第一数据类型
1、三引号作用
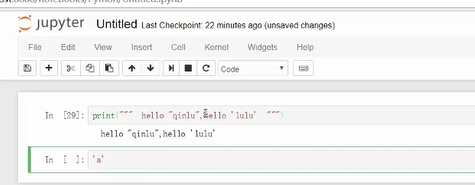
2、标示单双引号,引号号前加/来标示这个引号是需要输出的
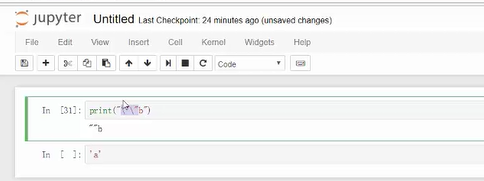
3、第三种类型:浮点串:
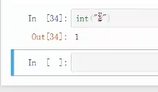
注意:字符串不能相加减,需要用int(“1”)进行转换成数值格式:
4、数据类型四:布尔(bool)--- TRUE FALSE,可加减乘除,默认为(0和1)
ps: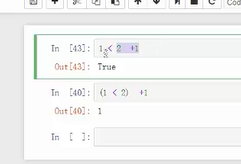 -----计算顺序:先加减在判断
-----计算顺序:先加减在判断
4.None,
不能加减乘除法
None表示缺失,“”表示空
第二部分:变量
目的:数据之间运算需反复用到某一个值(数据/字符串),那么就引入了变量
做法:a=1 就是给a赋值,下次使用a就代表1;
a,b=1,2 分别赋值
注意事项:a=a+1表示先做右边计算再赋值,顺序要清楚;
第三课:数据结构
列表、字典、元组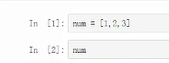
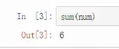 表示列表中的元素求和
表示列表中的元素求和
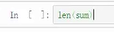 和
和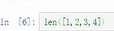 都表示计算列表的元素个数
都表示计算列表的元素个数
访问列表中的元素---索引/切片---第一个位置是0---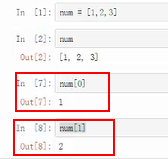
如果列表元素特别多时候;num[-1]表示组最后一个元素;
如果抽取一段范围的-num[0:1]表示取第一个第二个元素;num[:2]num[1:],
列表中新增:num insert(1,4)表示在第二位置前插入4;num append(7)表示在列表最后插入一个7;如果想在最后添加多个元素必须用赋值的方法num=num+[7,8,9]
列表删除:num pop(1) 把在索引位置1的元素删除掉,pop中不写参数时就删除最后一位的元素;
列表更改:num[3]=4 把第四位的改为4;
b=[[1,2],[3,4]]
ps:对函数不熟悉可shift+table调取帮助
第三列表:
第四字典:
第五控制流循环
第六函数
第七第三方包
1、pandas读取数据:
import pandas as pd
date=pd.read_csv('C:\dataAnalyst_sql.csv')
1、默认读取utf8格式---查看编码方式:记事本打开,另存为时下面会显示编码方式,如若不是utf8,则另存一下
2、read_csv函数后加上路径C:\XXXX.csv
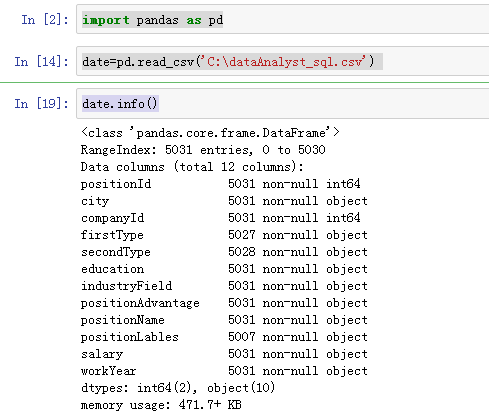
date.info()-----经行数据概览,查看数据类型
date.head()----head()查看前默认5条数据;date.tail()----tail()查看尾部数据
astype('str')----date.city=date.city.astype('str')---astype('str')更改数据类型,需再次赋值才能完成更改
date[['A','B','C']]----date[['city','salary']].head()---date[['A','B','C']]显示ABC这三个字段,前五个
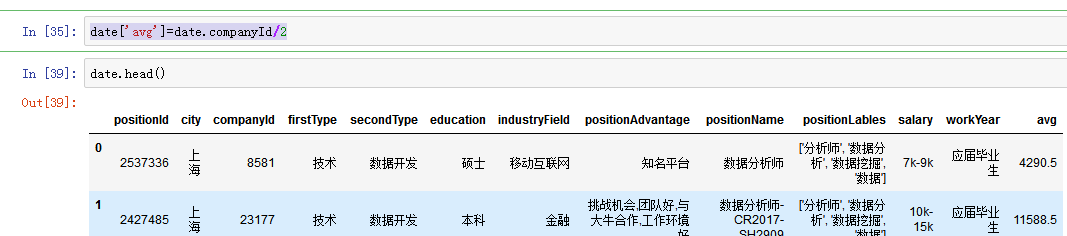
date['avg']=date.companyId/2-----计算并增加一列。如下图
date.query('avg>70000').city----查找avg大于70000的城市--------date.query('avg>70000')[['city','education']].head()--查找avg大于70000的城市教育并显示前5条
彩色文字注意如下图情况,不能再次索引,以为再次索引时候里面只有两千多个数据组成的数组无法填充与df所构成的五千多个数据的数据框
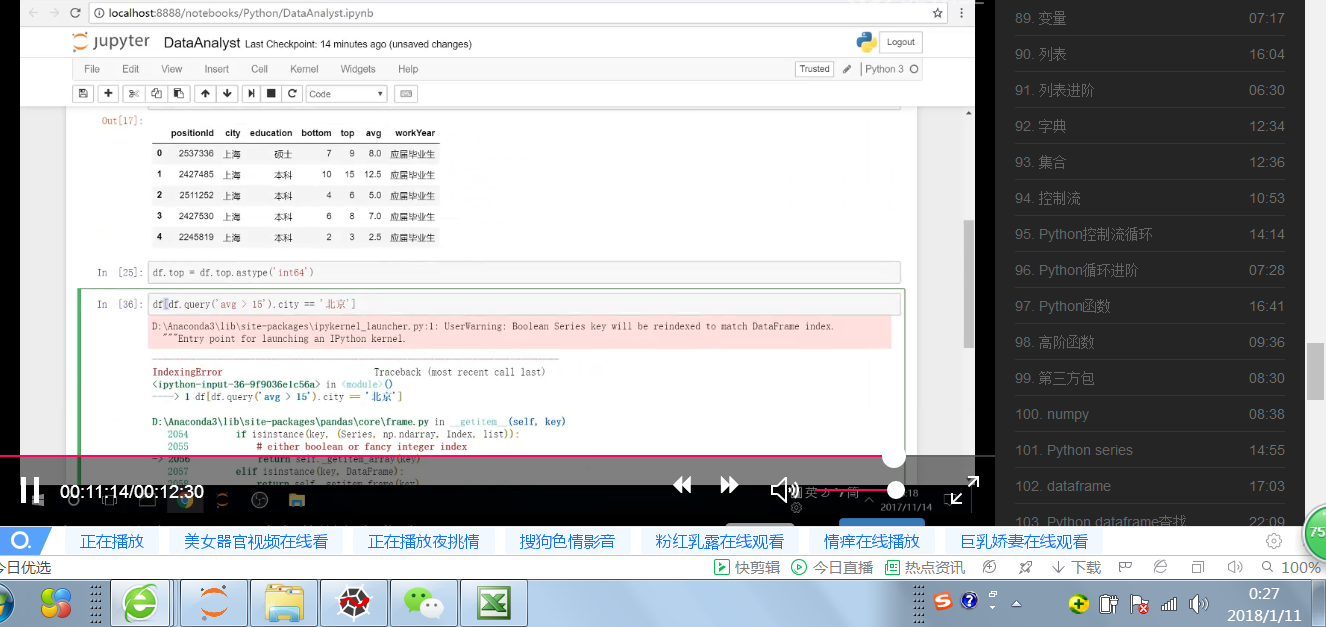
df[(df.city=='上海')&(da.avg>15)]--此种写法可行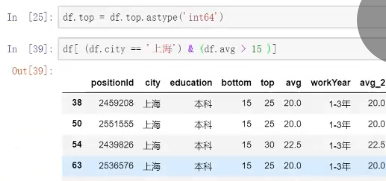
2、计算、筛选:
date.T----行列转置
排序---两种写法:date.sort_values();date.sort_index()
1、参数不要-------date.sort_values(by='排序字段'其中by可以省略),ascending=False(默认顺序,倒序False))
date.sort_values(['avg','city'],ascending=False)----对两个字段经行排序
 数据框格式date.sort_values(by='avg')或者date.sort_values('avg')
数据框格式date.sort_values(by='avg')或者date.sort_values('avg')
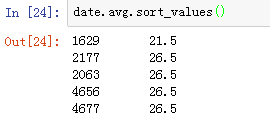 数组格式date.avg.sort_values
数组格式date.avg.sort_values

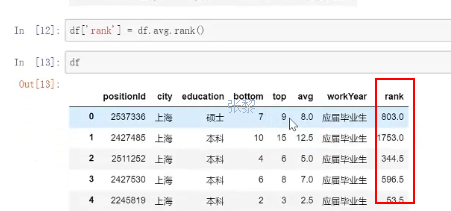

2、参数method------
date['rank']=date.avg.rank()----对排名加上赋值列---date['rank']=date.avg.rank(ascending=False)
method---正常按照平均值,method='max'表示名次都为最后一个的位次,method='min'表示名次是第一个位次;method='frist'表示按照遇到的顺序标名次;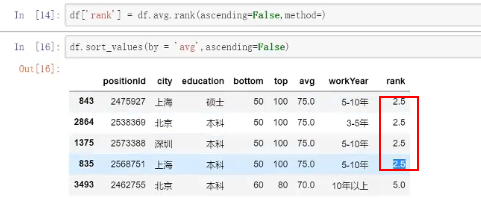
3、寻找重复类目---unique函数,valu_count()函数
类别---
类别+计数------
date.describe()---date.city.describe()-----描述统计函数
类似的date.count();date.sum();date.max()
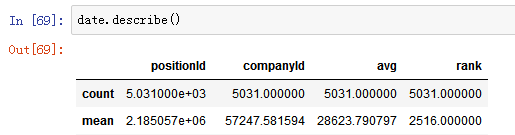
总结:新手拿到数据用这三个函数查看数据(info-heda-describe)
累加计算----cumsum()函数
分段---pands的cut()函数--应用于用户分级,消费水平分割,ifm模型
date['bins']=pd.cut(date.avg,bins=[0,5000,10000,20000,])----bins最后一位空着那么大于20000的数都显示NA
date['bins']=pd.cut(date.avg,bins=[0,5000,10000,20000,10000000] ,labels=['0-5000','5000-10000','10000-20000','20000-10000000'])
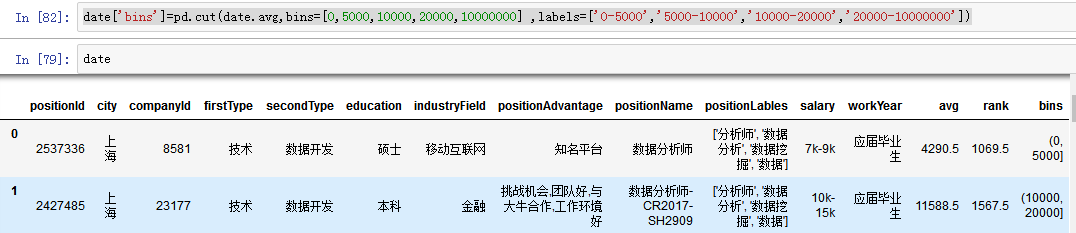
另外一种分段:pandas的qcut()--q相当于bins,labels,rebins开区间闭区间,percosion精度,uplicates是否操作去重;

4、聚合:group by
date.groupby(by='city')
date.groupby(by='city').count()
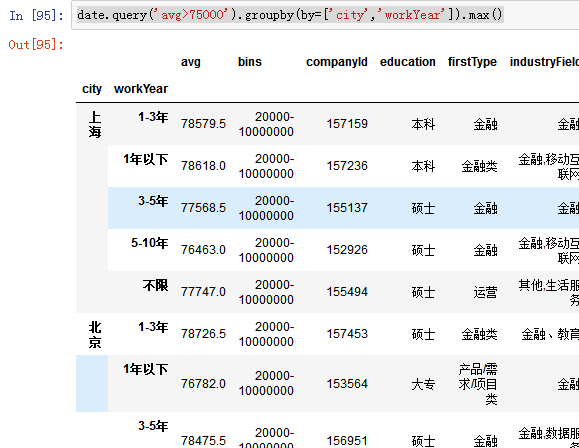
多条件--date.query('avg>75000').groupby(by=['city','workYear']).max()--avg大于75000的部分按照city和workYear进行聚合,取最大值
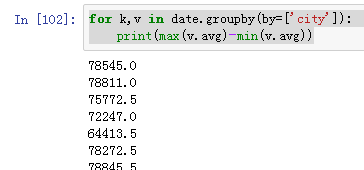
对聚合后函数计算---例如对聚合后函数求最大最小值的差值
for k,v in date.groupby(by=['city']):
print(max(v.avg)-min(v.avg))
5、pandas多表关联
merge()函数

company.merge(right=data,how='inner',on='compayid')----另一种写法pd.merge(company,data,how='inner',on='compayid')----左表company,右表data,用'compayid'连接

如果on的字段不同名,则使用参数left_on='XXX' ,right_on='XXX' ;
jion---- ----基于索引拼接编号1跟编号1放在一起
----基于索引拼接编号1跟编号1放在一起
pd.concat([company,position])-----直接上下堆叠,相同字段回合并成一列。
pd.concat([company,position],axis=1)-----直接左右堆叠
6、多重索引:
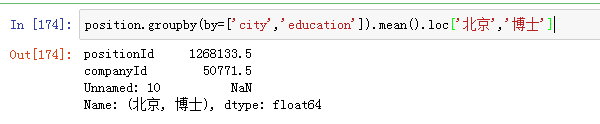
position.groupby(by=['city','education']).mean()---由于这个是数据框结构不能直接调取字段-----position.groupby(by=['city','education']).mean().loc['北京','博士']


7、清洗函数:
1、文本清洗:str
position.positionLables.str[1:-1]-----调用str针对单元格内文本,去方括号;
position.positionLables.str[1:-1].str.replace("'","")----再次调用str的替换函数吧单引号替换
2、空值:
更改为空值:position.loc[position.city=='上海','city']=np.NAN---一般更改为numpy中的NAN
空值填充:position.fillna(1)------把空值填充为1;position.fillna(‘abc’)-------把空值填充为abv
position.city=position.city.fillna(1)-----把city列的空值填充为1
position.dropna()------把含有空值的行删除
3、检查重复值:
duplicated()&drop_duplicates():

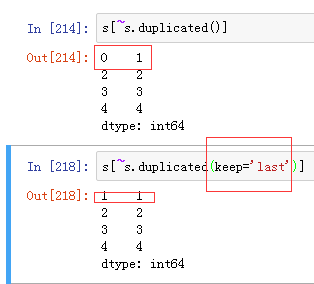 ----参数keep='last'是指重复值的时候保留最后一个值。
----参数keep='last'是指重复值的时候保留最后一个值。
XXX.drop_duplicates()-------删除重复行
8、pandas.apply:
应用灵活,与自定义函数结合
把一个函数应用到所有的行和列中,优点:速度快
例如: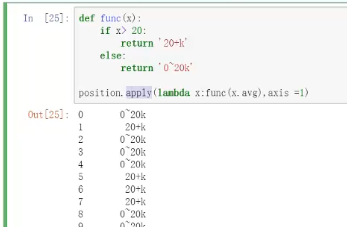
9、pandas数据透视:
pivot_table()
values=[]
Signature: position.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')Signature: position.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
eg1:position.pivot_table(index=['city','education'],columns='workYear',values='avg')

eg2:position.pivot_table(index=['身份'],values=['人数'],aggfunc=[np.mean,np.sum])------参数aggfunc表示透视值的展示方式(平均值等)
position.pivot_table(index=['身份'],values=['人数'],aggfunc=[np.mean,np.sum])['sum'].loc['上海']----对透视表做筛选,注意对行筛选用.loc['']
可以对不同的值字段选不同值方式:pptv.pivot_table(index=['身份'],values=['人数','岗位'],aggfunc={'人数':np.mean,'岗位':np.sum})
补充函数:reset_index()-----重置索引字段
to_csv()----------导出csv


