
上一期我们对泰坦尼克数据进行了部分预处理和可视化探索,这一期继续我们的可视化探索和建模预测。
这一期文章主要包括了部分可视化探索、交叉验证、建模预测和模型评估。
## 可视化探索
## Fare VS Survived
p_Fare1 <-
alldata %>%
.[!is.na(.$Survived), ] %>%
ggplot(aes(x = Fare)) +
geom_histogram(fill = '#63B8FF') +
guides(fill = 'none') +
labs(title = '(a)') +
theme_bw()
p_Fare2 <-
alldata %>%
.[!is.na(.$Survived), ] %>%
ggplot(aes(x = Fare, fill = Survived)) +
geom_histogram(position = 'identity', alpha = 0.6) +
labs(title = '(b)') +
theme_bw()
multiplot(p_Fare1, p_Fare2, cols = 2)
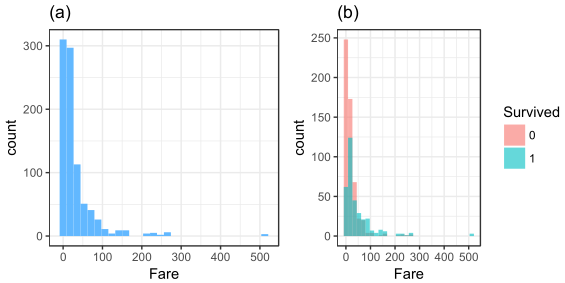
根据直方图(a)可以得出费用的分布情况,持有100以下的票价的人员最多,还有很多的免费票;从图(b)中呈现一个趋势:票价高的人员幸存率普遍较高。
## Embarked VS Survived
table(alldata$Embarked)
alldata$Embarked[is.na(alldata$Embarked)] <- 'S'
p_Em1 <-
alldata %>%
.[!is.na(.$Survived), ] %>%
ggplot(aes(x = Embarked, fill = Survived)) +
geom_bar() +
guides(fill = 'none') +
labs(title = '(a)') +
theme_bw()
p_Em2 <-
alldata %>%
.[!is.na(.$Survived), ] %>%
ggplot(aes(x = Embarked, fill = Survived)) +
geom_bar(position = 'fill') +
labs(title = '(b)') +
theme_bw()
multiplot(p_Em1, p_Em2, cols = 2)
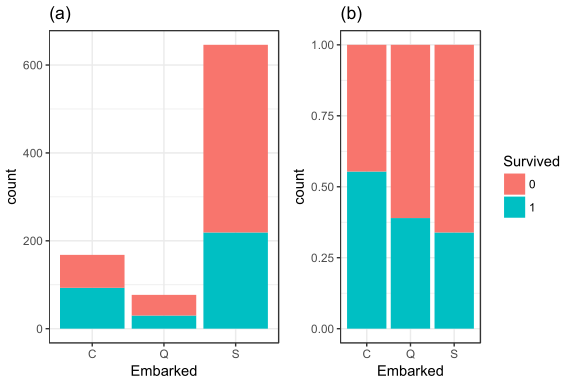
Embarked中还有两个缺失值,我们用众数来填补这两个缺失值。之后绘制图(a)和(b),通过图(b)可以发现不同港口登船的人员幸存率也有所差异。
## Name VS Survevid
alldata$Title <- sapply(alldata$Name,
function(x) {strsplit(x, split='[,.]')[[1]][2]})
alldata$Title <- sub(' ', '', alldata$Title)
alldata <- within(alldata, {
Title[!Title %in% c('Master', 'Miss', 'Mr', 'Mrs')] <- 'Rare Title'
Title[Title %in% c('Mlle', 'Ms')] <- 'Miss'
Title[Title == 'Mme'] <- 'Mrs'
})
alldata$Title <- as.factor(alldata$Title)
p_Title1 <-
alldata %>%
.[!is.na(.$Survived), ] %>%
ggplot(aes(x = Title, fill = Survived)) +
geom_bar() +
guides(fill = 'none') +
labs(title = '(a)') +
theme_bw()
p_Title2 <-
alldata %>%
.[!is.na(.$Survived), ] %>%
ggplot(aes(x = Title, fill = Survived)) +
geom_bar(position = 'fill') +
labs(title = '(b)') +
theme_bw()
multiplot(p_Title1, p_Title2, cols = 2)
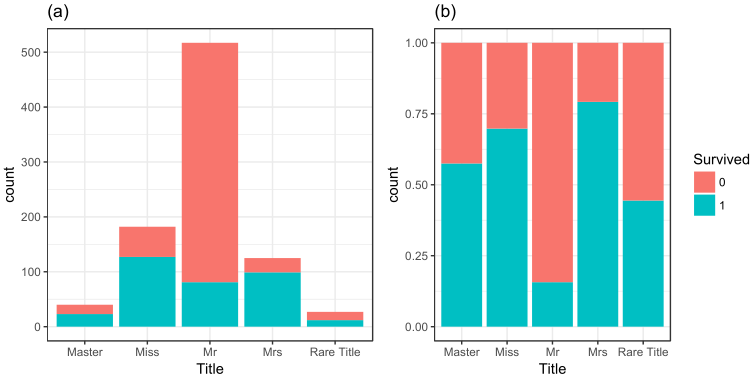
国外的姓名和我国的有一定的差距,我们提取出Mr、Miss之类的称呼作为一个变量,绘制百分比堆积柱状图可以发现不同Title的幸存率还是有所差距的。
## 划分训练集和测试集+读取测试集结果
## 建模预测
train_model <-
alldata %>%
.[!is.na(.$Survived), ] %>%
dplyr::select(Survived, PclassSex, Title, AgeGroup, FamilySize2)
test_model <-
alldata %>%
.[is.na(.$Survived), ] %>%
dplyr::select(PclassSex, Title, AgeGroup, FamilySize2)
results <- read.csv("../input/gender_submission.csv")
results$Survived <- as.factor(results$Survived)
## 建模预测+模型评估
ctrl <- trainControl(method = 'cv', number = 5, selectionFunction = 'oneSE')
set.seed(3)
model_JRip <- train(Survived ~., train_model, method = 'JRip', trControl = ctrl)
pred_JRip <- predict(model_JRip, test_model)
confusionMatrix(pred_JRip, results$Survived)
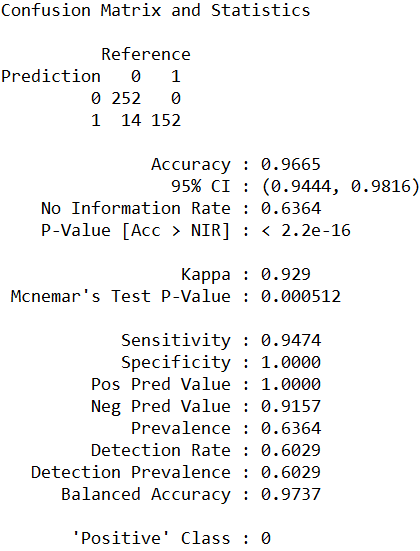
建立多规则学习分类器对测试集进行预测,然后建立混淆矩阵。此分类器的整体正确率达到了96.65%,在418个测试集中仅仅把14个未幸存的人员预测为了幸存人员;Kappa值也达到了0.929,说明模型具有很好的一致性,随机性很小。
set.seed(3)
model_nb <- train(Survived ~., train_model, method = 'nb', trControl = ctrl)
pred_nb <- predict(model_nb, test_model)
confusionMatrix(pred_nb, results$Survived)

建立朴素贝叶斯分类器对测试集进行预测,然后建立混淆矩阵。此分类器的整体正确率达到了98.80%,在418个测试集中仅仅把5个未幸存的人员预测为了幸存人员;Kappa值也达到了0.9743,说明模型具有很好的一致性,随机性很小,比多规则学习分类器有一点提高。
set.seed(3)
model_rf <- train(Survived ~., train_model, method = 'rf', trControl = ctrl)
pred_rf <- predict(model_rf, test_model)
confusionMatrix(pred_rf, results$Survived)
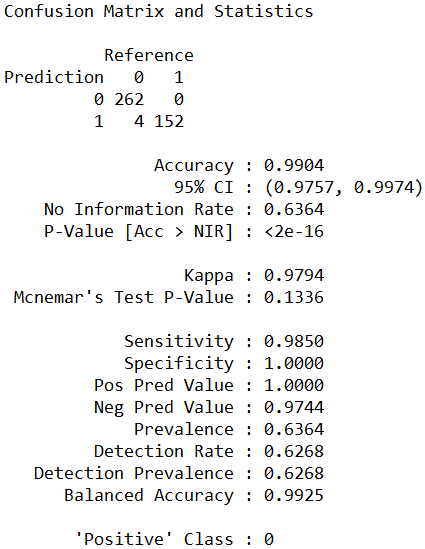
建立随机森林分类器对测试集进行预测,然后建立混淆矩阵。此分类器的整体正确率达到了99.04%,在418个测试集中仅仅把4个未幸存的人员预测为了幸存人员;Kappa值也达到了0.9794,说明模型具有很好的一致性,随机性很小,比朴素贝叶斯分类器有一点点提高。
三个模型从整体而言都是不错的,随机森林模型虽然在争取率和一致性上表现最佳,但是其复杂度比较高;朴素贝叶斯分类器在此的争取率仅次于随机森林,但是复杂度较低。
我们只选择了4个变量进行建模预测,大家可以去多尝试各种变量的组合去建模预测,看看哪种组合有更好的表现。
有兴趣的读者还可以尝试塑造更多有意义的变量去进行尝试建模。现在的模型已经有很不错的表现了,懒懒的我就不做过多尝试了。
注:本案例不提供数据集,如果要学习完整案例,点击文章底部阅读原文或者扫描课程二维码,购买包含数据集+代码+PPT的《kaggle十大案例精讲课程》,购买学员会赠送文章的数据集。

