在R中经常会用到一些循环,对于数据量较小的数据,我们使用for循环之类的显循环也没发现什么弊端,但是针对数据量较大的数据,依旧使用显循环,就会发现R中的显循环效率真低!!!那么,今天我们针对apply家族,去总结和对比向量计算和显循环计算。
# apply
apply(X, MARGIN, FUN, ...)
X:数组、矩阵、数据框
MARGIN:即按行或列计算(1:行, 2:列)
FUN:自定义函数
dat_matrix <- matrix(1:1000000, ncol = 10) # 构建一个矩阵
head(dat_matrix) # 查看矩阵的前六行
## for循环对每行求和,并计时
result <- c() # 构建空向量去存储计算结果
## 对运行计时
system.time(for(i in 1:100000) {
a <- sum(dat_matrix[i, ])
result <- append(result, a)
})
head(result) # 展示前六个计算结果
## apply函数进行向量化计算,并计时
system.time(apply(dat_matrix, 1, sum))
head(apply(dat_matrix, 1, sum))

通过上方两个时间的对比,显而易见。使用for循环对我们的矩阵进行逐行求和使用的时间大约是apply向量化计算的80倍左右,可以说是纯粹浪费时间,并且还不如apply的代码简洁易懂。下面举例说明一下如何使用apply函数对数据框的某部分进行标准化操作。
## 对鸢尾花数据框的前三列进行标准化处理
head(iris)
iris[1:3] <- apply(iris[1:3], 2, scale)
head(iris)
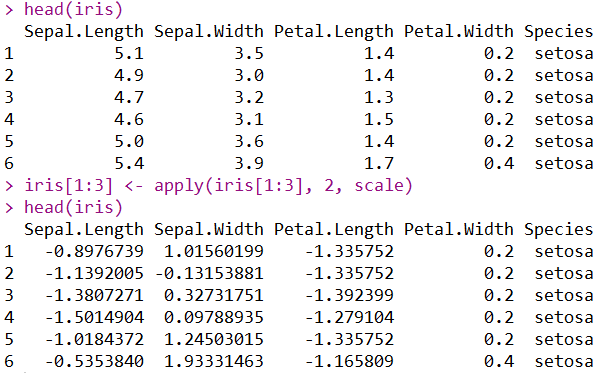
在这里,大家需要注意的是:如果既需要处理后的数据,有需要未处理的部分数据,那么对哪一部分进行处理,就要把处理后的数据赋值到原数据的那一部分,否则还得重新合并数据,造成不必要的麻烦。
## lapply
lapply(X, FUN, ...)
X:向量、列表、数组、矩阵、数据框
FUN:自定义函数
## 计算向量中每个元素的长度
dat_vec <- c('tian', 'shan', 'zhienng')
lapply(dat_vec, nchar)
## 对列表的每个元素进行求和
dat_list <- list(a = 1:5, b = 2:6)
lapply(dat_list, sum)
## 对矩阵的每个值进行求和
dat_matrix <- matrix(1:4, 2)
lapply(dat_matrix, sum)
## 对数据框的每列进行求和
dat_df <- as.data.frame(dat_matrix)
lapply(dat_df, sum)
as.data.frame(lapply(dat_df, sum))
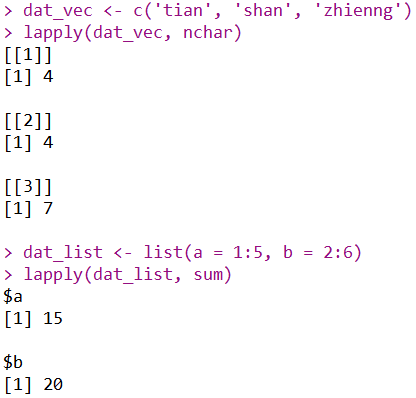

从上面几个例子可以看出,lapply返回的均是list,如果我们需要其他类型的数据,需要进行对应的函数转换。
## sapply
sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE)
X:向量、列表、数组、矩阵、数据框
FUN:自定义函数
simplify:自定义返回类型(矩阵、列表和数组)
USE.NAME:是否返回名称
## 计算向量中每个元素的长度
sapply(dat_vec, nchar)
sapply(dat_vec, nchar, USE.NAMES = F)
sapply(dat_list, scale) # 标准化列表的元素
sapply(dat_matrix, sum) # 对矩阵的每个值进行求和
sapply(dat_df, sum) # 对数据框的每列进行求和
# 对数据框的某一列标准化
head(sapply(iris[4], scale, simplify = T))
class(sapply(iris[4], scale, simplify = T))
class(sapply(iris[4], scale, simplify = F))
class(sapply(iris[4], scale, simplify = "array"))
head(sapply(iris[4], scale, simplify = "array"))

从上面可以看出,sapply最大的不同就是返回的数据类型不同,其次就是多了两个参数。
上面标准化某列时,如果simplify的取值是T,则返回矩阵;如果是F,则返回列表;如果是“array”,则返回数组。
参数USE.NAME只对与X为向量时起作用,控制是否返回名称。
## vapply
vapply(X, FUN, FUN.VALUE, ..., USE.NAMES = TRUE)
X:向量、列表、数组、数据框
FUN:自定义函数
FUN.VALUE:设置行索引
USE.NAMES:是否返回名称
## 计算向量中字符串的长度
vapply(dat_vec, nchar, FUN.VALUE = c('a' = 0), USE.NAMES = F)
class(vapply(dat_vec, nchar, FUN.VALUE = c('a' = 0)))
## 对列进行标准化
vapply(dat_list, scale, FUN.VALUE = c('a'=0,'b'=0,'c'=0,'d'=0,'e'=0))
class(vapply(dat_list, scale, FUN.VALUE = c('a'=0,'b'=0,'c'=0,'d'=0,'e'=0)))
## 对数据框进行标准化
vapply(as.data.frame(dat_matrix), scale, FUN.VALUE = c('a'=0, 'b'=0))
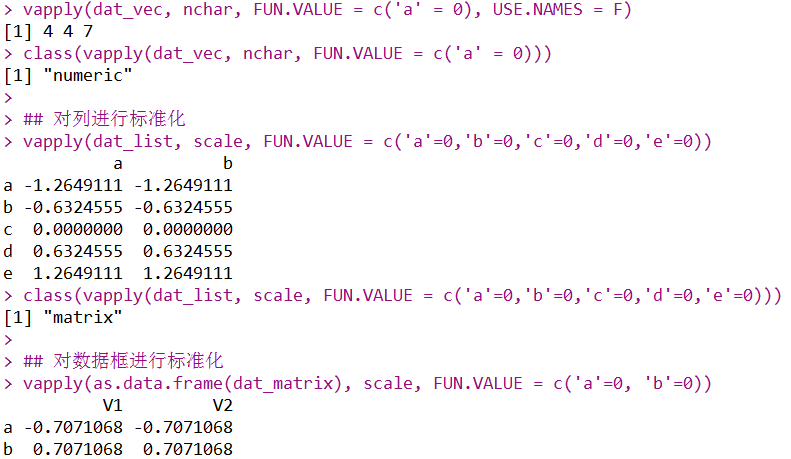
用vapply函数与sapply函数的主要区别就是可以控制行名。当然,我们可以自己利用rownames函数另外设置行名。
## mapply
mapply(FUN, ..., MoreArgs = NULL, SIMPLIFY = TRUE, USE.NAMES = TRUE)
FUN:自定义函数
...:FUN的参数
MoreAges:函数的其他参数列表
SIMPLIFY:自定义返回类型(矩阵、列表和数组)
USE.NAMES:是否返回名称
## 将x中的数值依次重复两次
mapply(rep, x = 1:4, each = 2)
## 计算字符串的长度,然后与第三个参数相乘
mapply(function(x, y) {nchar(x)*y},
c('wu', 'shu', 'hao'),
c(1:3))

## tapply
tapply(X, INDEX, FUN = NULL, ..., simplify = TRUE)
X:向量
INDEX: 通常是种类
FUN: 自定义函数
…:FUN的参数
simplify : 自定义返回类型(矩阵、列表和数组)
dat_df <- data.frame(x1 = 1:10, x2 = 2:11, type = rep(c('a', 'b')))
tapply(dat_df$x1, dat_df$type, mean) # 统计不同type的x1的均值
## 构建数据框---成绩统计
dat_df2 <- data.frame(class = sample(1:3, 100, replace = T),
gender = sample(c('f', 'm'), 100, replace = T),
score = sample(60:95, 100, replace = T))
head(dat_df2)
# 统计不同班级、不同性别的学生的平均分
tapply(dat_df2$score, INDEX = list(dat_df2$class, dat_df2$gender), mean)
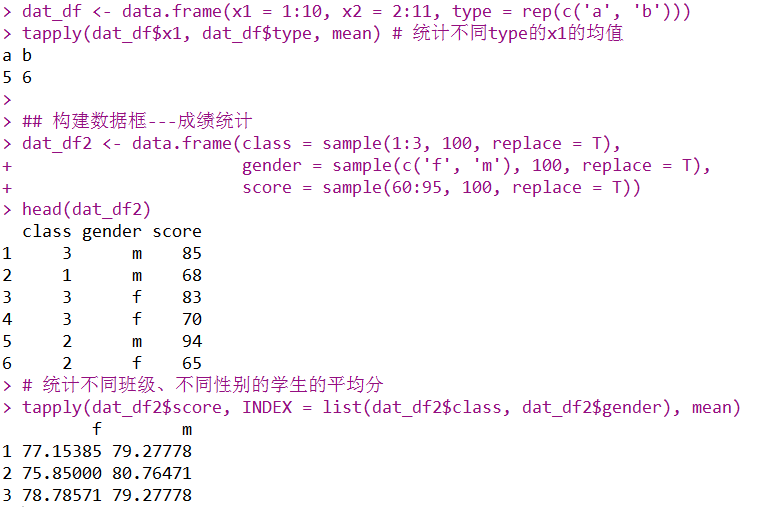
tapply有一个很特殊的作用,就是分组统计,相当于我们dplyr包里面的group_by。
关于apply家族的讲解就到这里了,总而言之呢,他们都不算完美,相对于孰优孰劣来说,不如是优劣互补!还有几个apply家族的函数,但是几乎用不到他们,所以我就不浪费大家的时间去讲解不常用的函数了。


