贷款消费、投资理财已经是当今司空见惯的事情了。针对与商业银行,放贷款已经是其运作中不可或缺的一部分了。但是为了减少信贷危机,并且减少不必要的人力物力,大都采用了一套决策系统。今天呢,我们就一起利用贷款数据去简单地建立一个决策模型。
本文主要涉及到四部分
·读取数据+简单探索
·数据预处理
·描述性分析
·分层抽样
·平衡数据
·建模决策
老样子,先导入后续分析所需要的程序包:
## 加载程序包
library(Rmisc)
library(caret)
library(VIM)
library(DMwR)
## 读取数据+简单探索
LoanData <- read.csv('../input/loan.csv')
head(LoanData)
str(LoanData)
table(LoanData$Loan_Status)
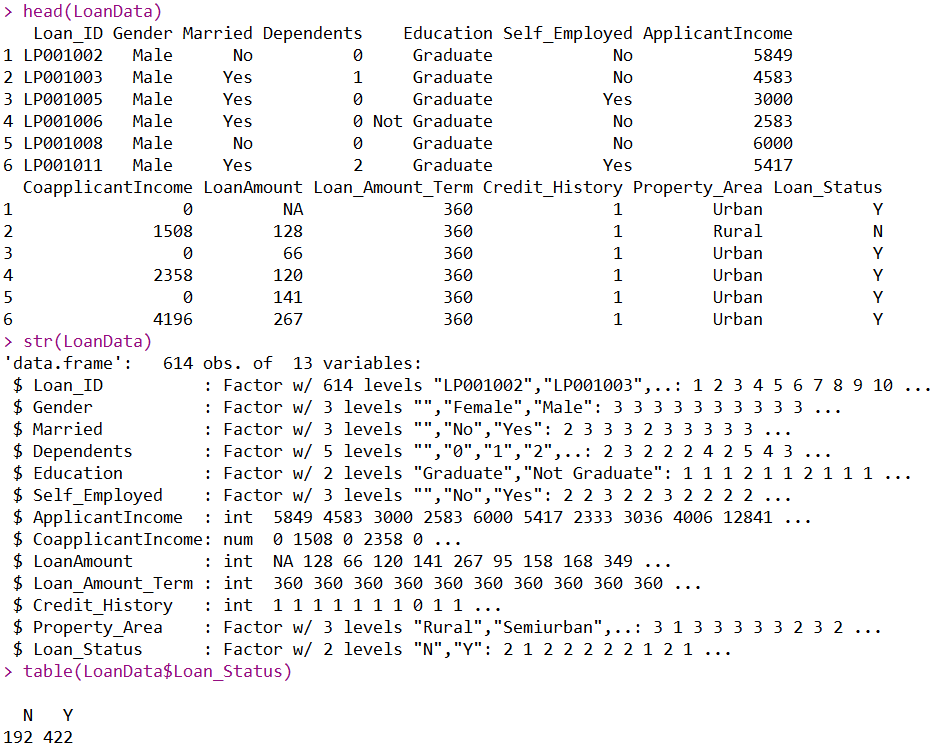
首先head函数返回了数据集的前六行,我们就可以对数据集的整体有一个简单的概念。然后使用str函数返回数据集的简单结构,很容易发现此数据集是数据框类型,包括614行,13列,并且还可以知道各个变量都是什么类型的。table函数返回了两个类别:Y=422,N=192,数据类别有些不平衡。最后就是Loan_ID列是没有用的变量,需要剔除。
细心的观察以上几个因子型的自变量,就会发现有些异常:Gender有三个因子水平、Married有三个因子水平……同时还有缺失值的存在。
## 数据预处理
LoanData <- LoanData[-1]
LoanData$Loan_Amount_Term <- as.factor(LoanData$Loan_Amount_Term)
LoanData$Credit_History <- as.factor(LoanData$Credit_History)
aggr(LoanData, plot = F)
table(LoanData$Loan_Amount_Term)
table(LoanData$Credit_History)
factor_vars <- names(which(sapply(LoanData[-12], class) == "factor"))
factor_tabs <- sapply(LoanData[factor_vars], table)
factor_tabs

使用aggr函数返回数据集中各个变量的缺失情况,发现LoanAmount缺失22个,Loan_Amount_Term缺失14个,Credit_History缺失50个。

上图是提取了所有的因子型变量,然后统计各个因子水平的个数,为了探索各个因子型变量的内容,顺便可以找到对应的最多的因子水平去填充上方的缺失值。
通过对其的探索,发现有一部分变量还有空("")的因子水平,我们均使用最多的因子水平去填补。
LoanData <- within(LoanData, {
Loan_Amount_Term[is.na(Loan_Amount_Term) == T] <- '360'
Credit_History[is.na(Credit_History) == T] <- '1'
Gender[Gender == ''] <- 'Male'
Married[Married == ''] <- 'Yes'
Dependents[Dependents == ''] <- '0'
Self_Employed[Self_Employed == ''] <- 'No'
})
LoanData <- na.omit(LoanData)
使用within函数对数据进行重塑,方便快速地填充缺失值和空的因子水平。然后LoanAmount变量并没有进行缺失值的填补,因为其缺失数量也不多,其次其不如因子型变量填补方便,再此我就发懒直接剔除了。
## 描述性分析
gp_stack <-
lapply(factor_vars[1:8], function(x) {
ggplot(LoanData, aes(x = eval(parse(text = x)), fill = Loan_Status)) +
geom_bar() +
xlab(x) +
theme_bw() +
ggtitle(paste(x, "Barplot Stack", sep= " ")) +
theme(plot.title = element_text(hjust = 0.5)) +
guides(fill = 'none')
})
gp_fill <-
lapply(factor_vars[1:8], function(x) {
ggplot(LoanData, aes(x = eval(parse(text = x)), fill = Loan_Status)) +
geom_bar(position = 'fill') +
xlab(x) +
theme_bw() +
ggtitle(paste(x, "Barplot Fill", sep= " ")) +
theme(plot.title = element_text(hjust = 0.5))
})
multiplot(plotlist = c(gp_stack[1:4], gp_fill[1:4]), cols = 2)
multiplot(plotlist = c(gp_stack[5:8], gp_fill[5:8]), cols = 2)
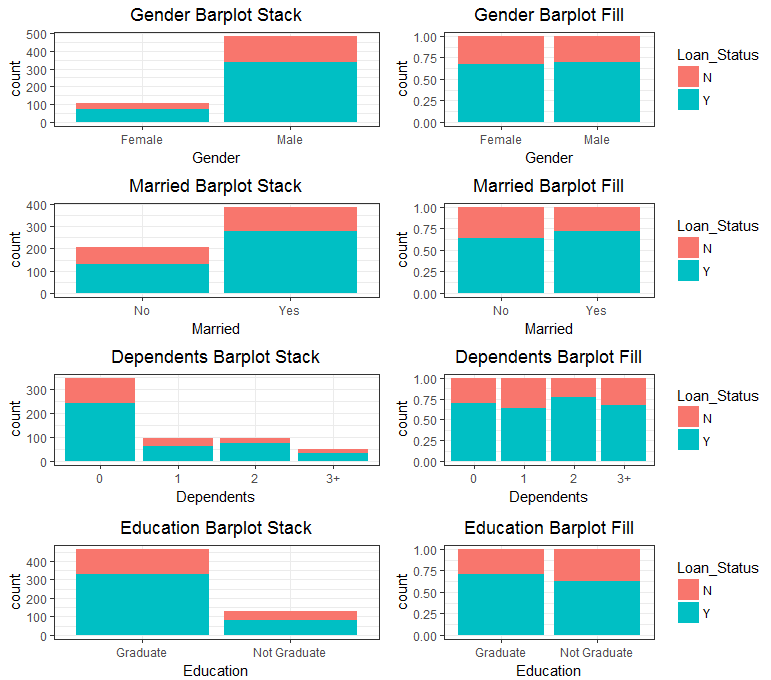
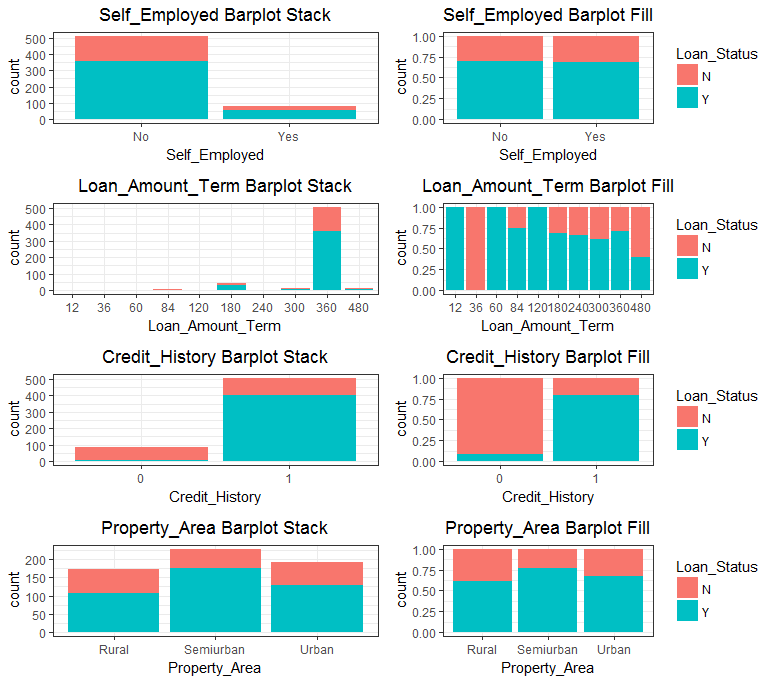
通过绘制8个因子型变量与因变量的条形图,发现除了Credit_History变量有比较明显的区分性(也可能受到了样本量不足的影响),其他均不明显。
## 分层抽样
set.seed(1)
idx <- createDataPartition(LoanData$Loan_Status, p = 0.8, list = F)
TrainData <- LoanData[idx, ]
TestData <- LoanData[-idx, ]
## 交叉验证+随机森林
ctrl <- trainControl(method = "cv", number = 5, selectionFunction = 'oneSE')
set.seed(1)
model_rf <- train(x = TrainData[-12],
y = TrainData[, 12],
method = 'rf',
trControl = ctrl)
pred_rf <- predict(model_rf, TestData[-12])
confusionMatrix(pred_rf, TestData[, 12])
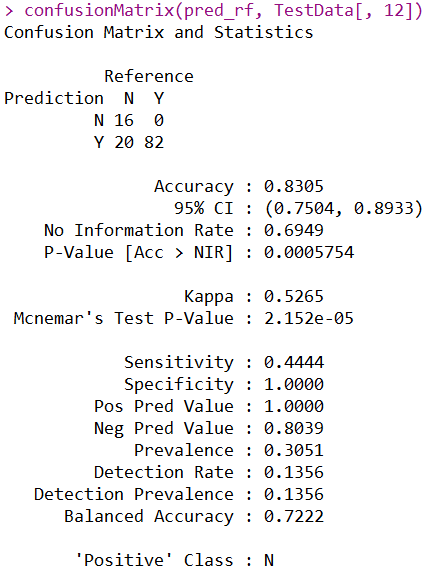
使用训练集建立随机森林模型,然后建立混淆矩阵发现整体精度为83.05%,看起来还挺高,但是这是由于数据不平衡导致的,整体的精度不适合评估此模型。并且模型的Kappa值也只有0.5265,Sensitivity才0.4444,都说明此时的模型不可取。下面进行平衡数据,然后在使用随机森林模型尝试对比一下:
## 平衡数据
set.seed(3)
LoanData2 <- SMOTE(form = Loan_Status ~ .,
data = LoanData,
perc.over = 200,
perc.under = 150)
numeric_vars <- names(which(sapply(LoanData2[-12], class) == "numeric"))
LoanData2[numeric_vars] <- sapply(LoanData2[numeric_vars], round)
table(LoanData2$Loan_Status)
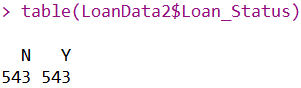
平衡后的数据类别之比为1:1,均为543个样本。
## 分层抽样
set.seed(1)
idx <- createDataPartition(LoanData2$Loan_Status, p = 0.7, list = F)
TrainData <- LoanData2[idx, ]
TestData <- LoanData2[-idx, ]
## 交叉验证+随机森林
set.seed(1)
model_rf <- train(x = TrainData[-12],
y = TrainData[, 12],
method = 'rf',
trControl = ctrl2)
pred_rf <- predict(model_rf, TestData[-12])
confusionMatrix(pred_rf, TestData[, 12])
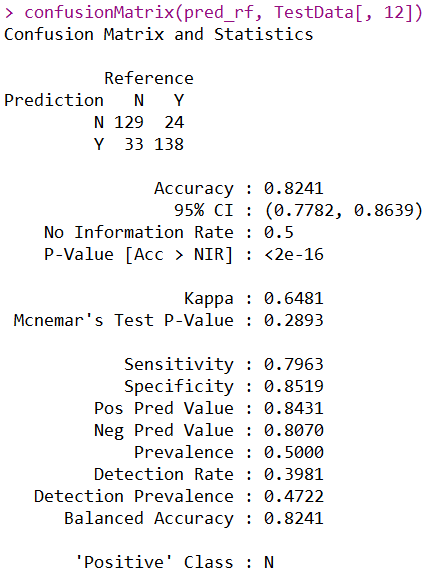
平衡数据之后,模型Sensitivity将近80%,Kappa值达到了0.6481,都比之前有了一定的提升。
注:本案例不提供数据集,如果要学习完整案例,点击文章底部阅读原文或者扫描课程二维码,购买包含数据集+代码+PPT的《kaggle十大案例精讲课程》,购买学员会赠送文章的数据集。
《kaggle十大案例精讲课程》提供代码+数据集+详细代码注释+老师讲解PPT!综合性的提高你的数据能力,数据处理+数据可视化+建模一气呵成!



