一、数据预处理的重要性
在机器学习中,数据的准确性关乎着机器学习任务的成败、直接影响着预测测的结果。
而数据的准确性,一方面指数据的完整度,用于机器学习预测的数据是否全面;另一方面则指数据的统一度,数据与数据之间的分布是否统一。
二、在Python中进行数据预处理
对数据进行预处理的方式有很多中,比如规范化、标准化、二值化、编码分类等等。我们可以通过sklearn模块的preprocessing子模块对数据进行预处理,其中包含了各种数据预处理的集成函数:

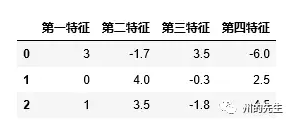
假如,我们有一组数据:
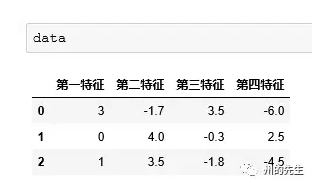
每一行特征数据的数值都相差比较大,比如第一行最大值为3.5,最小值为-6,相差为9.5;第二行最大值为4,最小值为-0.3,相差为4.3。
将其转化为数组可以直观地看出来:

下面,我们一一介绍各种数据预处理方法以及在Python中的实现方法:
标准化处理
对数据集进行标准化处理是很多许多机器学习估计器的通用要求 ,因为如果单个特征看起来不像标准正态分布数据那么它们可能会表现得很差。
来看看实际的例子:

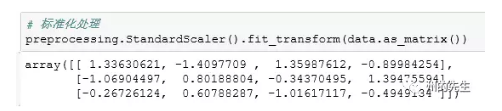
我们调用preprocessing模块的StandardScaler()方法,对data数组进行标准化缩放,结果返回了一个数值差异比原始数组小多了的数组。
将值缩放到0-1之间
还有一种标准化方法MinMaxScaler()能够将数值缩放到0到1之间,更好的约束的数组特征:
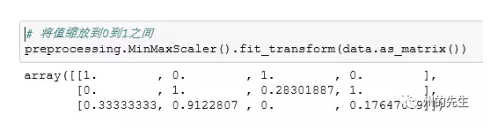
可以发现,data数组中所有的值都化为了0到1之间的数据。
数据正常化
数据的正常化处理(Normalization)则是将个体样本数值缩放为单位标准。
我们可以在preprocessing中的Normalizer()方法进行调用,下面看实际的处理效果:
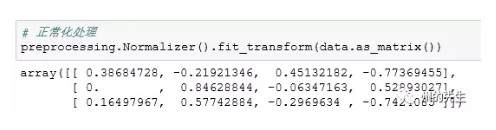
数据二值化
前面介绍的数据预处理方法都是对数据进行缩放,除了对数据进行缩放之外,我们还可以对数据进行二值化处理,将不同的数据全部处理为0或1这两个数值。
下面看看实际的效果:
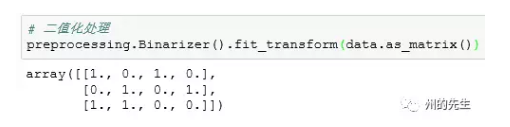
对比一下原始的数据:
似乎其将小于0的数据都处理为了0,大于1的数据都处理为了1。我们可以对其指定threshold参数来设置二值化的阀值,下面请看:
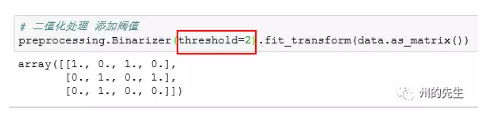
可以发现,默认情况下被处理为1的一些数据(比如1),已经被处理为了0。
处理分类编码
除了上述示例中的数值数据,我们在实际的数据处理过程中还会遇到数据为分类字符串的情况,比如下面这种情况:

这样的字符串数据既不能转换为数据,也无从缩放。不过这种数据多是用于表示分类的,我们可以使用编码分类特征来对这类数据进行预处理。
在sklearn中,对应的处理方法为preprocessing.LabelEncoder(),下面我们看一个实际的演示:
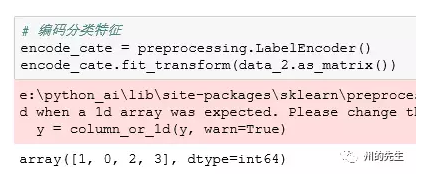
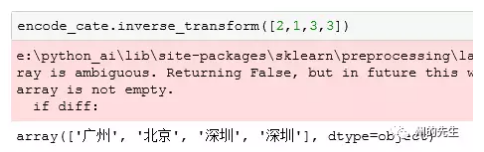
可以发现,我们的四个城市名称字符串被编码为了值为1、0、2、3的数组。那么如果取回之前的字符串数据呢,可以使用classes_属性进行取回:

同时还能根据编码后的数字,来获取到真实的分类字符串:
处理缺失值
在实际的数据集中,还经常会出现有缺失值的情况,其中有一些缺失值表示为None,有一个则是表示为一个空字符串"",面对这种情况,我们可以将有缺失值的行数删除,但是如果数据量大的话,可能会影响到机器学习模型的准确性。一个比较好的方法是填充这些缺失值。
处理缺失值在pandas模块中就有很成熟的方法来实现,比如fillna()方法。
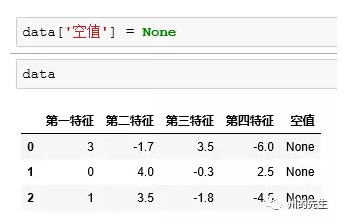
我们在data中新增一列空值:
再使用fillna()方法,对空值进行填充:
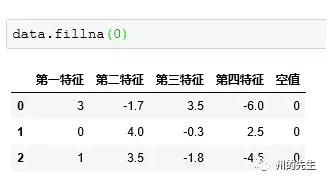
这样就完成了缺失值的填充了。
更多
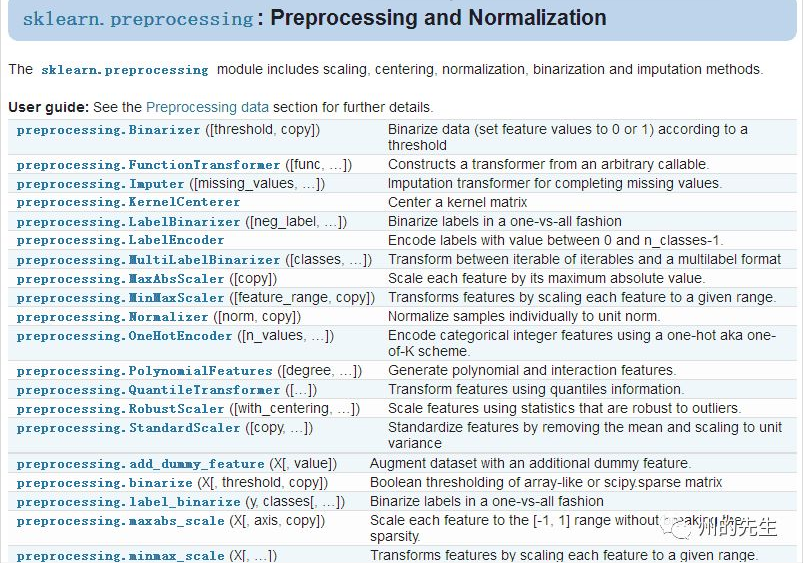
除了上述介绍的sklearn的数据预处理方法,还有很多没有提及到,在sklearn的官方文档中,大家可以详细去了解:
三、下一篇
在了解了数据预处理的几种基本方法后,下一篇我们将介绍创建一个机器学习回归模型。

