这篇文章是初次使用sparklyr扩展包来进行一些数据分析,对Spark牵扯不是很多。使用的数据是movieLens 100k,这份数据包含943个用户对1680部电影的评分数据,如需获取数据请在文末点击阅读原文。
准备工作
#安装sparklyr包
install.packages("sparklyr")
library(sparklyr)
library(dplyr)
sc <- spark_connect(master = "local")#连接到本地spark
如果你没有安装spark,在安装好sparklyr包之后,右上角这块会出现一个spark的按键,点击之后它就会引导你下载spark,而且自动配置。好了之后我们就可以连接到spark。
连接成功之后,可以在浏览器中输入:http://127.0.0.1:4040,打开之后我们可以看到如下页面。
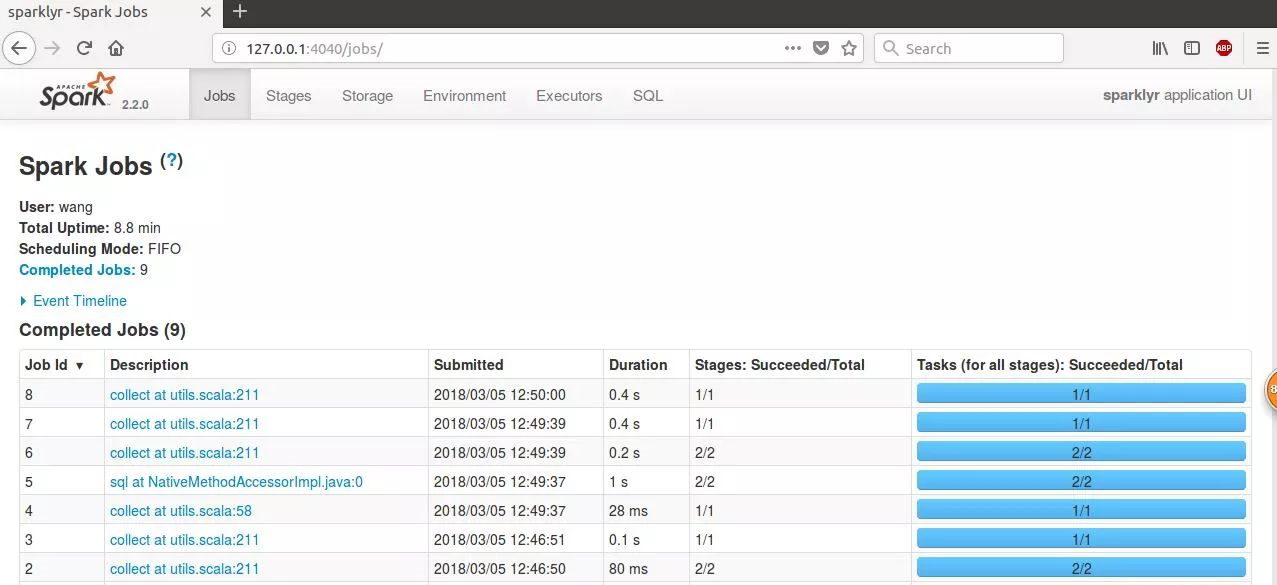
通过storage,我们可以看到我们已经保存到spark中的数据。如图已经保存了u_data,和u_user。这两个数据是后面导进去的,刚开始的时候里面是空的。
现在开始,我们来一步一步分析这份数据。
探索用户数据
u.user文件保存的是用户的ID,年龄,性别,职业和邮编。在这份数据中,我们分析一下用户的年龄分布和职业。
年龄分析
u_user<-read.table("/home/wang/Desktop/ml-100k/u.user",sep = "|")
u_user<-copy_to(sc,u_user)#将数据复制到spark
names(u_user)[1:5]<-c("id","age","gender","occupation","zipCode")
library(ggplot2)
u_user<-u_user %>% collect
ggplot(u_user,mapping = aes(age))+geom_histogram(fill='steelblue')+scale_x_continuous(breaks = seq(from=0,to=80,by=5))
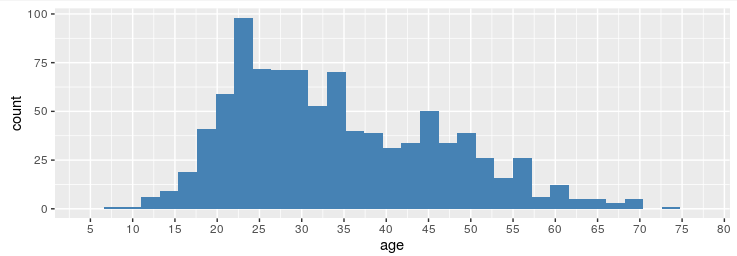
我们可以发现,年龄在20到35的人数特别多,45岁的人也挺多的。
2. 职业分析
用所有用户进行职业分析
occ <- count(u_user,occupation) %>% arrange(desc(n))%>%collect()#统计职业
ggplot(occ,aes(x=reorder(occupation,n),y=n))+geom_bar(stat = "identity",fill='steelblue')+
theme(axis.text.x=element_text(angle = 70,hjust = 0.5,vjust = 0.5,size = 14))
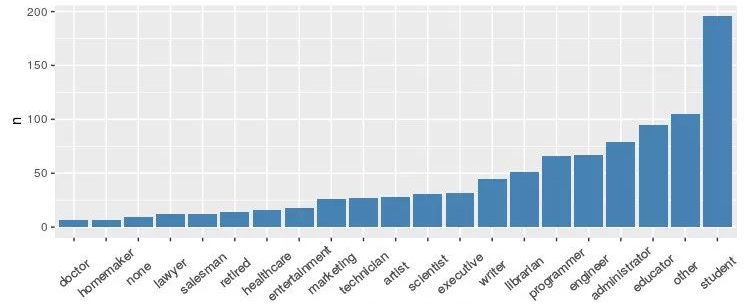

看来还是学生党居多,周末没事带上女盆友看个电影逛逛街,这也很符合前面的年龄分析。可怜的医生是最少的,在这里向白衣天使们致敬!!!
探索电影数据
u.item文件,它包含电影ID,电影名称,发行日期,电影发行日期,IMDb链接,以及电影类型。在这份数据中我们分析一下那些电影类型更受用户喜爱,以及用户喜欢看那个年代发行的电影。
电影类型
包含了19个类型,分别是 unknown , Action , Adventure ,Animation ,Children’s , Comedy ,Crime ,Documentary ,Drama ,Fantasy ,Film-Noir , Horror , Musical , Mystery , Romance , Sci-Fi ,Thriller , War , Western。
u_item<-read.table("/home/wang/Desktop/ml-100k/u.item",sep = '|',colClasses = c("integer","character","factor","factor","character",rep("integer",19)),quote = "")
u_item_col_names<-c('movie_id','title','release_date','video_release_date','imdb_url','unknown','Action','Adventure','Animation','Childrens','Comedy','Crime ','Documentary','Drama','Fantasy','Film-Noir',' Horror','Musical','Mystery',' Romance','Sci-Fi','Thriller','War','Western')#列名
colnames(u_item)<-u_item_col_names
movie_genre<-apply(u_item[6:24],2,FUN =sum)#计算各个类型的电影评分总数
movie_genre<-as.vector(movie_genre)
genre<-data.frame(genres=c('unknown','Action','Adventure','Animation','Childrens','Comedy','Crime ','Documentary','Drama','Fantasy','Film-Noir',' Horror','Musical','Mystery',' Romance','Sci-Fi','Thriller','War','Western'),times=movie_genre)
ggplot(genre,aes(x=genres,y=times))+geom_bar(stat = "identity",fill='steelblue')+
theme(axis.text.x=element_text(angle = 20,hjust = 0.5,vjust = 0.5,size = 8))
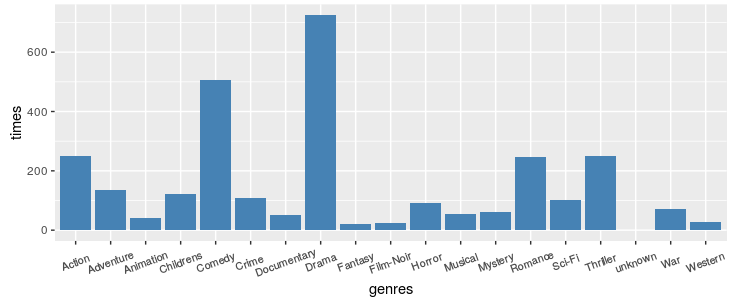
看来大家还是喜欢看戏剧类和喜剧类,罗温·艾金森好像在当时就挺火的。
电影发行时间
u_item<-read.table("/home/wang/Desktop/ml-100k/u.item",sep = '|',colClasses = c("integer","character","factor","factor","character",rep("NULL",19)),quote = "")
m_col_names<-c('movie_id','title','release_date','video_release_date','imdb_url')
colnames(u_item)<-m_col_names
u_item_title<-u_item$title
rData<-u_item$release_date
head(rData)
year<-as.character(rData)%>%as.Date(format = '%d-%b-%Y')#提取时间
head(year)#如果year为 NA 运行一下这句试试 Sys.setlocale("LC_TIME","C")
year<-substr(year,1,4)#提取年
year<-table(year)#统计year
df<-as.data.frame(year)
ggplot(df,aes(x=df$year,y=df$Freq))+geom_bar(stat = "identity",fill='steelblue')+
theme(axis.text.x=element_text(angle = 70,hjust = 0.5,vjust = 0.5,size = 8))
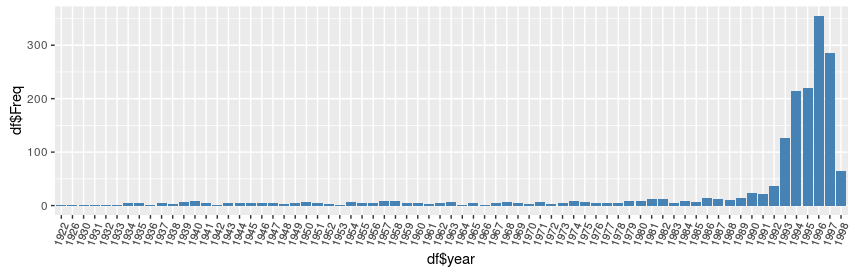
数据中的电影发行时间从1922年到1998年,其中观看量最大的是1993年到1998年,其中1996年的电影观看量最大,其次是1997年。
探索评分数据
u.data文件包含有电影评分,现在还分析大家的评分情况。
u_data<-read.table("/home/wang/Desktop/ml-100k/u.data",sep = "\t")
u_data<-copy_to(sc,u_data) # 将数据复制保存在spark
col_n_udata<-c("userId","itemId","rating","timestamp")
names(u_data)<-col_n_udata
rating<-table(select(
u_data,rating)%>%collect()
)%>%as.data.frame()
ggplot(rating,aes(x=Var1,y=Freq))+geom_bar(stat = "identity",fill='steelblue')
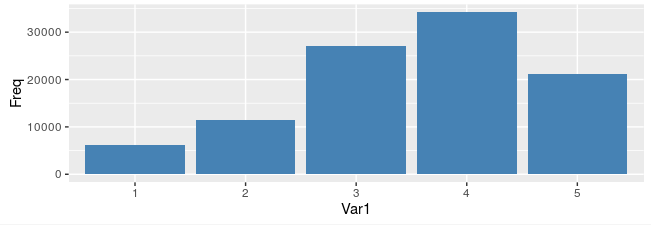
看来大家的评分还是比较中肯的,一般都在4分左右。
关闭spark
spark_disconnect(sc)
OK,今天就分享到这里,有什么问题,欢迎大家在留言区讨论,下一篇文章会是基于spark的机器学习算法ALS的电影推荐,谢谢大家支持。如需获取数据,点击阅读原文即可,提取码:4l9y。
☞推荐阅读☜
1:基于 TensorFlow 的图像识别(R实现)
2:聚类分析简单介绍(附R对应函数介绍)
3:日期格式那么多,处理起来却贼简单
4:啤酒和尿布的故事是真的吗
5:我把我用R写的第一个爬虫就献给了国家
6:搭建一款属于你自己的图像识别系统。



