前言
前段时间,想打开kaggle的比赛大门,然后去官网看了一些入门kaggle和注意事项
最后,官方提供了一个kaggle经典预测案例:Titanic乘客生存预测
其实,在这之前,我也使用过kaggle的数据
写过两篇数据分析:
Python数据分析系列(1)——葡萄酒评分
Python数据分析系列(2)——美国纽约皇后区空气质量分析
这个案例的原文地址是:
https://www.kaggle.com/startupsci/titanic-data-science-solutions
中文翻译解读过来难免和原文有所出入,有兴趣大家可以看看原文
这个Titanic故事大家都很熟悉,我就不在此赘述了,至于这个机器学习案例
简而言之,就是根据乘客的各项数据预测最终他/她生存还是死亡。
学完我Python基础,又想入坑数据分析挖掘机器学习可以直接看这个
我会加很多注释哒~
导入需要的包
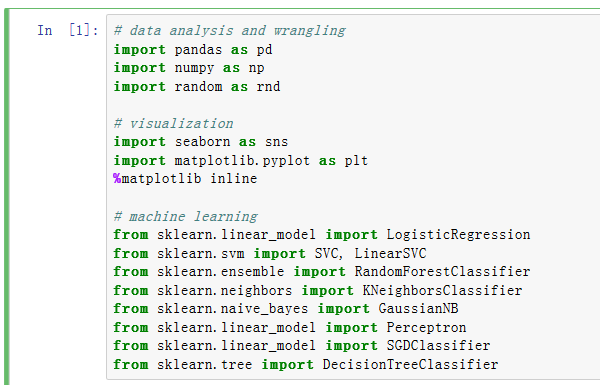
导入的包分别是数据分析、数据可视化、机器学习的,如果你想实践却发现某个包没有,你就安装一下咯~
数据探索
我们看看官方给的数据(这是训练集数据,测试集类似):
然后用pandas读取官方提供的训练集和测试集:

可以看看训练集的数据字段(列名):

- PassengerId => 乘客ID
- Survived => 是否存活
- Pclass => 乘客等级(1/2/3等舱位)
- Name => 乘客姓名
- Sex => 性别
- Age => 年龄
- SibSp => 堂兄弟/妹个数
- Parch => 父母与小孩个数
- Ticket => 船票信息
- Fare => 票价
- Cabin => 客舱
- Embarked => 登船港口
数据探索首要就是搞清楚数据的类型,是类别还是数值型?
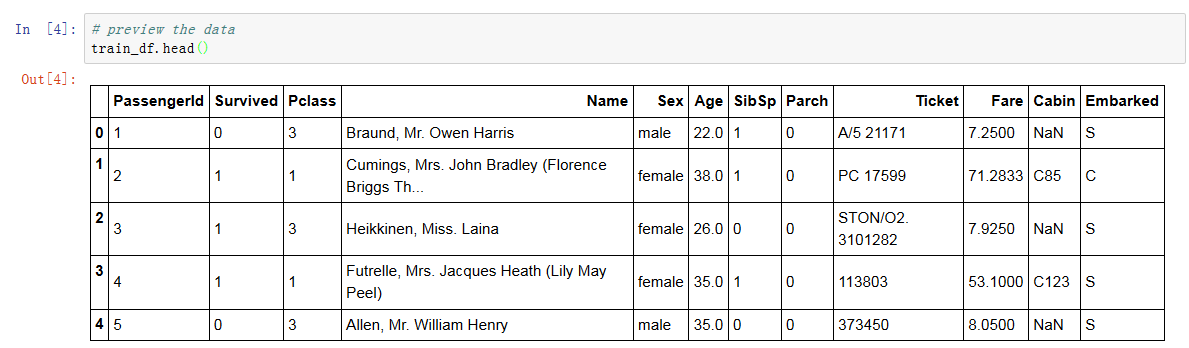
我们从数据头部可以看出:
类别型字段:Survived, Sex, and Embarked. Ordinal: Pclass.
数值型字段:Age, Fare. Discrete: SibSp, Parch.
有些数据集可能有缺失值,或者异常值(直观的那种):
我们看一下最后五行数据:
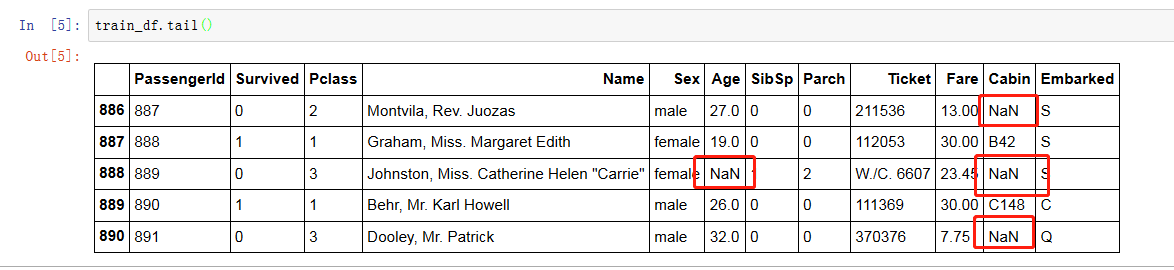
我们接下来看看训练集和测试集数据的信息:
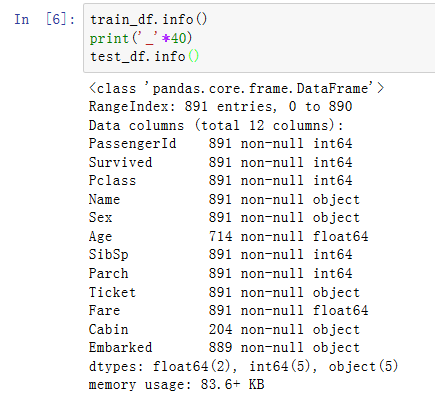
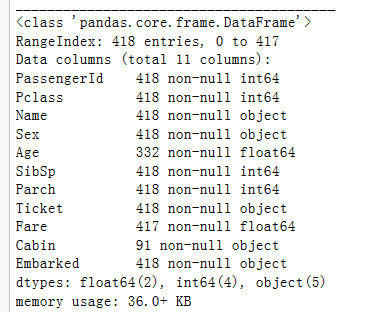
可以看到数据有字符型(object)、整型(int)、浮点型(float)
接下来我们看看数值型数据的描述信息:
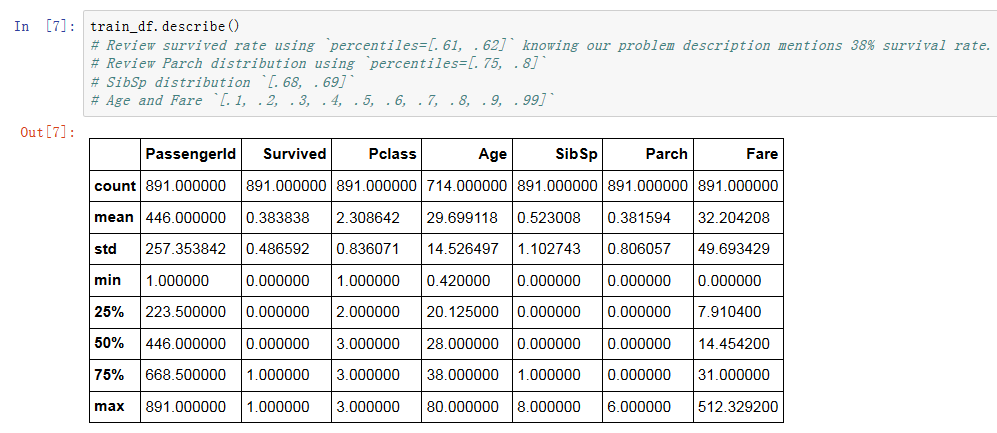
从上面的结果,可以看出:
1. 训练集数据有892名乘客信息
2. 是否存活是用0或者1来区别(0:死亡,1:存活)
3. 训练集中,有38%乘客存活下来
4. 超过75%乘客没有和父母小孩一起乘船
5. 接近30%乘客和堂兄弟/妹一起乘船
6. 票价最高达到了 $512
7. 65-80岁的老人不多
看完了数值型数据的描述,我们看看类别型数据的描述:
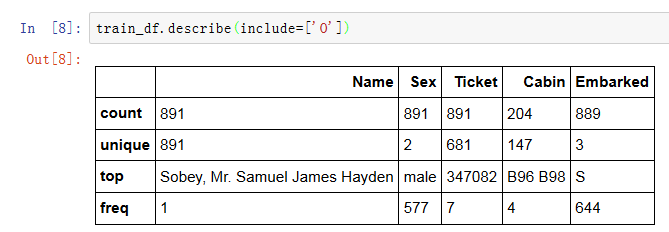
我们可以从上面得出信息:
1. 训练集891名乘客的名字都是各不相同的
2. 891人中有577男性,占比65%
3. 客舱类别很多,有些乘客共享一个客舱
4. 登船港口有三个,其中S港口登船乘客最多
5. 票面特征有很高比率(22%)的重复值(唯一的只有681个)
基于数据分析的假设
我们根据迄今所做的数据探索得出以下假设:
在采取适当行动之前,我们可能会进一步验证这些假设。
关联性假设
1.我们想知道每个特征与生存的关系。
2.我们希望在项目的早期就这样做,并将这些相关性与项目后面的建模相关性进行匹配。
数据完整性假设
1. 我们可能想要完整的年龄特征,因为它肯定与生存相关。
2. 我们可能想要完整的登船港口数据,因为它也可能与生存或另一些重要的特性相关。
数据修正假设
1. 在我们的分析中,票面特征可能会被丢弃,因为它包含了高比率的重复(22%),并且可能不会存在票和生存之间的关系。
2. 在训练和测试数据集中,客舱特征可能会被删除,因为它高度不完整或包含许多空值。
3. 乘客id可以从训练数据集上删除,因为它对生存分析没有帮助。
4. 乘客名字特征是相对不标准的,可能不会直接影响生存,所以可能会丢弃。
创建新特征假设
1. 我们可能想要创建一个新的功能,叫做基于Parch和SibSp的家庭信息,以获得在船上家庭成员的总数。
2. 我们可能希望将名称特征进行提取作为一个新特征。
3. 我们可能想要为年龄层创造新的特征。将一个连续的数字特征变成一个有序的范围特征。
4. 如果它有助于我们的分析,我们可能还想创建一个票价范围的特征。
分类假设
我们还可以根据前面探索的数据描述增加我们的假设。
1. 女性更可能存活。
2. 儿童(年龄小于多少)更可能存活下来。
3. 上层阶级的乘客(Pclass=1)更有可能幸存下来。
有了这些假设,我们继续探索数据:
我们查看计算出每个等级舱位的平均存活率:

我们查看计算了不同性别乘客的平均存活率:

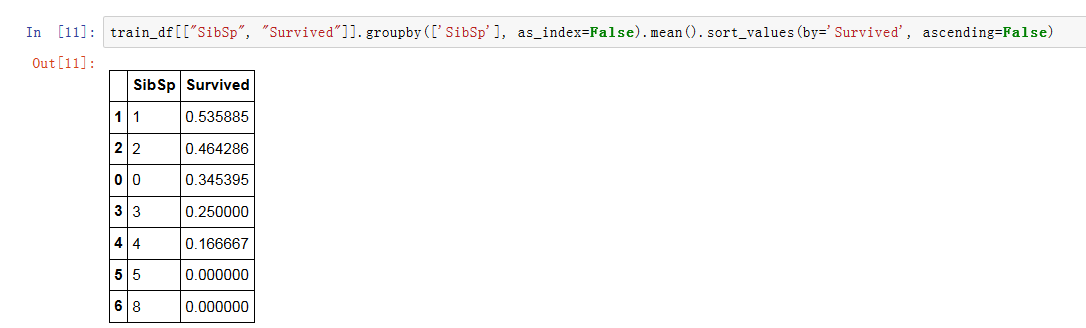
我们查看计算出共同乘船时不同个数堂兄弟/姐妹的乘客存活率:
我们查看计算出和不同父母/孩子一起乘船的乘客生存率:
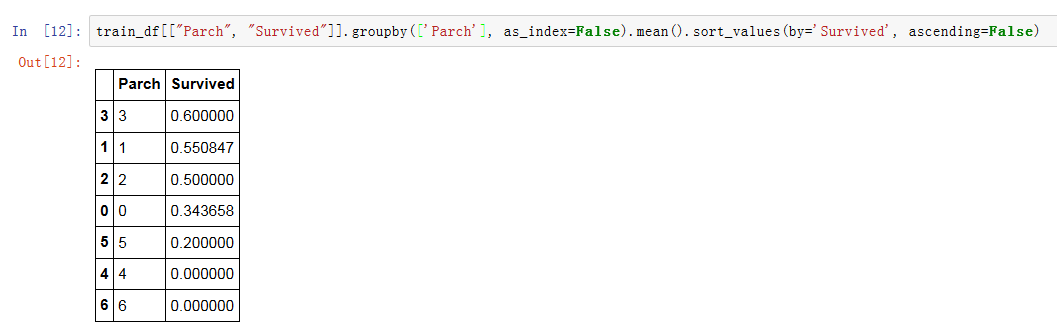
从上面可以得出:
1. Pclass在Pclass=1中观察到显著相关(>0.5),超过50%的人存活 (分类假设3)。我们决定在我们的模型中包含这个特征。
2. 性别对生存影响很大,女性74%都生存下来(分类假设1)
3. SibSp和Parch这些特征对某些值没有相关性。最好从这些特征派生出一个或一组新特征。(创建新特征假设1)
通过可视化进行数据分析
现在我们可以通过可视化分析数据来继续确认我们的一些假设。
相关数值特征
让我们从理解数字特征与我们的解决方案目标(幸存)之间的相关性开始。
直方图对于分析像年龄这样的连续的数值变量是很有用的,因为在这些变量中,条带或范围将有助于识别有用的模式。
直方图可以用自动定义的箱子或相等的范围表示样本的分布。这有助于我们回答有关特定波段的问题(例如:婴儿的存活率更高吗?)
注意,在直方图中,x轴代表了样本或乘客的数量。
我想说,不要羡慕R的可视化,我们Python有seaborn可视化模块!
死亡和生存乘客分别对应的年龄分布:
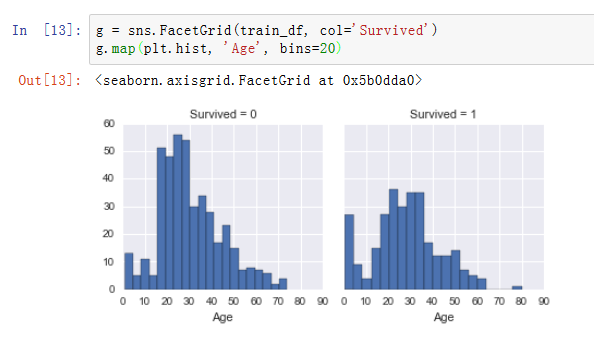
通过上图观察出:
1. 婴儿(年龄<=4)生存率高。
2. 最年长的乘客(年龄= 80)幸存。
3. 大量15-25岁的儿童没有存活。
4. 大多数乘客的年龄在15-35岁之间。
决策:
这个简单的分析确认了一些我们的假设,为后面的工作铺垫好了:
在我们的模型训练中,我们应该考虑年龄(分类假设2)。
我们应该填充年龄特征的空缺值(数据完整性假设1)。
我们应该将年龄分段(创建新特征假设3)。
相关的数字和序数特征
我们可以将多个特征组合起来,用一个单独的图来确定相关性。这可以通过数值和分类特征来完成。
下面这个图展示了不同舱位的生存/死亡乘客年龄和人数分布:

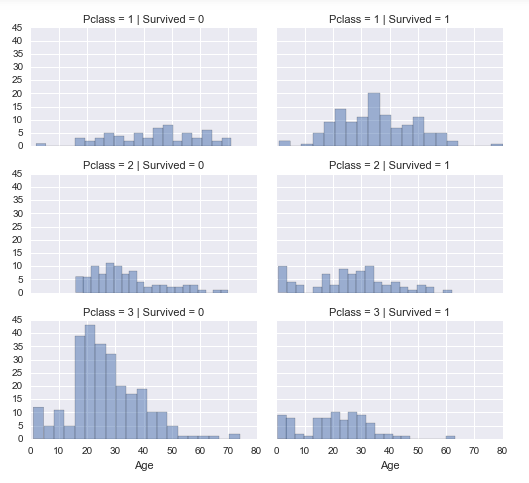
观察上图情况:
1. 大多数乘客都是Pclass=3,但大多数乘客都没有生还。确认我们的分类假设2。
2. Pclass=2和Pclass=3的婴儿乘客大多幸存。进一步证实了我们的分类假设2。
3. Pclass=1中的大多数乘客都幸存了下来。确认我们的分类假设3。
4. Pclass在乘客的年龄分布上有所不同。
决策:
考虑Pclass加入模型训练。
关联分类特征
现在我们可以将分类特征与我们的解决方案目标联系起来。

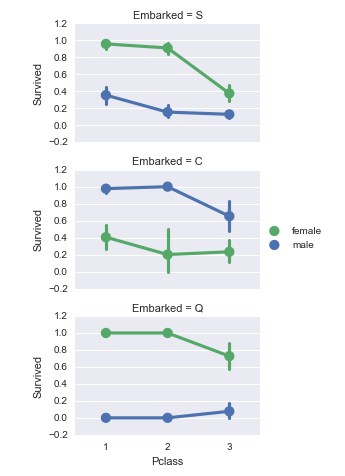
观察出:
1. 女性乘客的生存率比男性高得多。确认分类假设1。
2. 在登船港口为C时,男性的生存率更高。这可能是Pclass与登船港口之间的一种相关性,并导致了Pclass和幸存关系,而不是在登船港口和幸存之间直接相关。
3. 与Pclass=2相比,Pclass=3的Q港口登船男性的生存率更高。(数据完整性假设2)
4. 登船的港口为Pclass=3对男性乘客的生存率有较大的影响,生存率波动较大,(数据修正假设1)。
决策:
将性别特征添加到模型训练中。
添加登船港口特征进入模型训练。
类别特征和数字特征的相关性分析
我们还可能希望将类别特征和数字特征关联起来。
我们可以考虑登船港口特征(类别特征),性别(类别特征),船票费用(数字特征),与是否幸存(数值类别特征)。

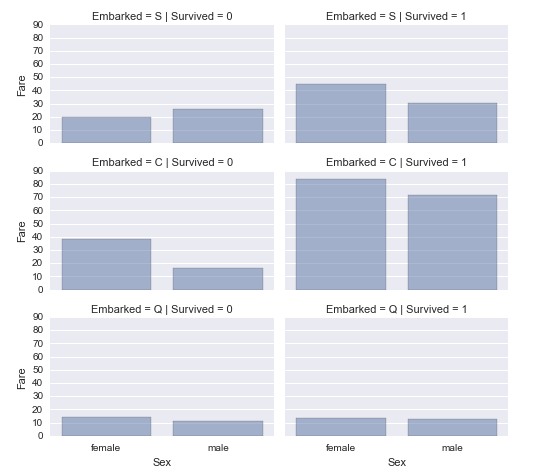
观察出:
1. 支付更高票价的乘客更好的生存。确认我们创建新特征假设4,要新建票价范围特征的假设。
2. 登船港口与存活率有关。确认我们的关联性假设1和数据完整性假设2。
决策:
考虑将船票费用分段创建新特征。
未完待续~




