作者:宅必备
一个会写Python的Oracle DBA
个人公众号:宅必备
前文传送门:
[Python程序]利用微信企业号发送报警信息
[Python爬虫]使用Python爬取静态网页-斗鱼直播
[Python爬虫]使用Python爬取动态网页-豆瓣电影(JSON)
[Python爬虫]使用Python爬取动态网页-腾讯动漫(Selenium)
[Python爬虫]使用Selenium操作浏览器订购火车票
上节我们说了如何操作浏览器自动订购12306火车票
这节内容为如何利用fiddler分析登陆过程并使用requests进行登陆,之后领取下载豆
开发环境
操作系统:windows 10
Python版本 :3.6
爬取网页模块:requests
分析网页工具:BeautifulSoup4,fiddler4
关于requests
requests是一个第三方库,可以用来模拟浏览器请求,如get,post
它也有Session功能,可以保持会话信息,如cookie等,这个可以让我们用来进行登陆后的操作
具体请参加官网:
http://docs.python-requests.org/en/master/
关于fiddler4
fiddler4 是一个网页分析的工具,和自带的开发者工具一样,不过其功能更为强大
我们可以通过官网免费下载并使用
官方网址
https://www.telerik.com/download/fiddler
详细教程查看如下网站
http://docs.telerik.com/fiddler/configure-fiddler/tasks/configurefiddler
模块安装
lxml为解析网页所必需
pip3 install requests
pip3 install BeautifulSoup4
1.分析过程
1.1 登陆51cto并进行登陆
请保持fiddler4 全程开启状态
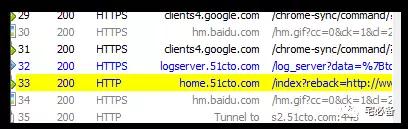
1.2 使用Fiddler4 查找功能查找登陆页面
也可以直接使用快捷键Ctrl+F,我们这里查找用户名bsbforever
注意这里需要勾选decode compressed content

之后可以看到界面左边连接黄色高亮
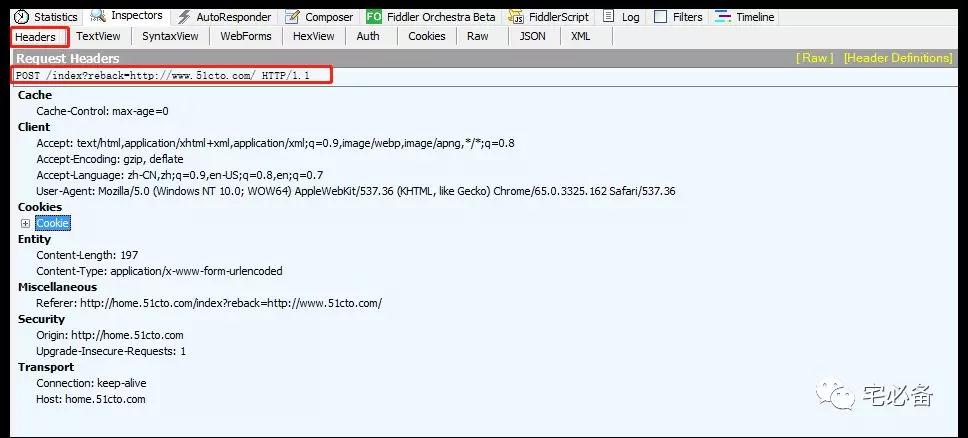
1.3 查看请求网页和header

1.4 查看POST请求参数
接下来我们双击该页面从右侧的WebForms查看POST参数

也可以查看raw标签
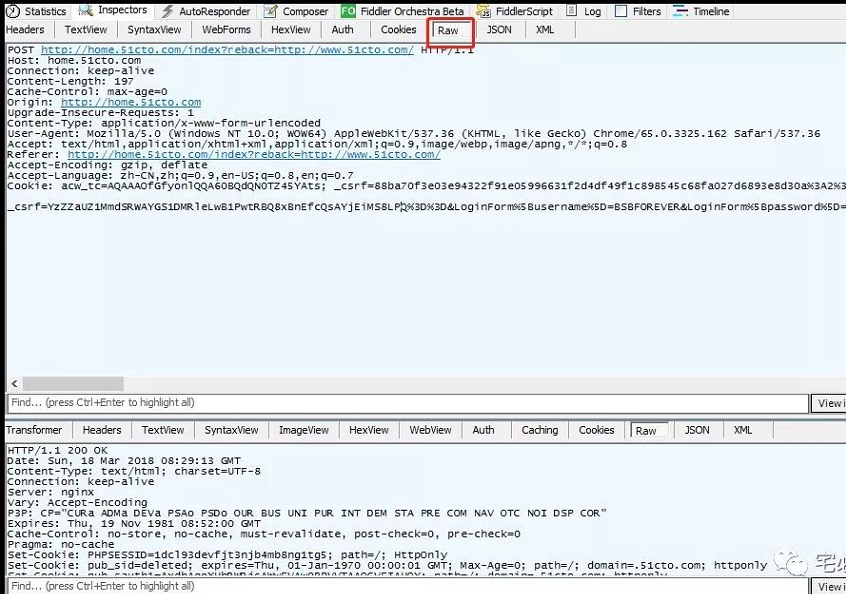
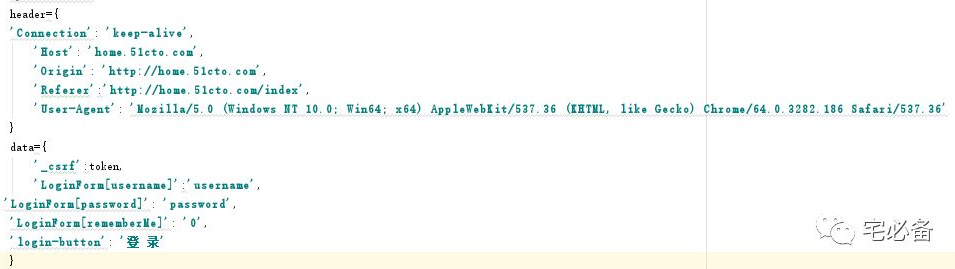
从上面我们可以看出提交的信息有:
_csrf
username
password
rememberme
login_button
其他都很好知道其含义,只有第一个我们不确定其含义
我们接下来重复登陆操作,可以看到每次csrf值是不一样的
这时我们需要找到该值是如何产生的
1.5 查看csrf值
这里我们仍然使用搜索功能,我们搜索csrf的值
这时我们可以看到左侧有2处标黄,我们查看另外个页面的响应
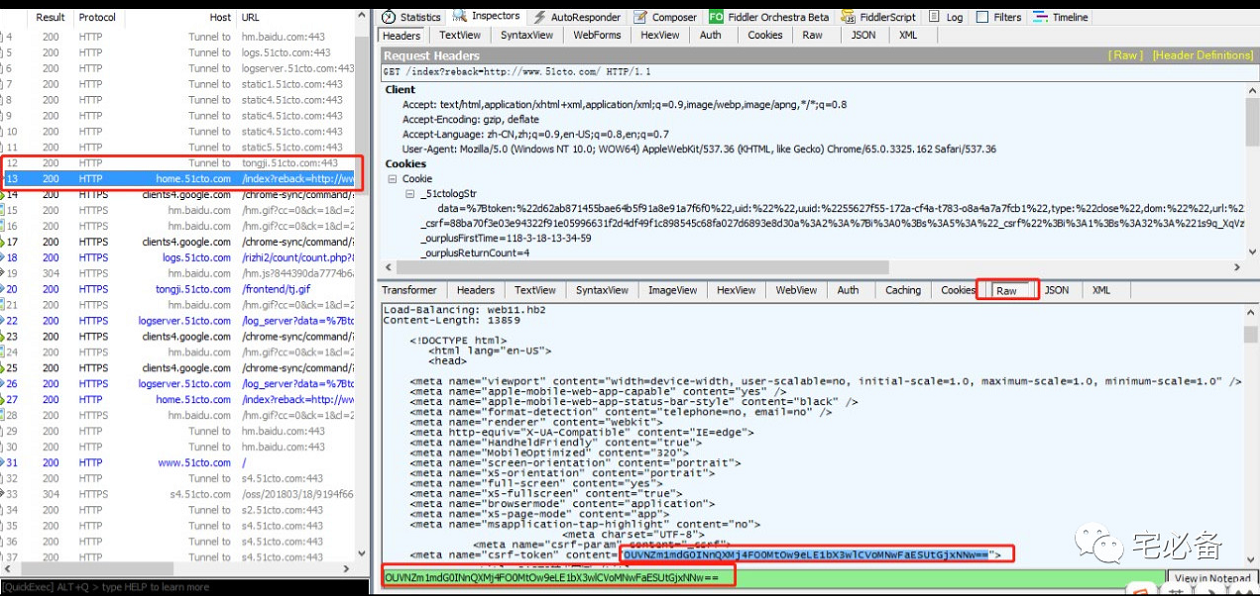
可以看到该csrf值存在于为登陆前的页面中
这时我们可以提取该值
1.6 POST模拟登陆
接下来我们构造header和post data 使用requests.post进行登陆
这时使用Session方法保持会话信息
1.7 登陆后领取下载豆
这里根据抓取到的页面进行POST请求
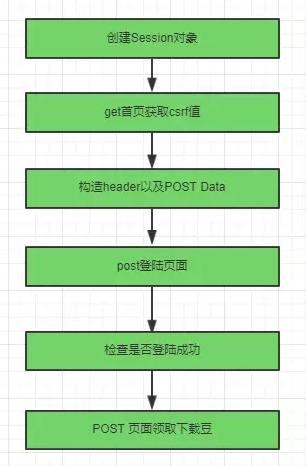
2. 登陆流程图
3. 代码介绍
3.1 import相关的模块
import requests
from bs4 import BeautifulSoup
3.2 新建requests会话
后续都使用s变量进行请求
s=requests.Session()
3.3 get首页获取csrf值
content=s.get('http://home.51cto.com/home').content
soup = BeautifulSoup(content,"lxml")
token=soup.find('meta',attrs = {'name' : 'csrf-token'})['content']
3.4 构造header和data
3.5 post 登陆页面
s.post(url=login_url,headers=header,data=data)
3.6 判断是否登陆成功
result=s.get('http://home.51cto.com/home').text
if 'bsbforever' in result:
print ('恭喜,登陆51cto成功,领取下载豆中..')
3.7.领取下载豆
download=s.post('http://down.51cto.com/download.php?do=getfreecredits&t=0.8367867217711695').text
4.执行结果:

5.注意事项:
fiddler请保持全程开启
请使用Session方法保持登陆状态
本脚本仅用于学习用途
6.源码位置
源码请访问我的github主页:
https://github.com/bsbforever/spider/blob/master/login_web.py
Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
小编的Python入门视频课程!!!
崔老师爬虫实战案例免费学习视频。
丘老师数据科学入门指导免费学习视频。
陈老师数据分析报告制作免费学习视频。
玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
丘老师Python网络爬虫实战免费学习视频。

