1、读取文件转换时间问题parse_date
Pandas读取文件read_csv或read_table时,我们会希望把某些以整型存储的数据转换成时间格式,例如txt文件:
1 19970101 1 11.77
2 19970112 1 12.00
3 19970112 2 77.00
我们想把第2列以如下格式导入:
1 1997-01-01 1 11.77
2 1997-01-12 1 12.00
3 1997-01-12 2 77.00
秦老师在课程中提到,有两个参数:parse_dates和date_parser可以做到。
但是我在练习时却遇到问题:
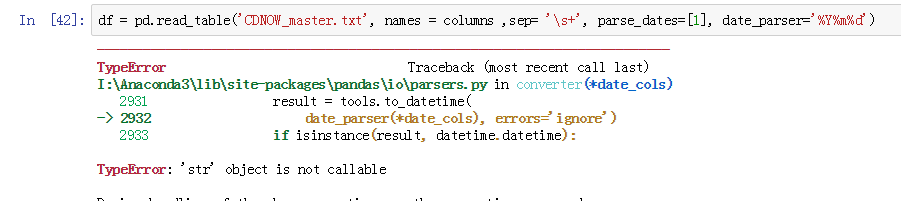
没打错啊,为什么有问题呢,我决定深入了解一下这两个参数
翻看官方文档,parse_dates
顺便学一下英语:

翻译成中文就是:需要解析的日期

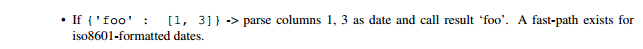
参数Parse_dates可以是布尔型、整型列表或者包含列名的列表、字典。缺省为False。
如果参数为True,说明需要把索引解析为时间格式列;
如果参数为[1,2,3],说明需要把1/2/3列分别解析为时间格式列;
如果参数为[[1,3]],说明需要把1/3列合起来,一起解析为单个时间格式列。
如果参数为{‘foo’:[1,3]},说明需要把1/3列合起来,称合并列为’foo’,一起解析为单个时间格式列。
在我们的例子中,可以用[‘order_dt’],也可以用[1],这个参数没错的。
接着看Date_parser:
翻译成中文就是:日期分析程序

参数date_parser必须为函数,缺省为None。
这样就懂了,原来date_parser参数中需要填写的是一个函数,因此我们可以先构造一个匿名函数:
parse = lambda x:datetime.strptime(x,'%Y%m%d')
也许有比我更小白的同学不了解匿名函数,可以看廖雪峰大大对匿名函数的介绍:
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431843456408652233b88b424613aa8ec2fe032fd85a000
说白了就是构建一个函数,使每一个整数经过这个函数都能转换成’%Y%m%d’的日期格式。
把parse函数填入date_parser,运行,发现阔以啦~
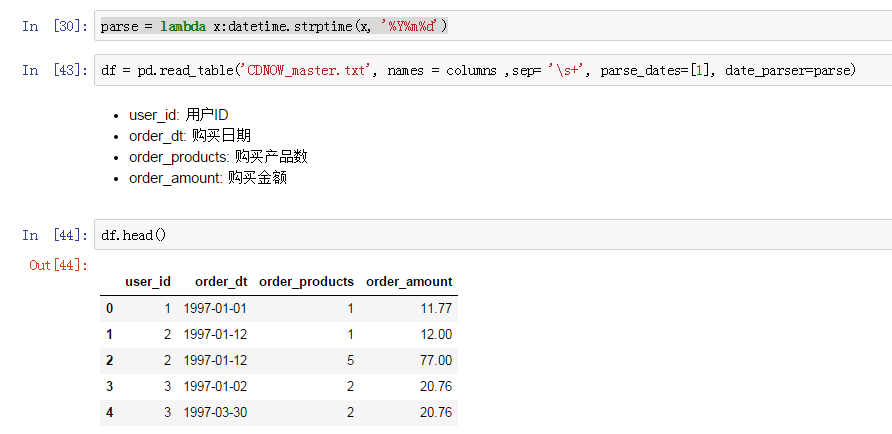
问题解决,开心!
2、练习2作业
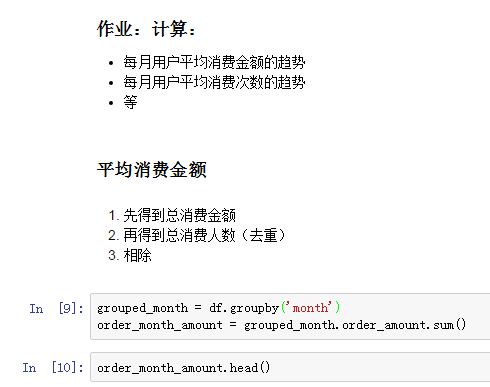
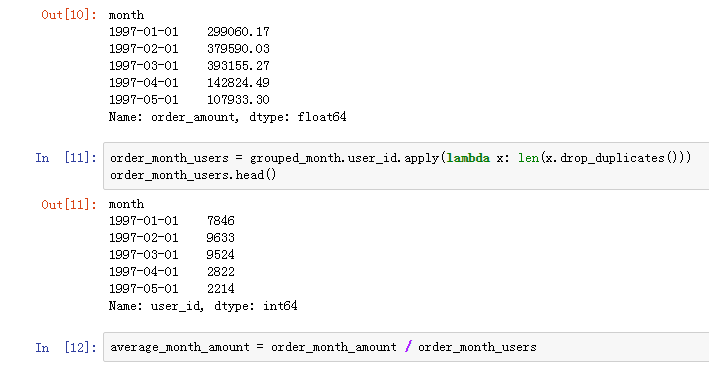
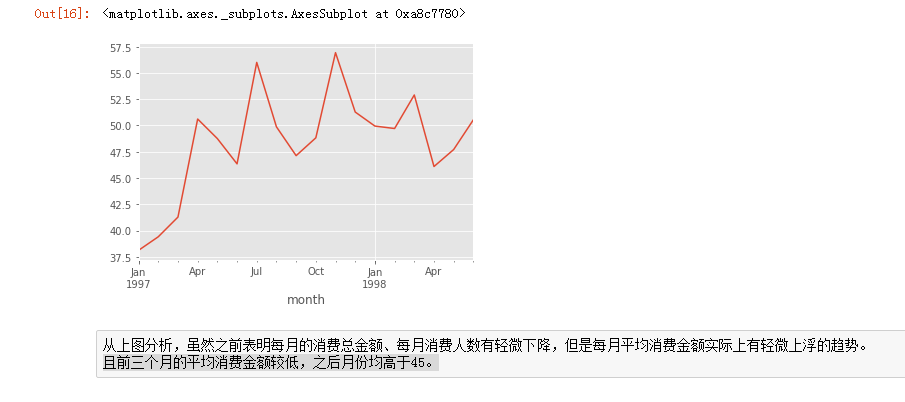

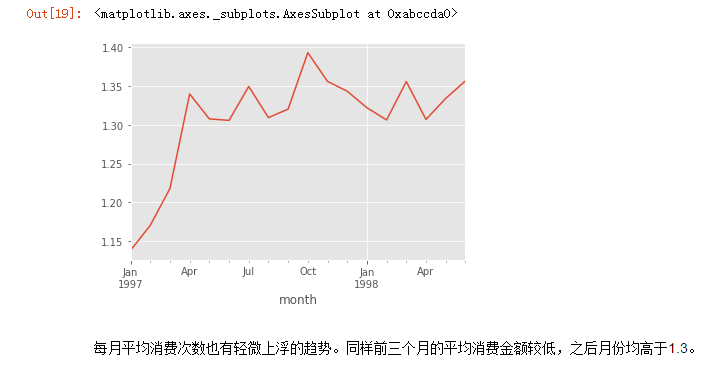
练习原码:

