前段时间爬取拉勾网职位信息有几大问题:
1、代码太复杂
2、爬取数据一段时间后得到职位的城市就会变成上海
3、不能够添加搜索的关键词
在此重新改变下代码,添加了搜索的关键词,同时在拉勾网最多只能爬取30页,也就是450个职位。
第一步:分析搜索得到的网址,例如在搜索框输入网易视觉设计,城市选择全国,得到拉勾网的网址:https://www.lagou.com/jobs/list_网易视觉设计?px=default&city=全国#filterBox,按F12(火狐浏览器),发现输入关键词都在参数—表单数据中,如图:
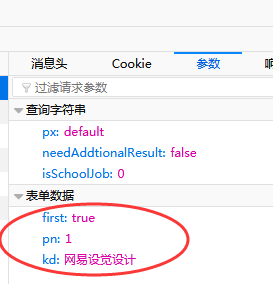
参考网上别的大神的网址构造,得到连接:url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false'.format(city)
站在别人肩膀上的确比较轻松,这样就可以爬取网页信息了,具体代码如下:
import csv
import json
import requests
import pandas as pd
import time
#获取json数据
def get_json_data(city,position,page):
#请求拉勾的职位查询接口,返回的是json格式数据
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false'.format(city)
data = {'first':'false',
'pn':page,
'kd':position}
headers = {'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0',
'Cookie':'你的cookie',
'Referer':'https://www.lagou.com/jobs/list_%E7%BD%91%E6%98%93%E8%A7%86%E8%A7%89%E8%AE%BE%E8%AE%A1?city=%E4%B8%8A%E6%B5%B7&cl=false&fromSearch=true&labelWords=&suginput='}
response = requests.post(url,headers=headers,data=data)
return response.text
if __name__ == '__main__':
info=[]
data1=[]
for page in range(0,31):
frist_data=get_json_data('全国','网易设觉设计',page)
second_data=json.loads(frist_data)
for n in range(15):
for i in second_data['content']['positionResult']['result'][n]:
info.append(second_data['content']['positionResult']['result'][n][i])
for i in range(int(len(info)/43)):
index=info[43*i:43*i+43]
data1.append(index)
time.sleep(1)
data=pd.DataFrame(data1)
data
每页的数据都是15个职位信息,每个职位有43条信息(很多都是空),在代码中加入自己的cookie就可以爬取拉勾网相关信息,后续把数据传入pandas,然后自己进行数据整理和清洗,再进行数据分析就OK了,之前分析过一次,就不在此赘述了

