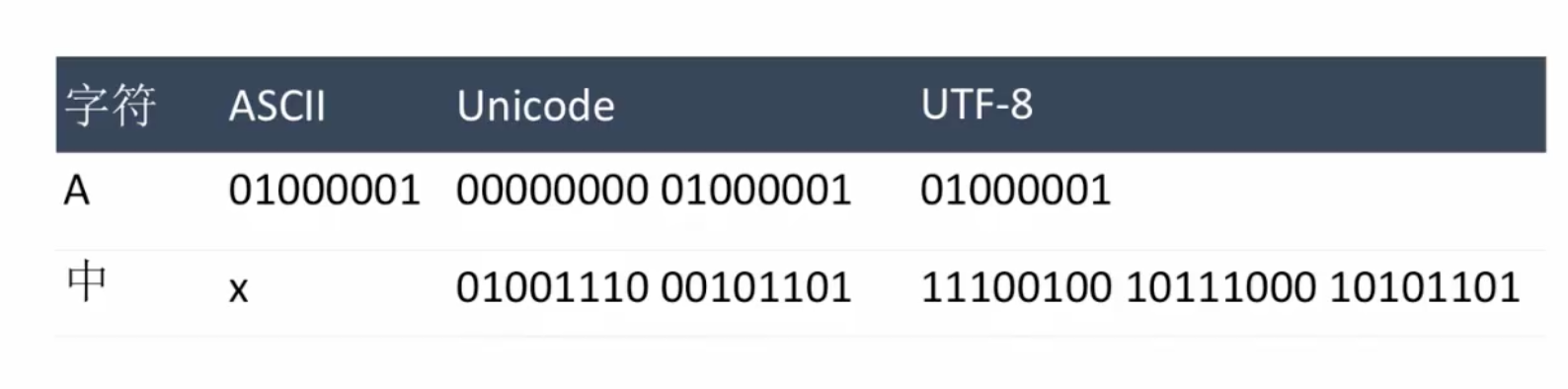
补充:编码问题
1 bite = 两种可能性 用0/1存储
1 byte = 8 bite 一共有2**8中可能性
1 byte 可以存256个字符编码,存储方式ASCII,包括英文+数字+符号。
然鹅!不适合存储汉字,使用2 byte组合,称为GB2312;后拓展为GBK,包括了繁体字;接着考虑到少数名族的文字,变成了GB2312;最后~最后~~,发明了万民码Unicode。
举例说明:
常见文本清洗函数:
find
left/right/mid
concatenate
replace
substitute
text
trim
len
练习:数据集:DataAnalyst
观察数据
1.首先观察数据,字段名称为英文,分别是城市、公司ID、公司名称、招聘岗位名称、工资等......
2. 隐藏(去除)一些暂时不需要的字段:
如companyid/positionid是唯一标志,可以通过vlookup函数进行一些关联分析,此处暂时不需要。companyfullname/compangshortname 实际是同一信息,可省略。
3. 处理缺失值
如果某一字段缺失数据较多(超过50%),分析过程中要考虑是否删除该字段,因为缺失过多就没有业务意义了。
通过选取该列,查看计数,直观判断是否存在缺失。
最终,部分字段数据缺失,但不影响分析,故忽略。
4. 数据是否一致化
一致化指的是数据是否有统一的标准或命名。例如上海市数据分析有限公司和上海数据分析有限公司,差别就在一个市字,主观上肯定会认为是同一家公司,但是对机器和程序依旧会把它们认成两家。会影响计数、数据透视的结果。
5. 数据是否有脏数据
脏数据是分析过程中很讨厌的环节。例如乱码,错位,重复值,未匹配数据,加密数据等。能影响到分析的都算脏数据,没有一致化也可以算。
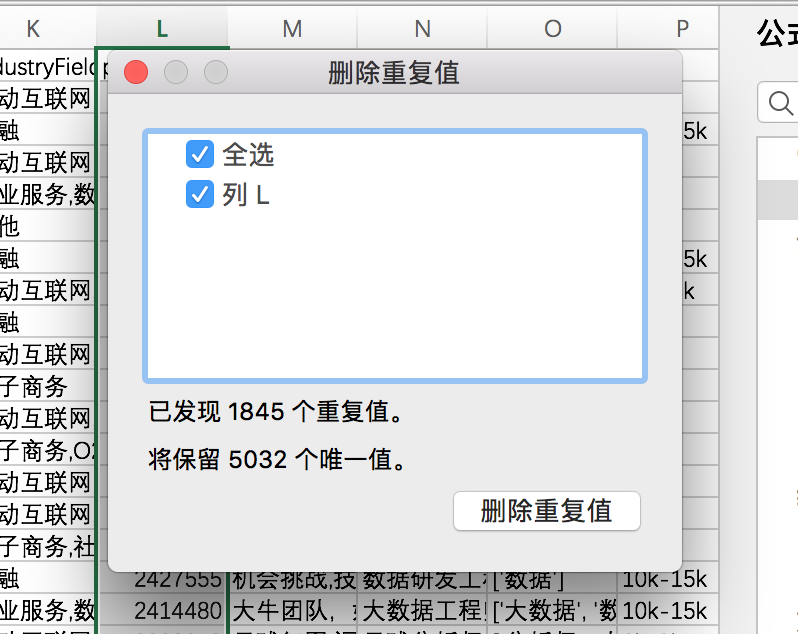
这里有一个快速窍门,使用Excel的删除重复项功能,快速定位是否有重复数据,还记得positionId么?因为它是唯一标示,如果重复了,就说明有重复的职位数据。看来不删除它是正确的。
对positionId列进行重复项删除操作
6. 数据标准结构
数据标准结构,就是将特殊结构的数据进行转换和规整。
表格中,companyLableList就是以数组形式保存(JSON中的数组)
在一些情况下,如positionadvantage、salary等需要拆分处理。
清洗数据
(1)获取最高薪资和最低薪资
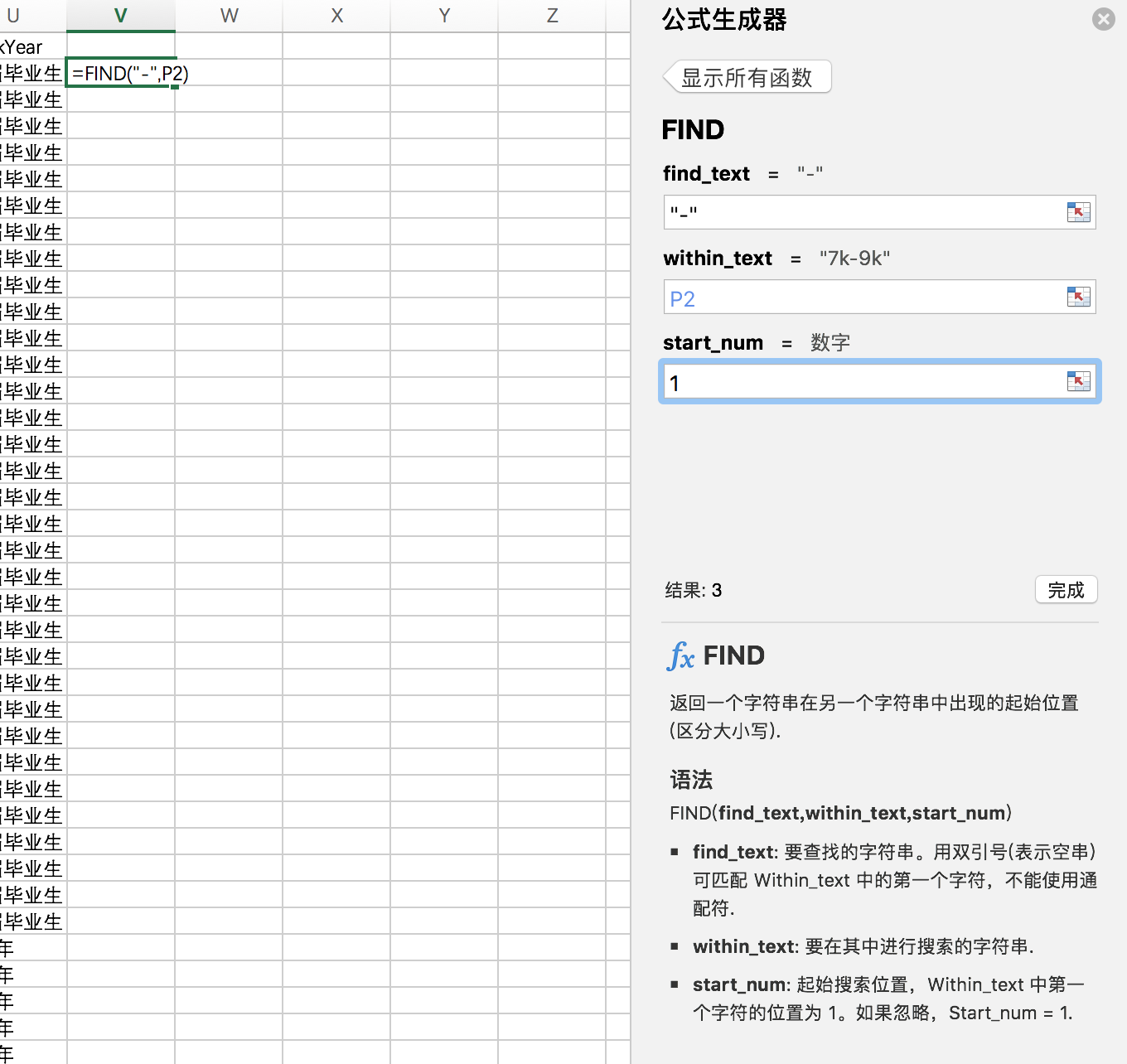
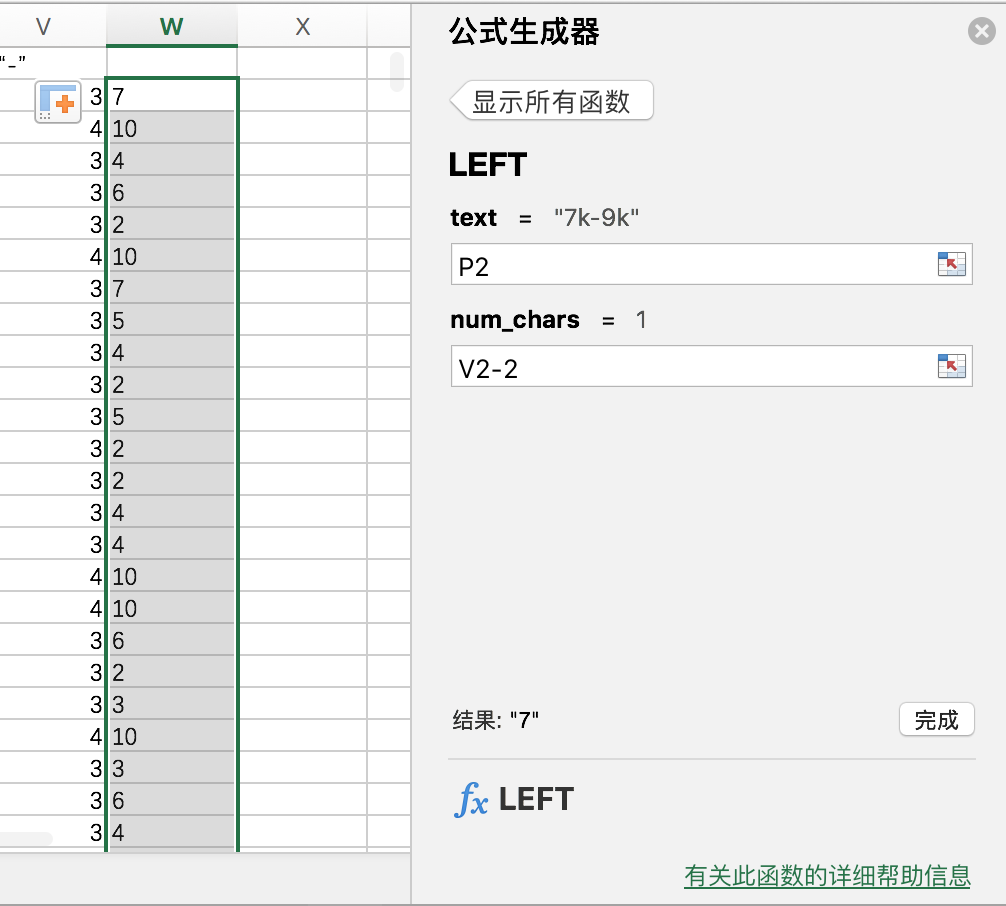
使用函数:find / right /left
具体操作:
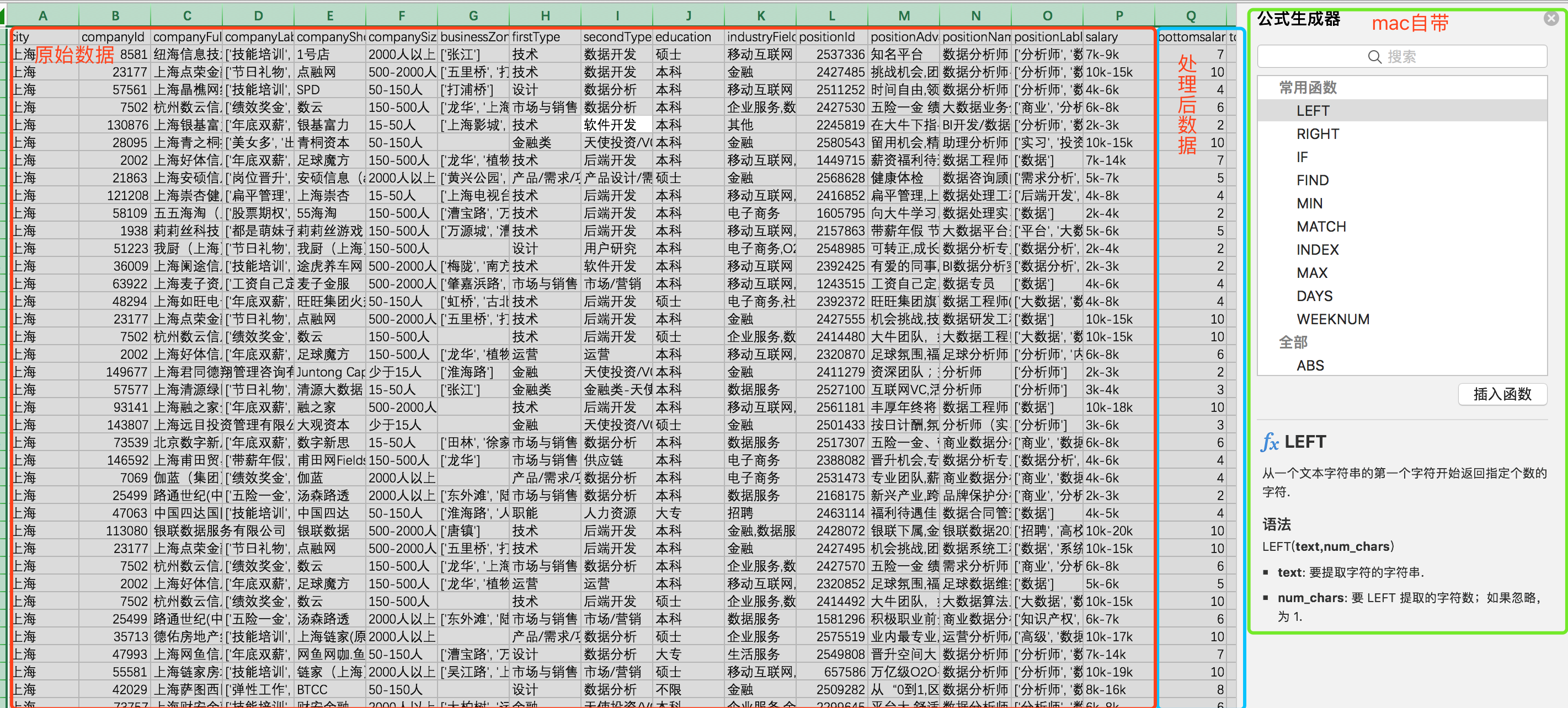
法一:find寻找“-”的位置,使用left/right函数获取“**k”。
如图(原谅我mac如此简单粗暴了):
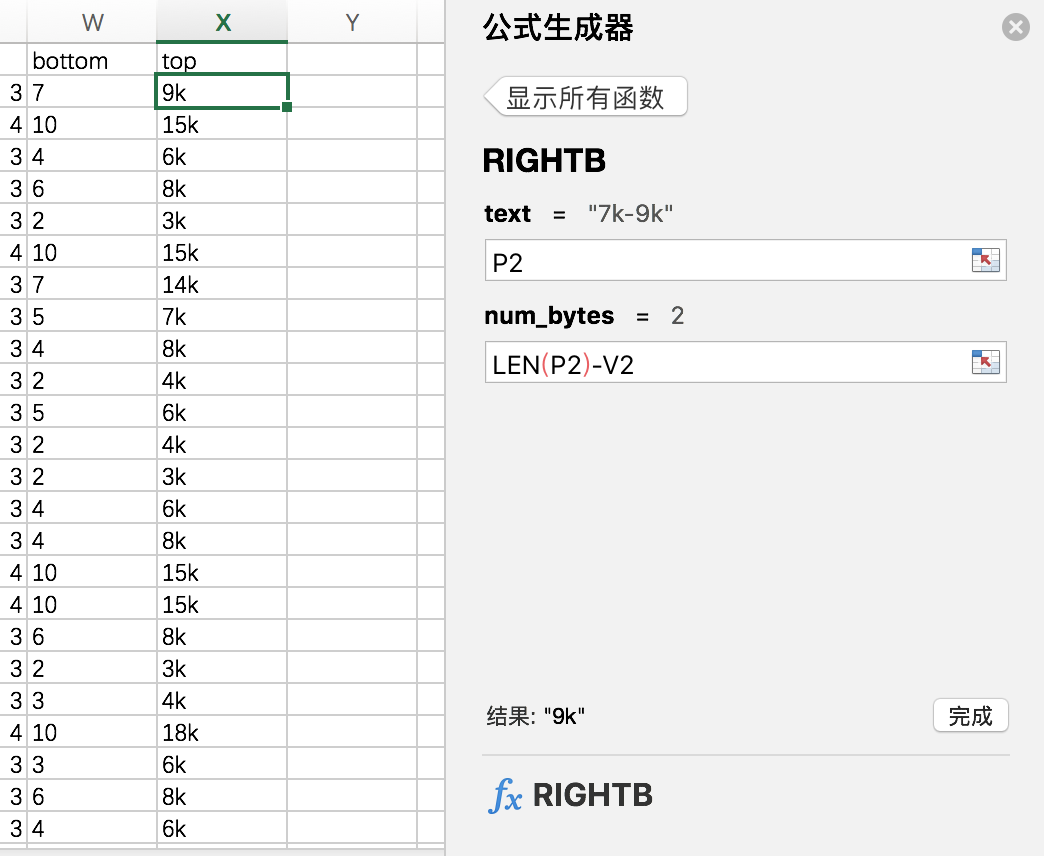
然后计算平均值等。。。
注:“&”链接符号,用法:
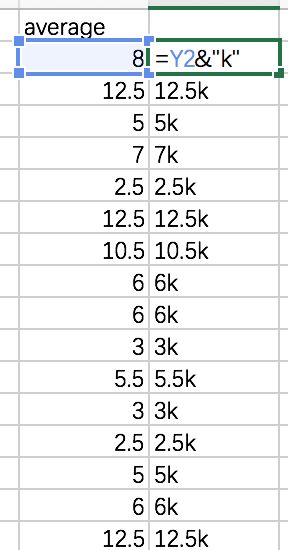
或者 concatenate
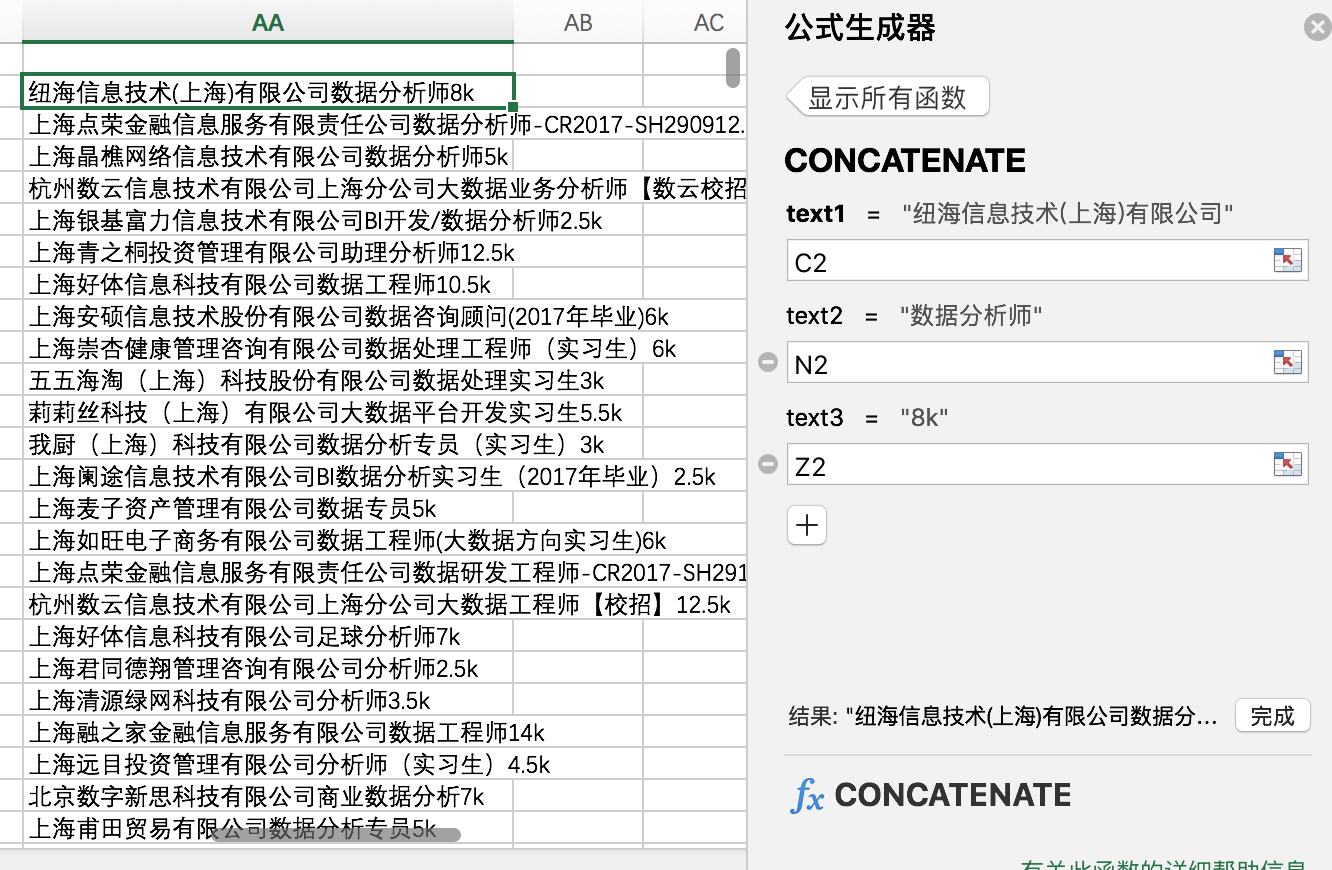
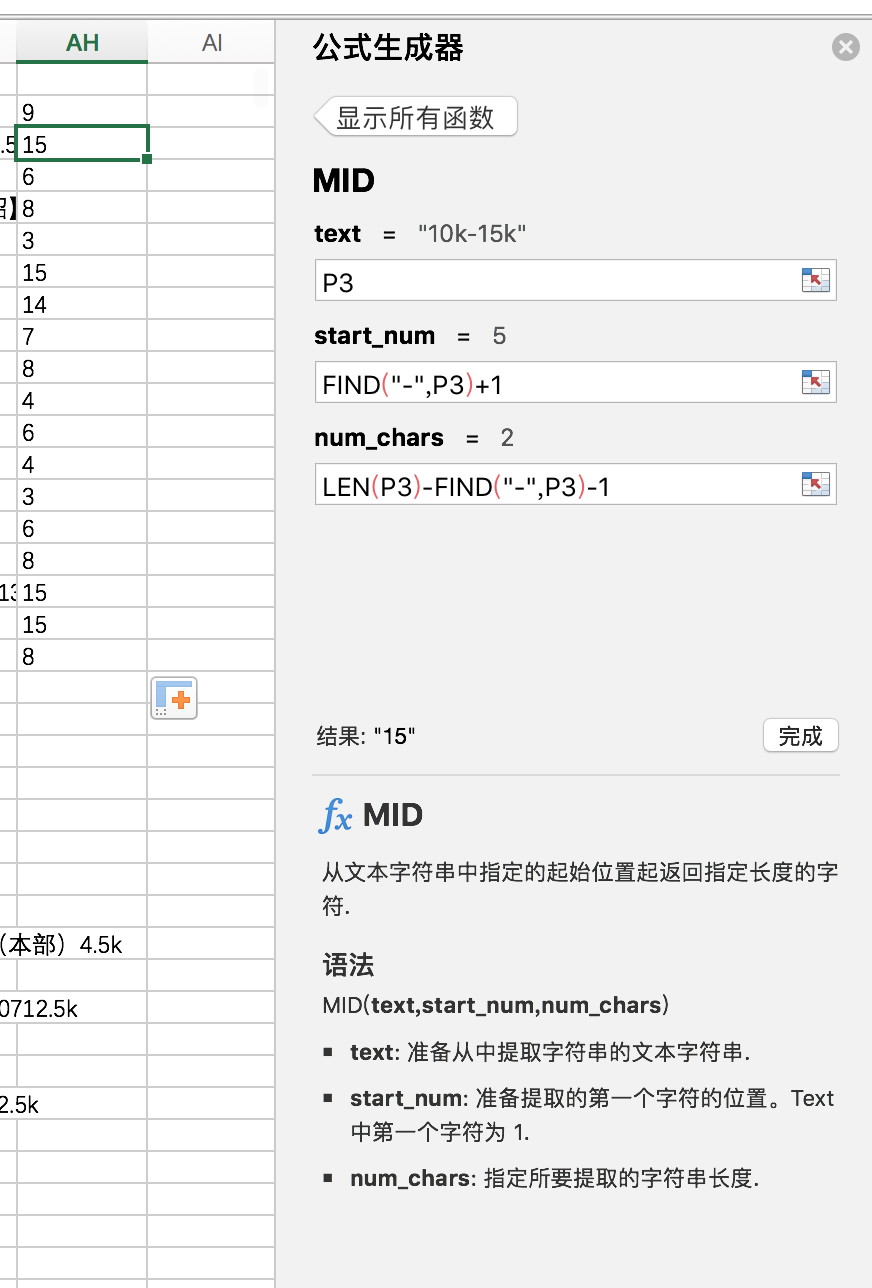
法二:使用mid函数
直接写了:topsalary = mid(salary,......)(无奈歇菜,还是按照公式生成器的操作来......)
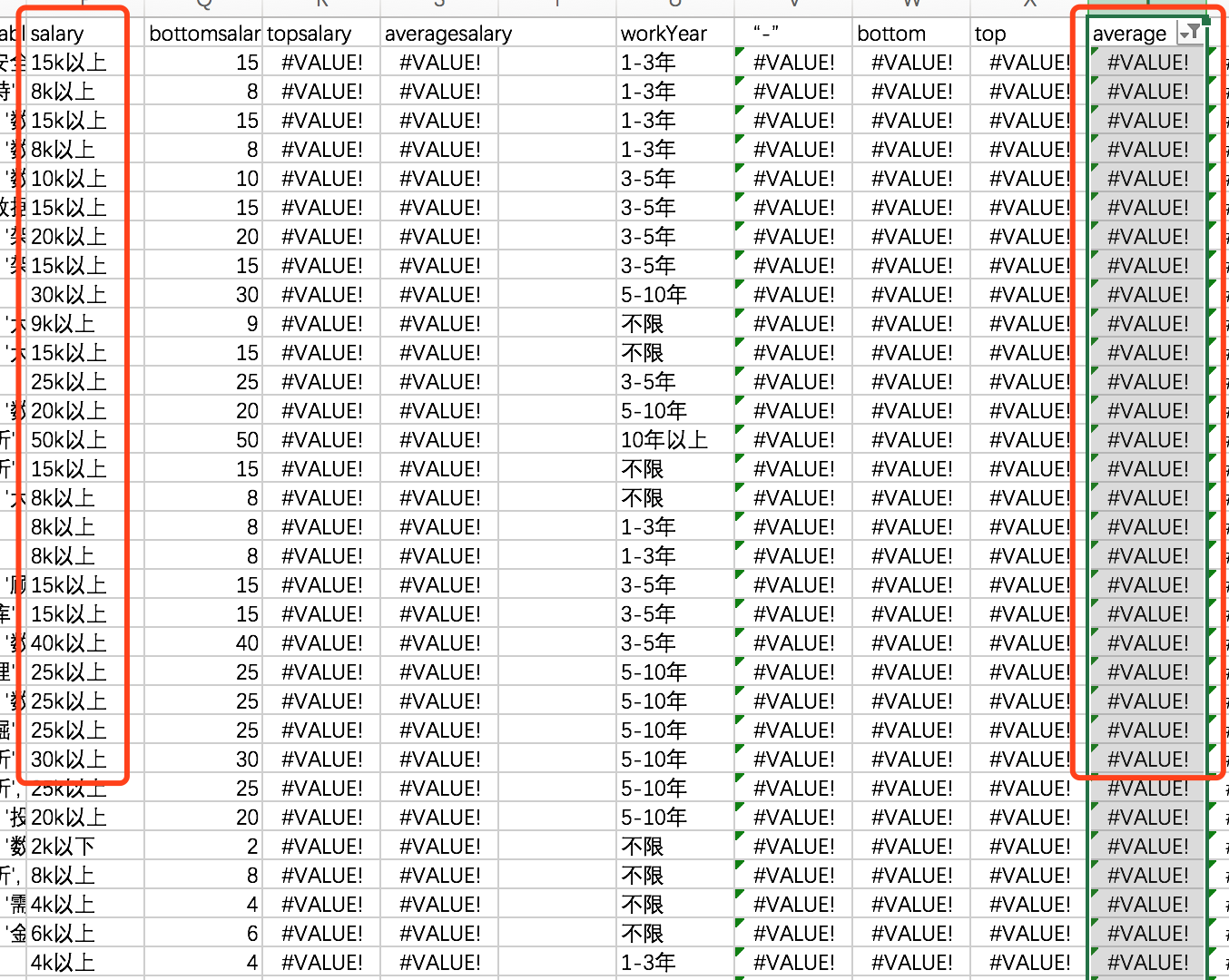
最后检查一下是否有错误,通过筛选功能发现存在“#Value”值,
原因如下:很多HR将工资写成5K以上,这样就无法计算topSalar。
为了计算方便,将topSalary等于bottomSalary,虽然也有误差。
(2)分列操作
对companglabellist分列:companyLabelList是公司标签,诸如技能培训啊、五险一金啊等等。直接用分列即可。大家需要注意,分列会覆盖掉右列单元格,所以记得复制到最后一列再分。
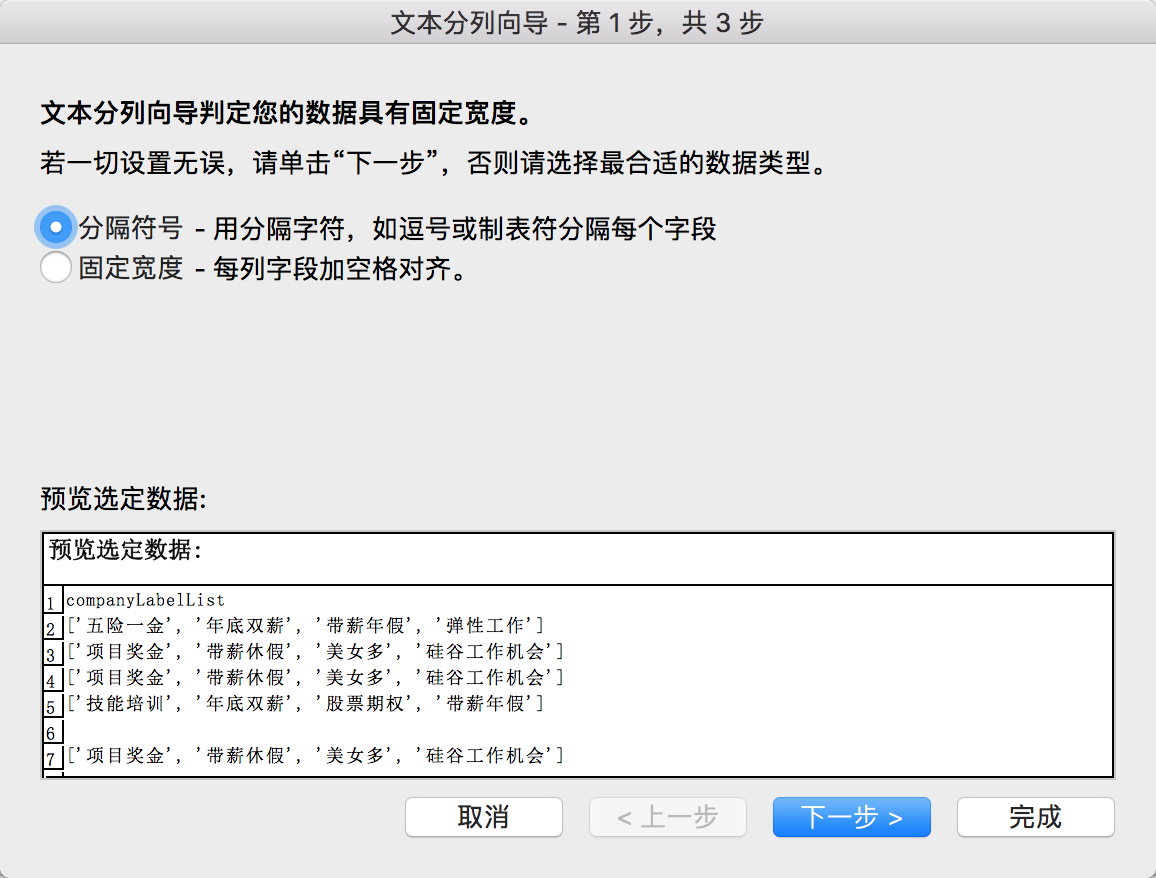
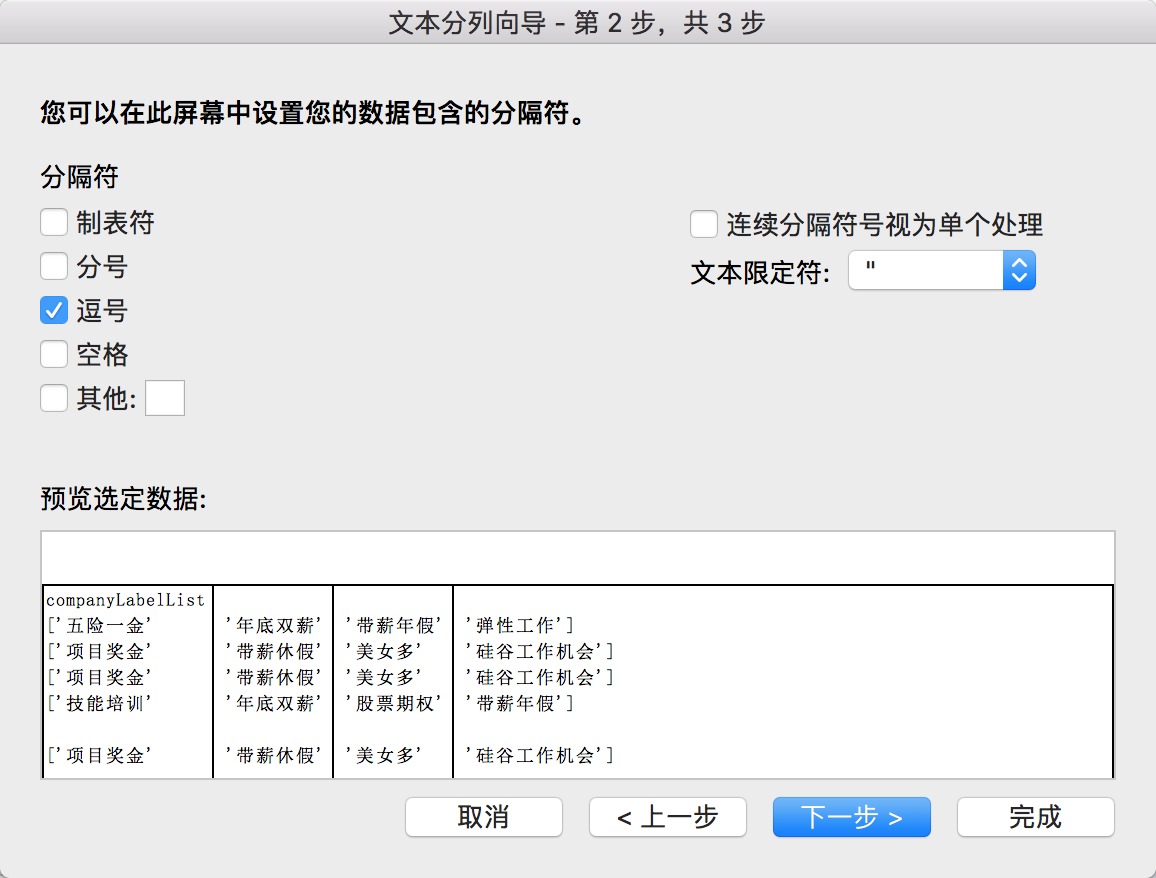
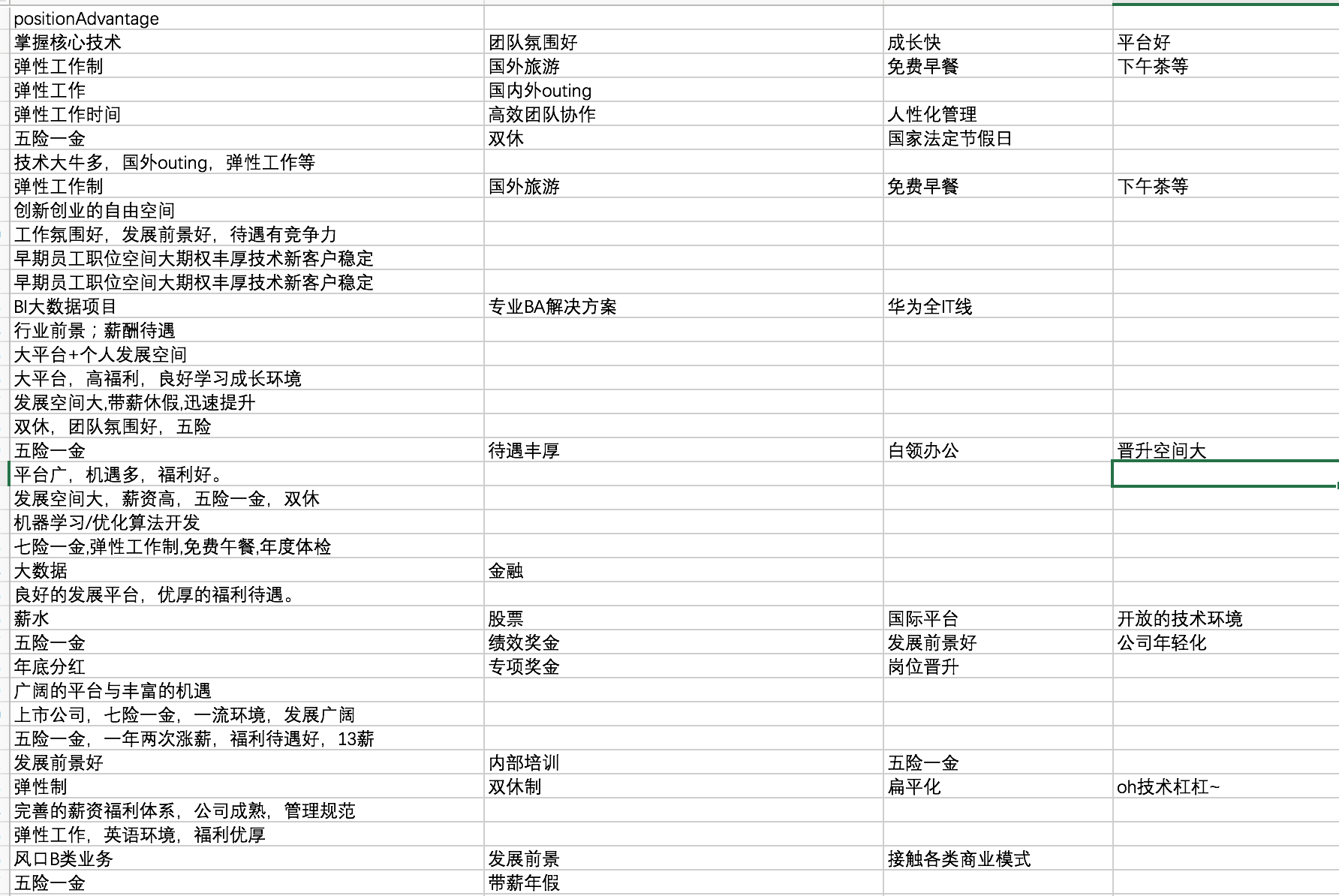
(2)对positionAdvantage的分列:
这些内容均是自定义,没有特别大的分析价值。如果要分析,必须花费很长的时间在清洗过程。主要思路是把这些内容统一成几十个固定标签,主要利用Python分词和词典进行快速清洗。
暂且分析这么多啦,接下来讲解一个神器:数据透视表,可以说是数据分析必备技能啦。(当初参加数学建模时,数据透视表可是帮了大忙!)
数据透视表
(1)单独针对positionName用数据透视表。统计各名称出现的次数。

em.....出现次数为3次以下的职位,有约一千,都是各类特别称谓。所以换个思路,用关键词查找的思路,找出包含有数据分析、分析师、数据运营等关键词的岗位。虽然依旧会有金融分析师这类非纯数据的岗位。
这里只是针对一个数据分析师岗位的统计,所以先确定关键字“数据分析”、“数据运营”、“分析师”,并使用if函数,如果满足上述三个关键字则返回“True”=1。

用find和数组函数结合,shift+ctrl+enter输入。就得到了多条件查找后的结果。
单纯的find 只会查找数据分析这个词,必须嵌套count才会变成真数组。
然后再使用数据透视表,基本是很直观清洗了!

分析过程
分析过程有很多玩法。因为主要数据均是文本格式,所以偏向汇总统计的计算。如果数值型的数据比较多,就会涉及到统计、比例等概念。如果有时间类数据,那么还会有趋势、变化的概念。
整体分析使用数据透视表完成,先利用数据透视表获得汇总型统计。
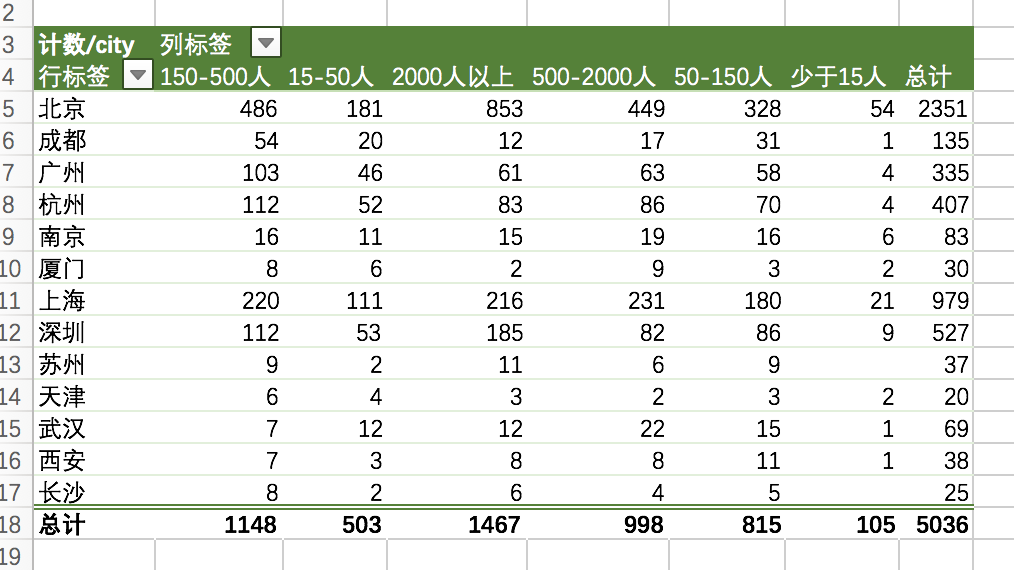
似乎是公司越大,需要的数据分析师越多。
但这样的分析并不准确。因为这只是一个汇总数据,而不是比例数据,我们需要计算的是不同类型企业人均招聘数。
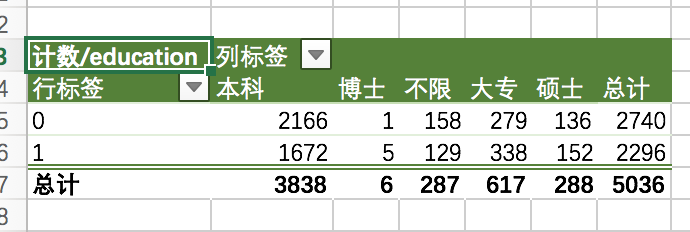
数据分析师岗位与学历的统计:
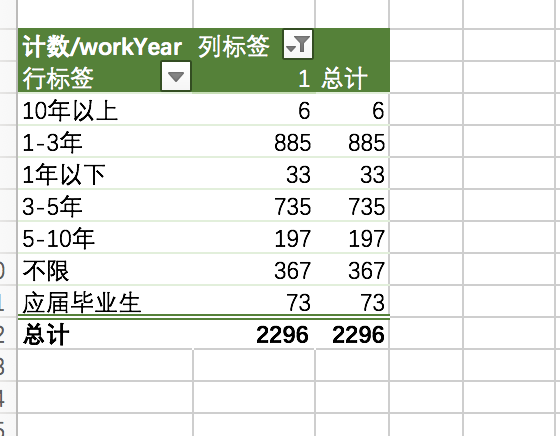
数据分析师岗位与工作年限的统计:
各城市不同工作年限的薪资水平:
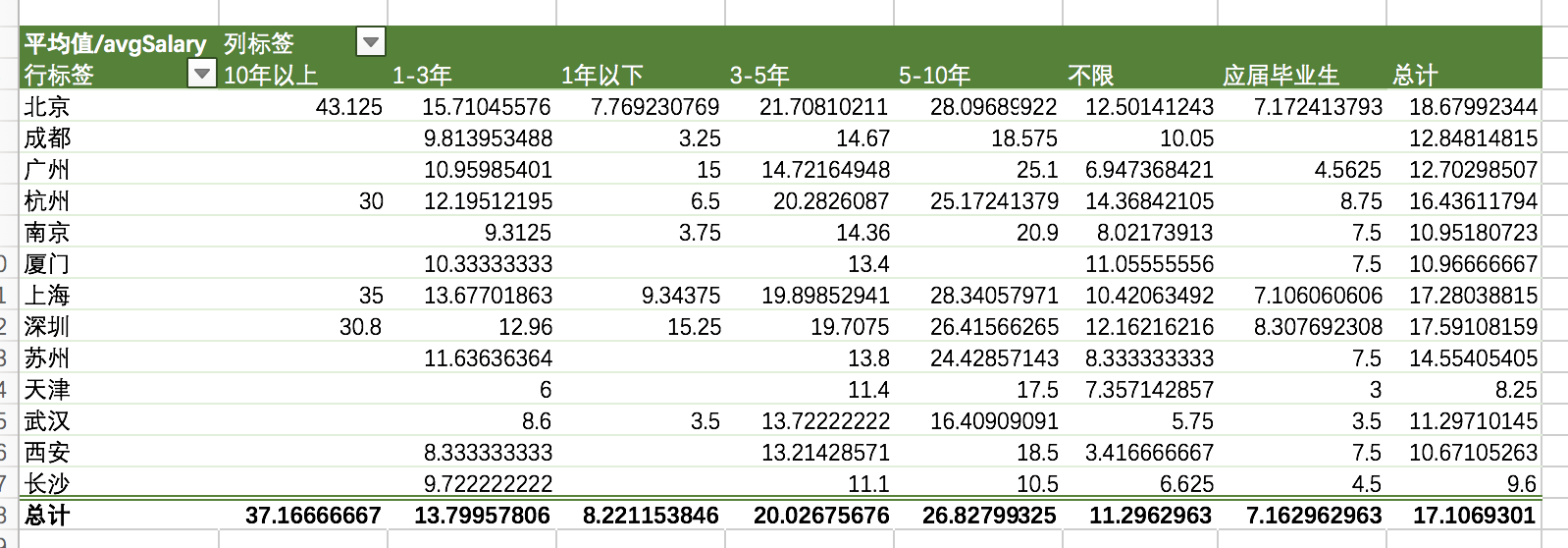
注:因为存在薪资极值影响。而数据透视表没有中位数选项。我们也可以单独用分位数进行计算,降低误差。
薪资可以用更细的维度计算,比如学历、比如公司行业领域等。
另外数据分析师的薪资,可能包括奖金、年终奖、季度奖等隐形福利。部分企业会在positionAdvantage的内容上说明,可以用筛选过滤出这类关键词,作为横向对比。
以上只是大概了解。。。其实还有一堆函数:逻辑运算函数、计算统计函数、时间序列函数....
慢慢写。。。。excel的笔记写着有点累(哭唧唧~~)
